Python并发编程-一个简单的爬虫
一个简单的爬虫
#网页状态码
#200 正常
#404 网页找不到
#502 504
import requests
from multiprocessing import Pool
def get(url):
response = requests.get(url)
if response.status_code == 200:
return url, response.content.decode('utf-8')
def call_back(args):
url,content = args #拆包args中传入的参数
print(url,len(content))
if __name__ == '__main__':
url_lst = [
'https://www.cnblogs.com',
'https://www.sogou.com',
'http://www.sohu.com',
'http://www.baidu.com'
]
p = Pool(5)
for url in url_lst:
p.apply_async(get,args=(url,),callback=call_back) #利用callback去用主进程执行Call_back函数中的功能
p.close()
p.join()
爬虫进阶
import re
from urllib.request import urlopen
from multiprocessing import Pool
def get_page(url,pattern):
response=urlopen(url).read().decode('utf-8')
return pattern,response #正则表达式编译结果,网页内容
def parse_page(info):
pattern,page_content=info
res=re.findall(pattern,page_content)
for item in res:
dic={
'index':item[0].strip(),
'title':item[1].strip(),
'actor':item[2].strip(),
'time':item[3].strip(),
}
print(dic)
if __name__ == '__main__':
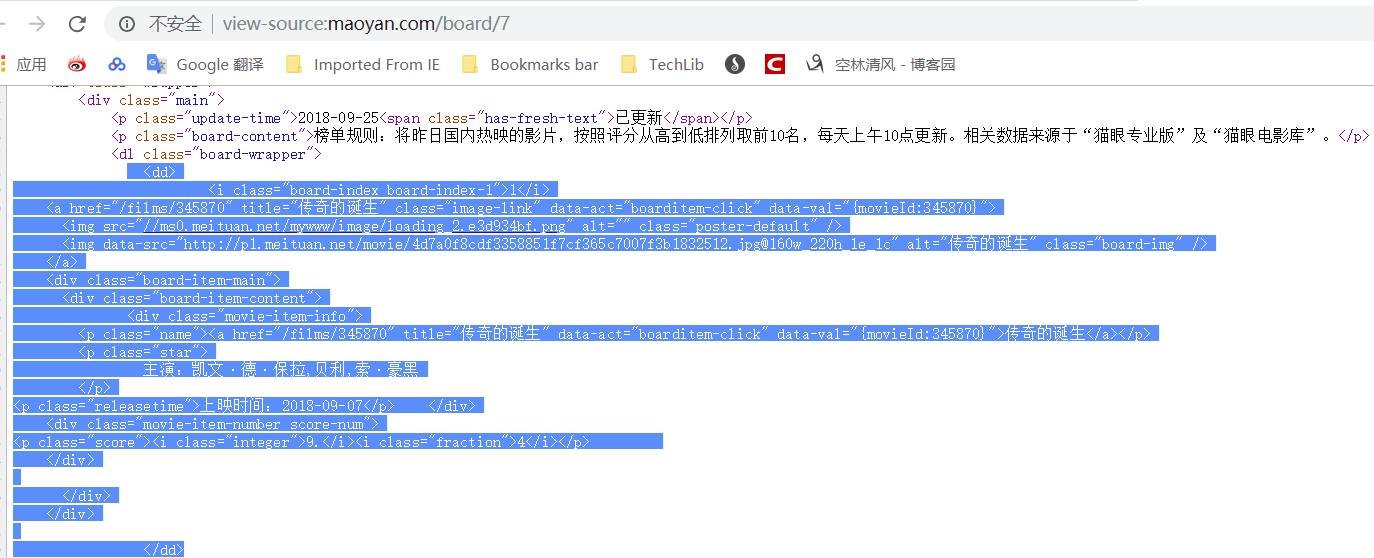
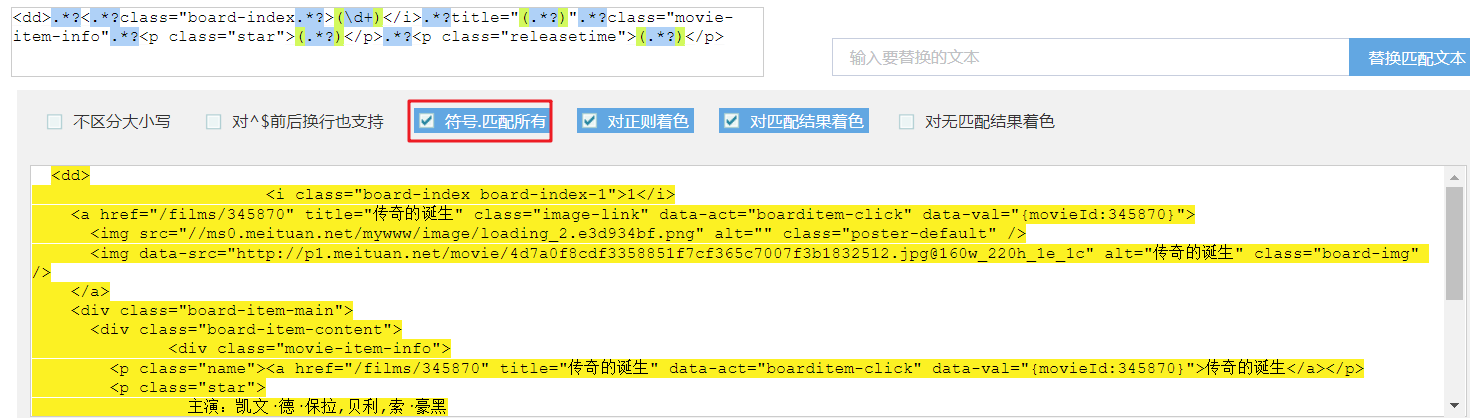
regex = r'<dd>.*?<.*?class="board-index.*?>(\d+)</i>.*?title="(.*?)".*?class="movie-item-info".*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>'
pattern1=re.compile(regex,re.S)
