hadoop之 Hadoop2.2.0中HDFS的高可用性实现原理
在Hadoop2.0.0之前,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障,那么将导致整个集群无法利用,直到NN重启或者在另一台主机上启动NN守护线程。
主要在两方面影响了HDFS的可用性:
(1)、在不可预测的情况下,如果NN所在的机器崩溃了,整个集群将无法利用,直到NN被重新启动;
(2)、在可预知的情况下,比如NN所在的机器硬件或者软件需要升级,将导致集群宕机。
HDFS的高可用性将通过在同一个集群中运行两个NN(active NN & standby NN)来解决上面两个问题,这种方案允许在机器破溃或者机器维护快速地启用一个新的NN来恢复故障。
在典型的HA集群中,通常有两台不同的机器充当NN。在任何时间,只有一台机器处于Active状态;另一台机器是处于Standby状态。Active NN负责集群中所有客户端的操作;而Standby NN主要用于备用,它主要维持足够的状态,如果必要,可以提供快速的故障恢复。
为了让Standby NN的状态和Active NN保持同步,即元数据保持一致,它们都将会和JournalNodes守护进程通信。当Active NN执行任何有关命名空间的修改,它需要持久化到一半以上的JournalNodes上(通过edits log持久化存储),而Standby NN负责观察edits log的变化,它能够读取从JNs中读取edits信息,并更新其内部的命名空间。一旦Active NN出现故障,Standby NN将会保证从JNs中读出了全部的Edits,然后切换成Active状态。Standby NN读取全部的edits可确保发生故障转移之前,是和Active NN拥有完全同步的命名空间状态。
为了提供快速的故障恢复,Standby NN也需要保存集群中各个文件块的存储位置。为了实现这个,集群中所有的Database将配置好Active NN和Standby NN的位置,并向它们发送块文件所在的位置及心跳,如下图所示:
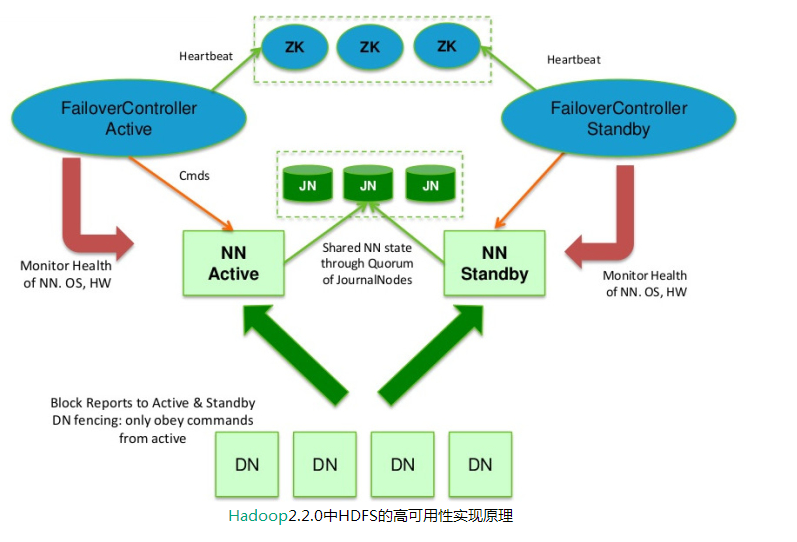
在任何时候,集群中只有一个NN处于Active 状态是极其重要的。否则,在两个Active NN的状态下NameSpace状态将会出现分歧,这将会导致数据的丢失及其它不正确的结果。为了保证这种情况不会发生,在任何时间,JNs只允许一个NN充当writer。在故障恢复期间,将要变成Active 状态的NN将取得writer的角色,并阻止另外一个NN继续处于Active状态。
为了部署HA集群,你需要准备以下事项:
(1)、NameNode machines:运行Active NN和Standby NN的机器需要相同的硬件配置;
(2)、JournalNode machines:也就是运行JN的机器。JN守护进程相对来说比较轻量,所以这些守护进程可以可其他守护线程(比如NN,YARN ResourceManager)运行在同一台机器上。在一个集群中,最少要运行3个JN守护进程,这将使得系统有一定的容错能力。当然,你也可以运行3个以上的JN,但是为了增加系统的容错能力,你应该运行奇数个JN(3、5、7等),当运行N个JN,系统将最多容忍(N-1)/2个JN崩溃。
在HA集群中,Standby NN也执行namespace状态的checkpoints,所以不必要运行Secondary NN、CheckpointNode和BackupNode;事实上,运行这些守护进程是错误的。
source : https://www.iteblog.com/archives/833.html#comments
hadoop之 Hadoop2.2.0中HDFS的高可用性实现原理的更多相关文章
- [置顶] Hadoop2.2.0中HDFS的高可用性实现原理
在Hadoop2.0.0之前,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障 ...
