python 详解正则表达式的使用(re模块)
一,什么是正则表达式
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
构造正则表达式的方法和创建数学表达式的方法一样。也就是用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式。正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为"元字符")组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
二,常用的正则匹配工具
在线匹配工具:
1 http://www.regexpal.com/
2 http://rubular.com/
正则匹配软件
McTracer (https://pan.baidu.com/s/19Yn49)
用过几个之后还是觉得这个是最好用的,支持将正则导成对应的语言如java C# js等还帮你转义了,Copy直接用就行了很方便,另外支持把正则表达式用法解释,如哪一段是捕获分组,哪段是贪婪匹配等等,总之用起来非常好。
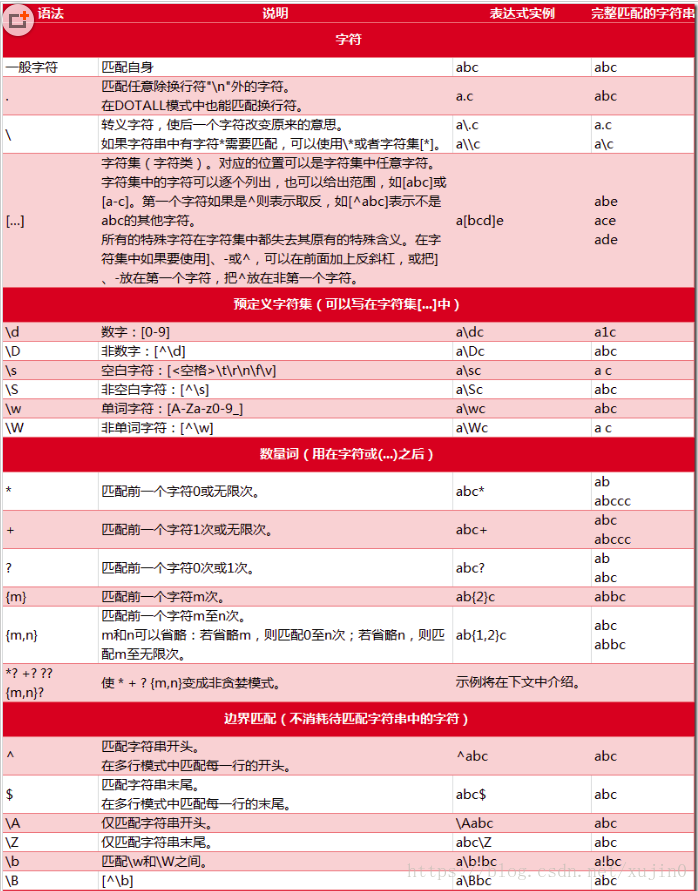
三,正则字符介绍
3.1普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符,这就包括了所有大写和小写字母,所有数字,所有标点符合和一些其他字符。
| 字符 | 描述 |
| "^" | :^会匹配行或者字符串的起始位置,有时还会匹配整个文档的起始位置。 |
| "$" | $会匹配行或字符串的结尾 |
| "\b" | 不会消耗任何字符只匹配一个位置,常用于匹配单词边界 如 我想从字符串中"This is Regex"匹配单独的单词 "is" 正则就要写成 "\bis\b" |
| "\d" |
匹配数字,例如要匹配一个固定格式的电话号码以0开头前4位后7位,如0737-5686123 正则:^0\d\d\d-\d\d\d\d\d\d\d$ |
| "\w" |
匹配字母,数字,下划线.例如我要匹配"a2345BCD__TTz" 正则:"\w+" 这里的"+"字符为一个量词指重复的次数 |
| "\s" |
匹配空格 例如字符 "a b c" 正则:"\w\s\w\s\w" 一个字符后跟一个空格,如有字符间有多个空格直接把"\s" 写成 "\s+" 让空格重复 |
| "." | 匹配除了换行符以外的任何字符 |
| "[abc]" |
字符组 匹配包含括号内元素的字符 这个比较简单了只匹配括号内存在的字符,还可以写成[a-z]匹配a至z的所以字母就等于可以用来控制只能输入英文了 |
3.2非打印字符
非打印字符也可以是正则表达式的组成部分,下表列出了非打印字符的转义序列:
| 字符 | |
| \cx | 匹配由x指明的控制字符,例如,\cm匹配一个Control-M或回车符。x死亡值必须为A~Z或者a~z之一,否则c被视为一个原意的"c"字符 |
| \f | 匹配一个换页符,等价于\x0c和\cL |
| \n | 匹配一个换行符,等价于\x0a和\cJ |
| \r | 匹配一个回车符,等价于\x0d和\cM |
| \s | 匹配任何空白字符,包括空格,制表符,换页符等等,等价于[\f\n\r\t\v] |
| \S | 匹配任何非空字符,等价于[^\f\n\r\t\v] |
| \t | 匹配一个制表符,等价于\x09和\cl |
| \v | 匹配一个垂直制表符。等价于\x0b和\cK |
3.3特殊字符
特殊字符就是一些有特殊含义的字符,简单的说就是表示任何字符串的意思。如果要查找字符串的*符号,则需要对*进行转义,即在前面加上一个\。
许多元字符要求在试图匹配他们时特别对待,若是要匹配这些特殊字符,必须首先使字符转义,即将反斜杠\放在他们前面。下表列出了正则表达式中的特殊字符。
| 特别字符 | 描述 |
| $ | 匹配输入字符串的结尾位置.要匹配 $ 字符本身,请使用 \$。 |
| () | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 \[。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\\' 匹配 "\",而 '\(' 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,此时它表示不接受该字符集合。要匹配 ^ 字符本身,请使用 \^。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 \{。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 \|。 |
3.4限定符(懒惰限定符)
限定符用来指正则表达式的一个给定组件必须要出现多少次才能满足匹配,有*或+或?或{n}或{n,}或{n,m}六种。
| 字符 | 描述 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 、 "does" 中的 "does" 、 "doxy" 中的 "do" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
3.5反义字符
写法很简单,就是字符改为大写就行了,意思和原来相反。
| 字符 | 描述 |
| \W | 匹配任何不是字母数字,下划线的字符 |
| \S | 匹配任何不是空白符的字符 |
| \D | 匹配任何非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^abc] | 匹配除了abc以外的任意字符 |
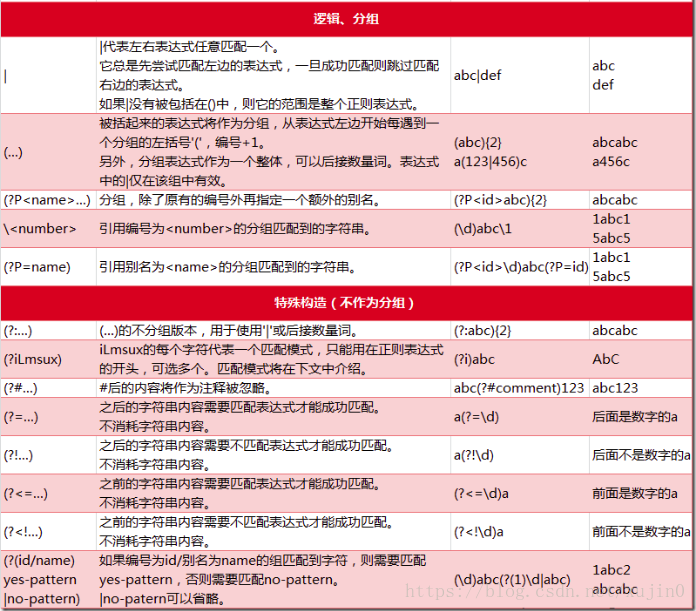
四,正则捕获
先了解在正则中捕获分组的概念,其实就是一个括号内的内容 如 "(\d)\d" 而"(\d)" 这就是一个捕获分组,可以对捕获分组进行 后向引用 (如果后而有相同的内容则可以直接引用前面定义的捕获组,以简化表达式) 如(\d)\d\1 这里的"\1"就是对"(\d)"的后向引用
那捕获分组有什么用呢看个例子就知道了
如 "zery zery" 正则 \b(\w+)\b\s\1\b 所以这里的"\1"所捕获到的字符也是 与(\w+)一样的"zery",为了让组名更有意义,组名是可以自定义名字的
"\b(?<name>\w+)\b\s\k<name>\b" 用"?<name>"就可以自定义组名了而要后向引用组时要记得写成 "\k<name>";自定义组名后,捕获组中匹配到的值就会保存在定义的组名里
下面列出捕获分组常有的用法
| 字符 | 描述 |
| (exp) | 匹配exp,并捕获文本到自动命名的组里 |
| (?<name>exp) | 匹配exp,并捕获文本到名称为name的组里 |
| (?:exp) | 匹配exp,不捕获匹配的文本,也不给此分组分配组号 |
| (?=exp) |
匹配exp前面的位置 如 "How are you doing" 正则"(?<txt>.+(?=ing))" 这里取ing前所有的字符,并定义了一个捕获分组名字为 "txt" 而"txt"这个组里的值为"How are you do"; |
| (?<=exp) |
匹配exp后面的位置 如 "How are you doing" 正则"(?<txt>(?<=How).+)" 这里取"How"之后所有的字符,并定义了一个捕获分组名字为 "txt" 而"txt"这个组里的值为" are you doing"; |
| (?!exp) |
匹配后面跟的不是exp的位置 如 "123abc" 正则 "\d{3}(?!\d)"匹配3位数字后非数字的结果 |
| (?<!exp) |
匹配前面不是exp的位置 如 "abc123 " 正则 "(?<![0-9])123" 匹配"123"前面是非数字的结果也可写成"(?!<\d)123" |
五,常见的正则表达式总结
非负整数:^\d+$ 正整数:^[0-9]*[1-9][0-9]*$ 非正整数:^((-\d+)|(0+))$ 负整数:^-[0-9]*[1-9][0-9]*$ 整数:^-?\d+$ 非负浮点数:^\d+(\.\d+)?$ 正浮点数 : ^((0-9)+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)$ 非正浮点数:^((-\d+\.\d+)?)|(0+(\.0+)?))$ 负浮点数:^(-((正浮点数正则式)))$ 英文字符串:^[A-Za-z]+$ 英文大写串:^[A-Z]+$ 英文小写串:^[a-z]+$ 英文字符数字串:^[A-Za-z0-9]+$ 英数字加下划线串:^\w+$ E-mail地址:^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$ URL:^[a-zA-Z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\s*)?$