url_dic={
'http://maoyan.com/board/7':pattern1,
}
p=Pool()
res_l=[]
for url,pattern in url_dic.items():
res=p.apply_async(get_page,args=(url,pattern),callback=parse_page)
res_l.append(res)
for i in res_l:
i.get()
>>>
{'index': '1', 'title': '传奇的诞生', 'actor': '主演:凯文·德·保拉,贝利,索·豪黑', 'time': '上映时间:2018-09-07'}
{'index': '2', 'title': '大寒', 'actor': '主演:张双兵,鲁园,许薇', 'time': '上映时间:2018-08-14'}
{'index': '3', 'title': '苏丹', 'actor': '主演:萨尔曼·汗,安努舒卡·莎玛,兰迪普·弘达', 'time': '上映时间:2018-08-31'}
{'index': '4', 'title': '爸,我一定行的', 'actor': '主演:郑润奇,郑鹏生,张咏娴', 'time': '上映时间:2018-08-24'}
{'index': '5', 'title': '李宗伟:败者为王', 'actor': '主演:李宗伟,李国煌,杨雁雁', 'time': '上映时间:2018-09-07'}
{'index': '6', 'title': '悲伤逆流成河', 'actor': '主演:赵英博,任敏,辛云来', 'time': '上映时间:2018-09-21'}
{'index': '7', 'title': '碟中谍6:全面瓦解', 'actor': '主演:汤姆·克鲁斯,亨利·卡维尔,文·瑞姆斯', 'time': '上映时间:2018-08-31'}
{'index': '8', 'title': '快把我哥带走', 'actor': '主演:张子枫,彭昱畅,赵今麦', 'time': '上映时间:2018-08-17'}
{'index': '9', 'title': '赛尔号大电影6:圣者无敌', 'actor': '主演:罗玉婷,翟巍,王晓彤', 'time': '上映时间:2017-08-18'}
{'index': '10', 'title': '念念手纪', 'actor': '主演:滨边美波,北村匠海,北川景子', 'time': '上映时间:2018-09-14'}
正则表达式的在线校验网站
Python并发编程-一个简单的爬虫的更多相关文章
- Python并发编程-一个简单的多进程实例
import time from multiprocessing import Process import os def func(args,args2): #传递参数到进程 print(args, ...
