24-hadoop-hiveserver2&jdbc-正则数据导入
hive 可以 类似jdbc链接, 但启动的必须是hiveserver2, 才可以使用
hiveserver2
默认监听 10000 端口
1, 启动:
nohup $HIVE_HOME/bin/hiveserver2 1>/dev/null 2>&1 &
重定向输出, 不干扰shell界面
nohup 用户退出, 也可以继续执行
或者
$HIVE_HOME/bin/hive --service hiveserver2 1>/dev/null 2>&1 &
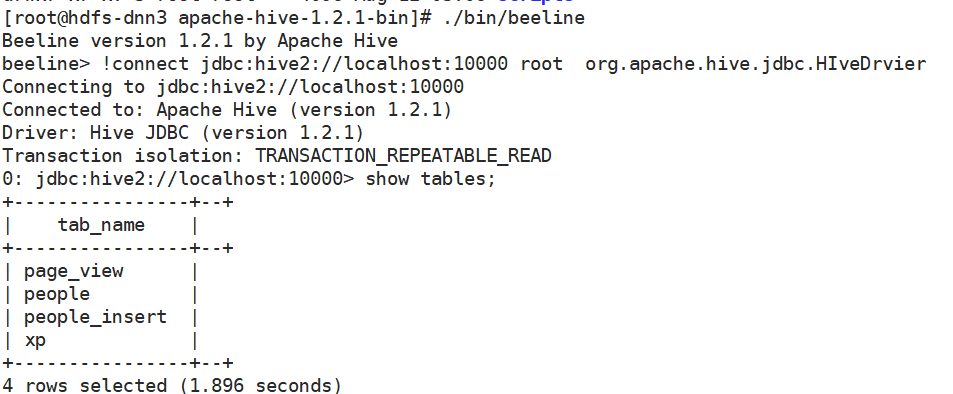
2, 使用 Beeline 进行连接
beelin
使用beeline链接, 和普通的hive是一样的, 只不过是远程的方式连接的, 操作命令几乎相同
!connect jdbc:hive2://192.168.208.109:10000 username password // org.apache.hive.jdbc.HIveDrvier
因为密码为空, 所以不需要写
!connect jdbc:hive2://localhost:10000 root // org.apache.hive.jdbc.HIveDrvier
可以直接链接
beelin -u jdbc:hive2://.. -n root
3, 退出
!quit
JDBC链接
java链接:
1, 导入jar包:
${HIVE_HOME}/lib下的所有包
2, 导入hadoop的包, 否则报错

导入的包为:
${HADOOP_HOME}/share/hadoop/common/*

package com.wenbronk.hive; import java.sql.*; /**
*
*/
public class JDBCMain { private static String driverName = "org.apache.hive.jdbc.HiveDriver"; public static void main(String[] args) throws SQLException {
try {
Class.forName(driverName);
Connection con = DriverManager.getConnection("jdbc:hive2://192.168.208.109:10000/default", "root", ""); String sql = "select * from people";
PreparedStatement state = con.prepareStatement(sql); ResultSet res = state.executeQuery(); while (res.next()) {
System.out.println(res.getString() + "\t" + res.getString());
} } catch (ClassNotFoundException e) {
e.printStackTrace();
System.exit();
}finally {
//close
}
}
}
官网的例子坑太多了, python的链接没有实际操作, 改天试下并修改!!!!
python 链接
需要先安装包
pip install pyhs2
然后链接:
import pyhs2 with pyhs2.connect(host='localhost',
port=,
authMechanism="PLAIN",
user='root',
password='',
database='default') as conn:
with conn.cursor() as cur:
#Show databases
print cur.getDatabases() #Execute query
cur.execute("select * from table") #Return column info from query
print cur.getSchema() #Fetch table results
for i in cur.fetch():
print i
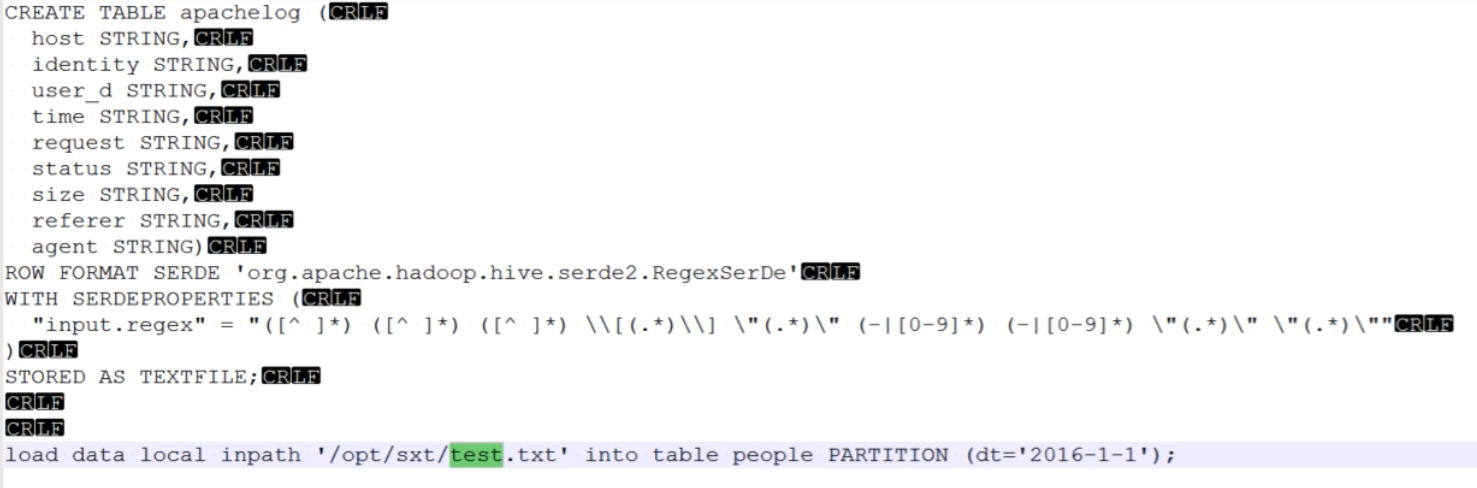
使用正则导入不规则数据
使用regexBuddy, 来正确匹配正则表达式
匹配nignx日志;
系列来自尚学堂极限班
24-hadoop-hiveserver2&jdbc-正则数据导入的更多相关文章
- Sqoop -- 用于Hadoop与关系数据库间数据导入导出工作的工具
Sqoop是一款开源的工具,主要用于在Hadoop相关存储(HDFS.Hive.HBase)与传统关系数据库(MySql.Oracle等)间进行数据传递工作.Sqoop最早是作为Hadoop的一个第三 ...