或:^http:\/\/[A-Za-z0-9]+\.[A-Za-z0-9]+[\/=\?%\-&_~`@[\]\':+!]*([^<>\"\"])*$ 邮政编码:^[1-9]\d{5}$ 中文:^[\u0391-\uFFE5]+$ 电话号码:^((\(\d{2,3}\))|(\d{3}\-))?(\(0\d{2,3}\)|0\d{2,3}-)?[1-9]\d{6,7}(\-\d{1,4})?$ 手机号码:^((\(\d{2,3}\))|(\d{3}\-))?13\d{9}$ 双字节字符(包括汉字在内):^\x00-\xff 匹配首尾空格:(^\s*)|(\s*$)(像vbscript那样的trim函数) 匹配HTML标记:<(.*)>.*<\/\1>|<(.*) \/> 匹配空行:\n[\s| ]*\r 提取信息中的网络链接:(h|H)(r|R)(e|E)(f|F) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)? 提取信息中的邮件地址:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)* 提取信息中的图片链接:(s|S)(r|R)(c|C) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)? 提取信息中的IP地址:(\d+)\.(\d+)\.(\d+)\.(\d+) 提取信息中的中国手机号码:(86)*0*13\d{9} 提取信息中的中国固定电话号码:(\(\d{3,4}\)|\d{3,4}-|\s)?\d{8} 提取信息中的中国电话号码(包括移动和固定电话):(\(\d{3,4}\)|\d{3,4}-|\s)?\d{7,14} 提取信息中的中国邮政编码:[1-9]{1}(\d+){5} 提取信息中的浮点数(即小数):(-?\d*)\.?\d+ 提取信息中的任何数字 :(-?\d*)(\.\d+)? IP:(\d+)\.(\d+)\.(\d+)\.(\d+) 电话区号:/^0\d{2,3}$/ 腾讯QQ号:^[1-9]*[1-9][0-9]*$ 帐号(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$ 中文、英文、数字及下划线:^[\u4e00-\u9fa5_a-zA-Z0-9]+$ 匹配中文字符的正则表达式: [\u4e00-\u9fa5] 匹配双字节字符(包括汉字在内):[^\x00-\xff] 匹配空行的正则表达式:\n[\s| ]*\r 匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/ sql语句:^(select|drop|delete|create|update|insert).*$ 匹配首尾空格的正则表达式:(^\s*)|(\s*$) 匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
5.1总结常用的正则表达式(表格形式)
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符m次
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c '\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t' '(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})
(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city")
结果{'province': '3714', 'city': '81', 'birthday': '1993'}