- Hadoop-2.4.0中HDFS文件块大小默认为128M
134217728 / 1024 = 131072 / 1024 = 128
- Hadoop-2.2.0中文文档—— 从Hadoop 1.x 迁移至 Hadoop 2.x
简单介绍 本文档对从 Apache Hadoop 1.x 迁移他们的Apache Hadoop MapReduce 应用到 Apache Hadoop 2.x 的用户提供了一些信息. 在 Apache ...
- Hadoop-2.2.0中文文档——MapReduce 下一代 -——集群配置
目的 这份文档描写叙述了怎样安装.配置和管理从几个节点到有数千个节点的Hadoop集群. 玩的话,你可能想先在单机上安装.(看单节点配置). 准备 从Apache镜像上下载一个Hadoop的稳定版本号 ...
- hadoop2.6.0中自定义分割符
最近在学习hadoop,用的hadoop2.6.0 然后在学习编写mapreduce程序时,发现默认对文件的输入是采用每行进行分割,下面来分析下改变这个分割方式的办法: 来看看默认是怎样实现的:
- Hadoop2.6.0的FileInputFormat的任务切分原理分析(即如何控制FileInputFormat的map任务数量)
前言 首先确保已经搭建好Hadoop集群环境,可以参考<Linux下Hadoop集群环境的搭建>一文的内容.我在测试mapreduce任务时,发现相比于使用Job.setNumReduce ...
- Hadoop-2.2.0中文文档——Apache Hadoop 下一代 MapReduce (YARN)
MapReduce在hadoop-0.23中已经经历了一次全然彻底地大修.就是如今我们叫的MapReduce 2.0 (MRv2) or YARN. MRv2的基本思想是把JobTracker分成两个 ...
- Hadoop-2.2.0中文文档—— Common - CLI MiniCluster
目的 使用 CLI MiniCluster, 用户能够简单地仅仅用一个命令就启动或关闭一个单一节点的Hadoop集群,不须要设置不论什么环境变量或管理配置文件. CLI MiniCluster 同一时 ...
- Hadoop-2.2.0中文文档—— Common - Native Libraries Guide
概览 这个新手教程描写叙述了native(本地?原生?)hadoop库,包括了一小部分关于native hadoop共享库的讨论. This guide describes the native ha ...
随机推荐
- 1-12 RHEL7-find命令的使用
1.文件查找findfind命令是在目录结构中,搜索文件,并执行特定的操作find命令提供了相当多的查找条件,功能很强大 2.格式usage:find pathname -options[-print ...
- bzoj 1996 区间dp
1996: [Hnoi2010]chorus 合唱队 Time Limit: 4 Sec Memory Limit: 64 MBSubmit: 1727 Solved: 1115[Submit][ ...
- iptables详解(10):iptables自定义链
前文中,我们一直在定义规则,准确的说,我们一直在iptables的默认链中定义规则,那么此处,我们就来了解一下自定义链. 你可能会问,iptables的默认链就已经能够满足我们了,为什么还需要自定义链 ...
- Reverse a String
题目: 翻转字符串 先把字符串转化成数组,再借助数组的reverse方法翻转数组顺序,最后把数组转化成字符串. 你的结果必须得是一个字符串 这是一些对你有帮助的资源: Global String Ob ...
- mybatis定义拦截器
applicationContext.xml <bean id="sqlSessionFactory" class="org.mybatis.spring.SqlS ...
- ie下的bug之button
场景描述: 现在页面设计是都喜欢自定义按钮样式,某日接收到页面发现在ie下有bug,上代码: <div> <button><span><a href=&quo ...
- 转载:【Oracle 集群】RAC知识图文详细教程(二)--Oracle 集群概念及原理
文章导航 集群概念介绍(一) ORACLE集群概念和原理(二) RAC 工作原理和相关组件(三) 缓存融合技术(四) RAC 特殊问题和实战经验(五) ORACLE 11 G版本2 RAC在LINUX ...
- Linux设备驱动——简单的字符驱动
本文介绍Linux字符设备的静态注册方法, 其中涉及到的模块加载,不了解的可以先参考 构建和运行模块 1. 还是线上源代码: //memdev.h #ifndef _MEMDEV_H_ #define ...
- GreenPlum的Primary和Mirro切换恢复
gp节点出现了acting as primary change tracking错误,判断是节点primary和mirror发生了切换 1.没有配置gp的日志,无法获取为什么切换了,待会儿看看默认日志 ...
- Struts2开发步骤
第一步:新建we项目 新建名称为“Struts"的web工程,新建方法:File->New->Web Service Project->Profect Name中输入:St ...