- 从零自学Hadoop(16):Hive数据导入导出,集群数据迁移上
阅读目录 序 导入文件到Hive 将其他表的查询结果导入表 动态分区插入 将SQL语句的值插入到表中 模拟数据文件下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并 ...
- 从零自学Hadoop(17):Hive数据导入导出,集群数据迁移下
阅读目录 序 将查询的结果写入文件系统 集群数据迁移一 集群数据迁移二 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephis ...
- 使用sqoop将mysql数据导入到hadoop
hadoop的安装配置这里就不讲了. Sqoop的安装也很简单. 完成sqoop的安装后,可以这样测试是否可以连接到mysql(注意:mysql的jar包要放到 SQOOP_HOME/lib 下): ...
- Hive数据导入——数据存储在Hadoop分布式文件系统中,往Hive表里面导入数据只是简单的将数据移动到表所在的目录中!
转自:http://blog.csdn.net/lifuxiangcaohui/article/details/40588929 Hive是基于Hadoop分布式文件系统的,它的数据存储在Hadoop ...
- Hadoop Hive概念学习系列之HDFS、Hive、MySQL、Sqoop之间的数据导入导出(强烈建议去看)
Hive总结(七)Hive四种数据导入方式 (强烈建议去看) Hive几种数据导出方式 https://www.iteblog.com/archives/955 (强烈建议去看) 把MySQL里的数据 ...
- 用JDBC把Excel中的数据导入到Mysql数据库中
步骤:0.在Mysql数据库中先建好table 1.从Excel表格读数据 2.用JDBC连接Mysql数据库 3.把读出的数据导入到Mysql数据库的相应表中 其中,步骤0的table我是先在Mys ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- 通过 Sqoop1.4.7 将 Mysql5.7、Hive2.3.4、Hbase1.4.9 之间的数据导入导出
目录 目录 1.什么是 Sqoop? 2.下载应用程序及配置环境变量 2.1.下载 Sqoop 1.4.7 2.2.设置环境变量 2.3.设置安装所需环境 3.安装 Sqoop 1.4.7 3.1.修 ...
- sqoop1的安装以及数据导入导出测试
下载 wget http://mirror.bit.edu.cn/apache/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz 解压 tar -zxf ...
随机推荐
- (转)ASP.NET MVC3 Razor视图引擎-基础语法
转自:http://kb.cnblogs.com/page/96883/ I:ASP.NET MVC3在Visual Studio 2010中的变化 在VS2010中新建一个MVC3项目可以看出与以往 ...
- GPIO工作模式
共8种工作模式,4种输入,1.输入浮空模式2.输入上拉模式 3.输入下拉模式4.模拟输入模式 4种输出模式:开漏输出.开漏复用功能.推挽输出.推挽复用输出 ps:mos管就是场效应管,三极管有的时候也 ...
- Linux 快捷键使用
命令运行时使用CTRL+Z,强制当前进程转为后台,并使之停止. 1. 使进程恢复运行(后台) (1)使用命令bg Example: zuii@zuii-desktop:~/unp/tcpcliserv ...
- 【python3+request】python3+requests接口自动化测试框架实例详解教程
转自:https://my.oschina.net/u/3041656/blog/820023 [python3+request]python3+requests接口自动化测试框架实例详解教程 前段时 ...
- 《mysql必知必会》学习_第三章_20180724_欢
P16: use crashcourse; #选择数据库#使用crashcouse这个数据库,因为我没有crashcourse这个数据库,所以用我的hh数据库代替. P17: show databas ...
- jQuery插件初级练习5答案
html: $.kafei.fontsize($("p"),"30px").html("123") jQuery: $.kafei={ fo ...
- List of RGBD datasets
This is an incomplete list of datasets which were captured using a Kinect or similar devices. I init ...
- ASP.NET Core开源地址
https://github.com/dotnet/corefx 这个是.net core的 开源项目地址 https://github.com/aspnet 这个下面是asp.net core 框架 ...
- Windows核心编程:第2章 字符和字符串处理
Github https://github.com/gongluck/Windows-Core-Program.git //第2章 字符和字符串处理.cpp: 定义应用程序的入口点. // #incl ...
- Resolving SharePoint Application Authentication Error: Login Failed
Check event viewer log Click Start, click Run, type eventvwr, and then click OK. Click on Security u ...