5.2 最常用的匹配语法
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.splitall 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
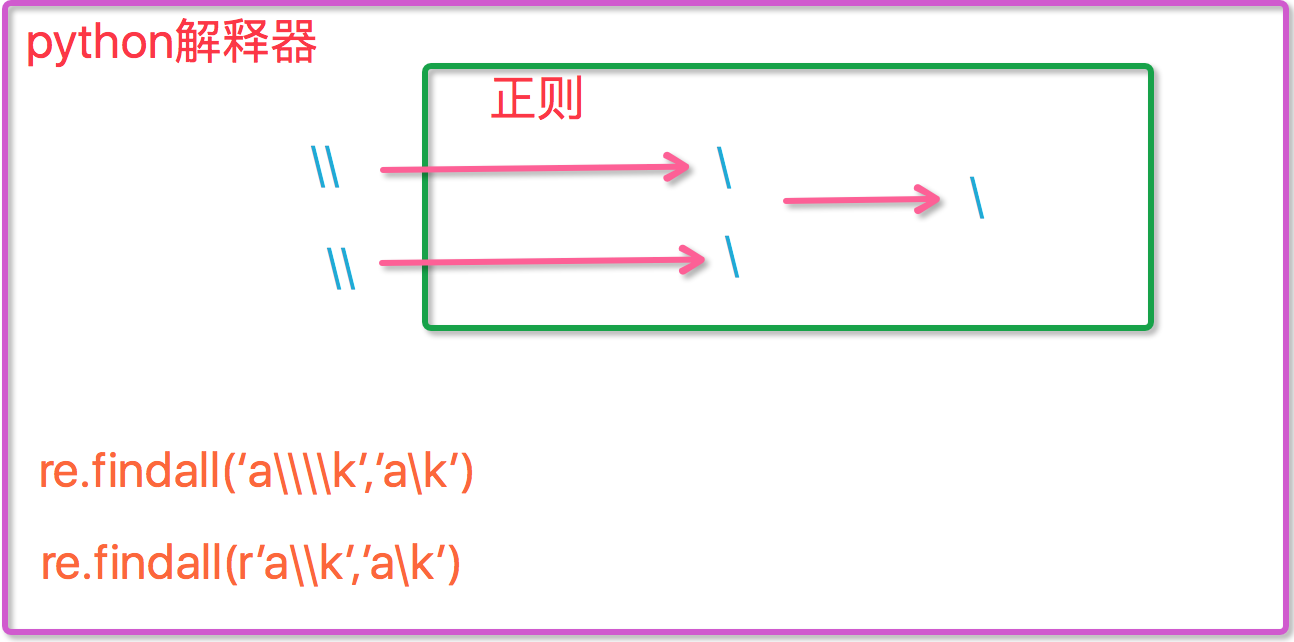
问题:反斜杠的困扰
与大多数编程语言相同,正则表达式里面使用“ \ ”作为转义字符,这就可能造成反斜杠困扰,假如你需要匹配文本中的字符'' \ '' 那么使用编程语言表示的正则表达式里面将需要4个反斜杠"\\\\",前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里面转义成一个反斜杠,python里的原生字符串很好的解决了这个问题,这个例子中的正则表达式可以使用 r"\\ 表示。同样,匹配一个数字的"\\d"可以写成r"\d.有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
仅仅需要知道及格匹配模式
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
S(DOTALL): 点任意匹配模式,改变'.'的行为
六,re模块
就本质而言,正则表达式是一种小型的,高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
字符匹配(普通字符和元字符)
1 普通字符:大多数字符和字母都会和自身匹配
>>> re.findall('alvin','yuanaleSxalexwupeiqi')
['alvin'] 2 元字符:. ^ $ * + ? { } [ ] | ( ) \
元字符.^$*+?{}
import re
ret=re.findall('a..in','helloalvin')
print(ret)#['alvin']
ret=re.findall('^a...n','alvinhelloawwwn')
print(ret)#['alvin']
ret=re.findall('a...n$','alvinhelloawwwn')
print(ret)#['awwwn']
ret=re.findall('a...n$','alvinhelloawwwn')
print(ret)#['awwwn']
ret=re.findall('abc*','abcccc')#贪婪匹配[0,+oo]
print(ret)#['abcccc']
ret=re.findall('abc+','abccc')#[1,+oo]
print(ret)#['abccc']
ret=re.findall('abc?','abccc')#[0,1]
print(ret)#['abc']
ret=re.findall('abc{1,4}','abccc')
print(ret)#['abccc'] 贪婪匹配
注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
ret=re.findall('abc*?','abcccccc')
print(ret)#['ab']
元字符之字符集[]:
#--------------------------------------------字符集[]
ret=re.findall('a[bc]d','acd')
print(ret)#['acd'] ret=re.findall('[a-z]','acd')
print(ret)#['a', 'c', 'd'] ret=re.findall('[.*+]','a.cd+')
print(ret)#['.', '+'] #在字符集里有功能的符号: - ^ \ ret=re.findall('[1-9]','45dha3')
print(ret)#['4', '5', '3'] ret=re.findall('[^ab]','45bdha3')
print(ret)#['4', '5', 'd', 'h', '3'] ret=re.findall('[\d]','45bdha3')
print(ret)#['4', '5', '3']
元字符之转义符\
反斜杠后边跟元字符去除特殊功能,比如\.