- [Python网络编程]一个简单的TCP时间服务器
服务器端: 1.创建一个面向网络的TCP套接字对象socket, 2.绑定地址和端口 3.监听 4.当有客户端连接时候,接受连接并给此连接分配一个新的套接字 5.当客户端发送空信息时候,关闭新分配的套 ...
- Python网络编程 - 一个简单的客户端Get请求程序
import socket target_host = "www.baidu.com" target_port = 80 # create a socket object clie ...
- python (1)一个简单的爬虫: python 在windows下 创建文件夹并写入文件
1.一个简单的爬虫:爬取豆瓣的热门电影的信息 写在前面:如何创建本来存在的文件夹并写入 t_path = "d:/py/inn" #本来不存在inn,先定义路径,然后如果不存在,则 ...
- python爬虫系列(1)——一个简单的爬虫实例
本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片. 1. 概述 本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片.下载图片的步骤如下: 获取网页html文本内容:分析html中 ...
- Python并发编程之深入理解yield from语法(八)
大家好,并发编程 进入第八篇. 直到上一篇,我们终于迎来了Python并发编程中,最高级.最重要.当然也是最难的知识点--协程. 当你看到这一篇的时候,请确保你对生成器的知识,有一定的了解.当然不了解 ...
- Python并发编程二(多线程、协程、IO模型)
1.python并发编程之多线程(理论) 1.1线程概念 在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程 线程顾名思义,就是一条流水线工作的过程(流水线的工作需要电源,电源就相当于 ...
- Python并发编程理论篇
Python并发编程理论篇 前言 其实关于Python的并发编程是比较难写的一章,因为涉及到的知识很复杂并且理论偏多,所以在这里我尽量的用一些非常简明的语言来尽可能的将它描述清楚,在学习之前首先要记住 ...
- 《转载》Python并发编程之线程池/进程池--concurrent.futures模块
本文转载自Python并发编程之线程池/进程池--concurrent.futures模块 一.关于concurrent.futures模块 Python标准库为我们提供了threading和mult ...
随机推荐
- libxml移植到android
libxml是C语言写的xml解析库,是我们开发可移植程序的首选,下面讲述将其移植到android的步骤 1.下载已经配置好的源代码包android_libxml2.rar http://pan.ba ...
- JS中的new操作符原理解析
var Person = function(name){ this.name = name; } Person.prototype.sayHello = function() { console.lo ...
- 816B. Karen and Coffee 前缀和思维 或 线段树
LINK 题意:给出n个[l,r],q个询问a,b,问被包含于[a,b]且这样的区间数大于k个的方案数有多少 思路:预处理所有的区间,对于一个区间我们标记其(左边界)++,(右边界+1)--这样就能通 ...
- OD~~helloworld
要爆破的C程序源码: #include <stdio.h> int main() { int x; scanf("%d",&x); ) printf(" ...
- JQuery 中三十一种选择器的应用
选择器(selector)是CSS中很重要的概念,所有HTML语言中的标记都是通过不同的CSS选择器进行控制的.用户只需要通过选择器对不同的HTML标签进行控制,并赋予各种样式声明,即可实现各种效果. ...
- POJ 1050 To the Max (最大子矩阵和)
题目链接 题意:给定N*N的矩阵,求该矩阵中和最大的子矩阵的和. 题解:把二维转化成一维,算下就好了. #include <cstdio> #include <cstring> ...
- Vue 传递
今天刷了一遍Vue的API,做个小笔记 父子传递数据时,父组件里标记要传的数据,子组件里用props获取,子组件用$emit('func',args)发布事件,父组件用@func接收. 方法一 par ...
- hdu 5326 Work(杭电多校赛第三场)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5326 Work Time Limit: 2000/1000 MS (Java/Others) M ...
- python基础之常用的高阶函数
前言 高阶函数指的是能接收函数作为参数的函数或类:python中有一些内置的高阶函数,在某些场合使用可以提高代码的效率. map() map函数可以把一个迭代对象转换成另一个可迭代对象,不过在pyth ...
- sar命令使用【转】
sar(System Activity Reporter系统活动情况报告)是目前 Linux 上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况.系统调用的使用情 ...