反斜杠后边跟普通字符实现特殊功能,比如\d
\d 匹配任何十进制数;它相当于类 [0-9]。
\D 匹配任何非数字字符;它相当于类 [^0-9]。
\s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。
\S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。
\w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。
\W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]
\b 匹配一个特殊字符边界,比如空格 ,&,#等
ret=re.findall('I\b','I am LIST')
print(ret)#[]
ret=re.findall(r'I\b','I am LIST')
print(ret)#['I']
现在我们聊一聊\,先看下面两个匹配:
#-----------------------------eg1:
import re
ret=re.findall('c\l','abc\le')
print(ret)#[]
ret=re.findall('c\\l','abc\le')
print(ret)#[]
ret=re.findall('c\\\\l','abc\le')
print(ret)#['c\\l']
ret=re.findall(r'c\\l','abc\le')
print(ret)#['c\\l'] #-----------------------------eg2:
#之所以选择\b是因为\b在ASCII表中是有意义的
m = re.findall('\bblow', 'blow')
print(m)
m = re.findall(r'\bblow', 'blow')
print(m)
元字符之分组()
m = re.findall(r'(ad)+', 'add')
print(m) ret=re.search('(?P<id>\d{2})/(?P<name>\w{3})','23/com')
print(ret.group())#23/com
print(ret.group('id'))#23
元字符之|
ret=re.search('(ab)|\d','rabhdg8sd')
print(ret.group())#ab
re模块下的常用方法
import re
#1
re.findall('a','alvin yuan')
#返回所有满足匹配条件的结果,放在列表里
#2
re.search('a','alvin yuan').group()
#函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以
# 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 #3
re.match('a','abc').group()
#同search,不过尽在字符串开始处进行匹配 #4
ret=re.split('[ab]','abcd')
#先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
print(ret)#['', '', 'cd'] #5
ret=re.sub('\d','abc','alvin5yuan6',1)
print(ret)#alvinabcyuan6
ret=re.subn('\d','abc','alvin5yuan6')
print(ret)#('alvinabcyuanabc', 2) #6
obj=re.compile('\d{3}')
ret=obj.search('abc123eeee')
print(ret.group())#123
import re
ret=re.finditer('\d','ds3sy4784a')
print(ret) #<callable_iterator object at 0x10195f940> print(next(ret).group())
print(next(ret).group())
注意:
import re
ret=re.findall('www.(baidu|oldboy).com','www.oldboy.com')
print(ret)#['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret=re.findall('www.(?:baidu|oldboy).com','www.oldboy.com')
print(ret)#['www.oldboy.com']
import re
print(re.findall("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>"))
print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>"))
print(re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>"))
#匹配出所有的整数
import re #ret=re.findall(r"\d+{0}]","1-2*(60+(-40.35/5)-(-4*3))")
ret=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))")
ret.remove("") print(ret)
再来一张图:
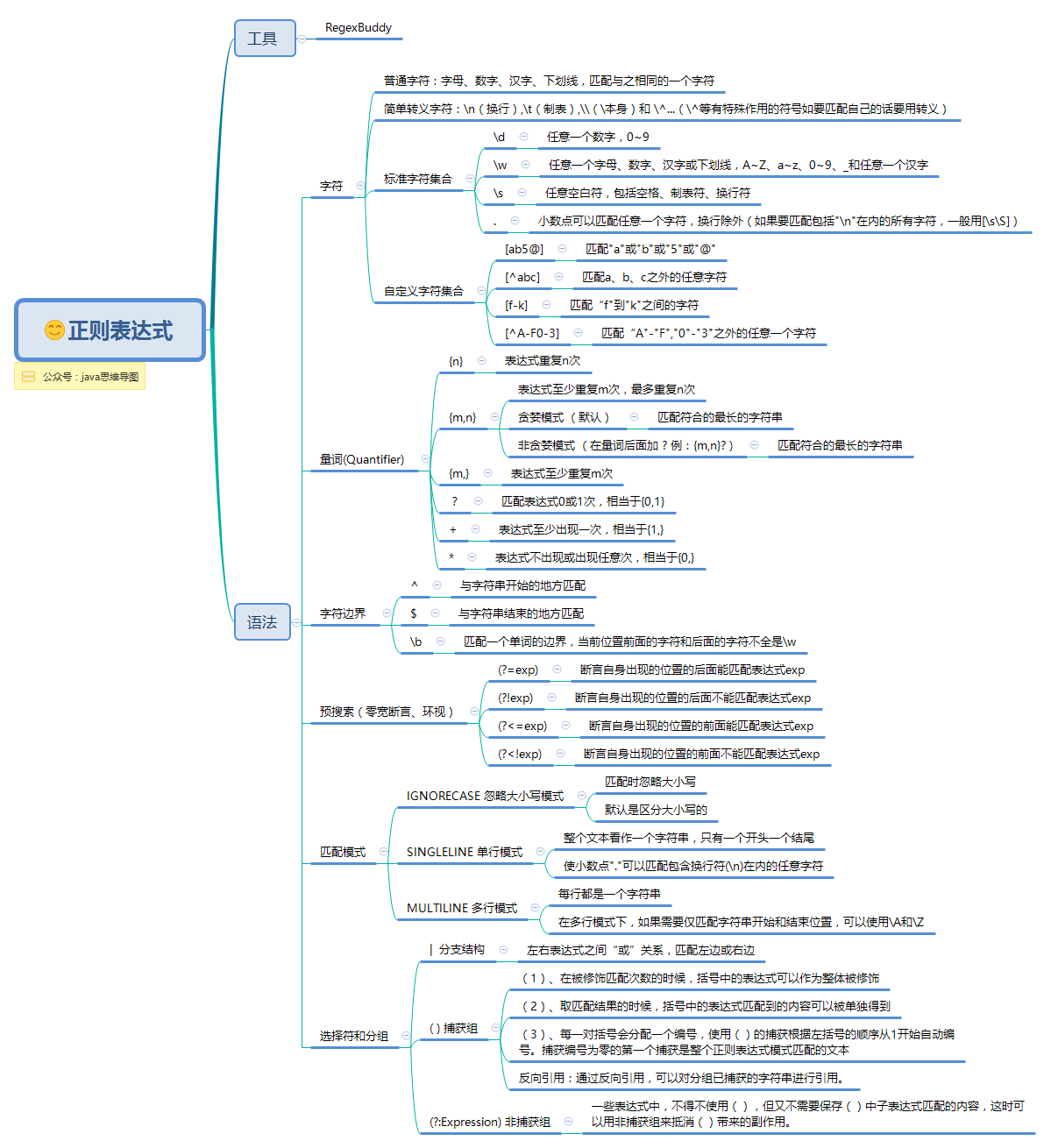
那两张图来自:https://blog.csdn.net/xujin0/article/details/83312406
python 详解正则表达式的使用(re模块)的更多相关文章
- [转载]python 详解re模块
原文地址:python 详解re模块作者:Rocky 正则表达式的元字符有. ^ $ * ? { [ ] | ( ) .表示任意字符 []用来匹配一个指定的字符类别,所谓的字符类别就是你想匹配的一个字 ...
- 33 Python 详解命令解析 - argparse--更加详细--转载
https://blog.csdn.net/lis_12/article/details/54618868 Python 详解命令行解析 - argparse Python 详解命令行解析 - arg ...
- python 详解re模块
正则表达式的元字符有. ^ $ * ? { [ ] | ( ).表示任意字符[]用来匹配一个指定的字符类别,所谓的字符类别就是你想匹配的一个字符集,对于字符集中的字符可以理解成或的关系.^ 如果放在字 ...
- python详解json模块
我们在做工作中经常会使用到json模块,今天就简单介绍下json模块 什么是json JSON ,全称为JavaScript Object Notation, 也就是JavaScript 对象标记,它 ...
- JavaScript系列文章:详解正则表达式之一
正则表达式是一个精巧的利器,经常用来在字符串中查找和替换,JavaScript语言参照Perl,也提供了正则表达式相关模块,开发当中非常实用,在一些类库或是框架中,比如jQuery,就存在大量的正则表 ...
- iOS开发之详解正则表达式
本文由Charles翻自raywenderlich原文:NSRegularExpression Tutorial: Getting Started更新提示:本教程被James Frost更新到了iOS ...
- JavaScript: 详解正则表达式之一
正则表达式是一个精巧的利器,经常用来在字符串中查找和替换,JavaScript语言参照Perl,也提供了正则表达式相关模块,开发当中非常实用,在一些类库或是框架中,比如jQuery,就存在大量的正则表 ...
- JavaScript系列文章:详解正则表达式之二
在上一篇文章中我们讲了正则表达式的基本用法,接下来博主想聊聊其中的细节,今天就从正则修饰符开始吧. 正则修饰符又称为正则标记(flags),它会对正则的匹配规则做限定,进而影响匹配的最终结果.在上次的 ...
- JavaScript系列文章:详解正则表达式之三
在上两篇文章中博主介绍了JavaScript中的正则常用方法和正则修饰符,今天准备聊一聊元字符和高级匹配的相关内容. 首先说说元字符,想必大家也都比较熟悉了,JS中的元字符有以下几种: / \ | . ...
随机推荐
- NFS Server宕机后,NFS Client主机上df命令挂死
方法1: 使用root用户:Oracle@NDMCDB05:~> su -Password: NDMCDB05:~ # cat /etc/mtab /dev/sda2 / reiserfs rw ...
- Partition--使用分区切换来增加修改列的自增属性
使用分区来将非自增表改为自增表 ------------------------------------------------- --创建测试表TestTable001和TestTable002 C ...
- INDEX--从数据存放的角度看索引
测试表结构: CREATE TABLE TB1 ( ID ,), C1 INT, C2 INT ) 1. 聚集索引(Clustered index) 聚集索引可以理解为一个包含表中除索引键外多有剩余列 ...
- 一些LinuxC的小知识点(一)
以下代码在Federo9上试验成功. 一.格式化输入16进制字符串 printf(); 输入结果: 二.测试各类型的占用的字节数 int main(int argc, char *argv[]) { ...
- adb错误 - INSTALL_FAILED_NO_MATCHING_ABIS
#背景 换组啦,去了UC国际浏览器,被拥抱变化了.还在熟悉阶段,尝试了下adb,然后就碰到了这个INSTALL_FAILED_NO_MATCHING_ABIS的坑... #解决方法 INSTALL_F ...
- CentOS7中配置vsftpd
1.yum -y install vsftpd 安装vsftpd 2.配置vsftpd的配置文件(/etc/vsftpd/vsftpd.conf)主要修改以下配置内容 #不允许匿名访问 anonym ...
- 未能加载文件或程序集“System.Web.Http.WebHost, Version=4.0.0.0, ”或它的某一个依赖项。系统找不到指定的文件。
第一次发布MVC项目,打开网站 未能加载文件或程序集“System.Web.Http.WebHost, Version=4.0.0.0, ”或它的某一个依赖项.系统找不到指定的文件. 问题原因:缺少配 ...
- 在Asp.Net MVC中利用快递100接口实现订阅物流轨迹功能
前言 分享一篇关于在电商系统中同步物流轨迹到本地服务器的文章,当前方案使用了快递100做为数据来源接口,这个接口是收费的,不过提供的功能还是非常强大的,有专门的售后维护团队.也有免费的方案,类似于快递 ...
- C# 使用Google Protocol Buffers
Google Protocol Buffers 使用3.0版本 下载protoc.exe 下载链接 https://github.com/protocolbuffers/protobuf/releas ...
- 【计算机网络】TCP通信的细节及TCP连接对HTTP事务处理性能影响
从三次握手的细节说起 刚开始尝试使用java等后端语言写IO流,或用套接字(socket)实现简单C/S通信的同学们,常常会接触到的一个概念:就是所谓的“三次握手”,socket作为一个API接口,封 ...