用10张图来看机器学习Machine learning in 10 pictures
I find myself coming back to the same few pictures when explaining basic machine learning concepts. Below is a list I find most illuminating.
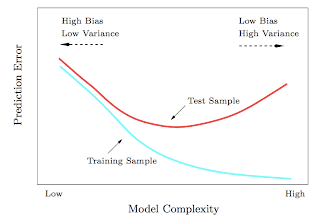
1. Test and training error: Why lower training error is not always a good thing: ESL Figure 2.11. Test and training error as a function of model complexity.
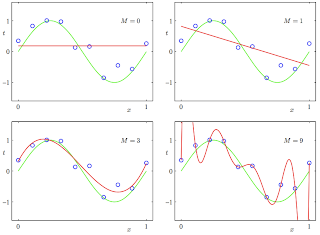
2. Under and overfitting: PRML Figure 1.4. Plots of polynomials having various orders M, shown as red curves, fitted to the data set generated by the green curve.
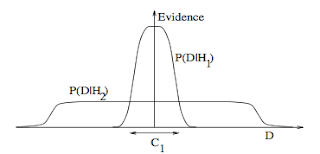
3. Occam's razor: ITILA Figure 28.3. Why Bayesian inference embodies Occam’s razor. This figure gives the basic intuition for why complex models can turn out to be less probable. The horizontal axis represents the space of possible data sets D. Bayes’ theorem rewards models in proportion to how much they predicted the data that occurred. These predictions are quantified by a normalized probability distribution on D. This probability of the data given model Hi, P (D | Hi), is called the evidence for Hi. A simple model H1 makes only a limited range of predictions, shown by P(D|H1); a more powerful model H2, that has, for example, more free parameters than H1, is able to predict a greater variety of data sets. This means, however, that H2 does not predict the data sets in region C1 as strongly as H1. Suppose that equal prior probabilities have been assigned to the two models. Then, if the data set falls in region C1, the less powerful model H1 will be the more probable model.
4. Feature combinations: (1) Why collectively relevant features may look individually irrelevant, and also (2) Why linear methods may fail. From Isabelle Guyon's feature extraction slides.
.png)
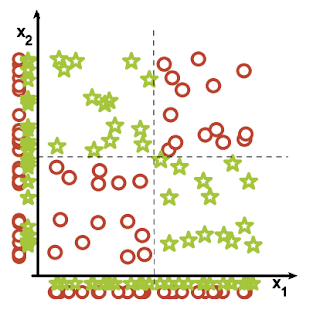
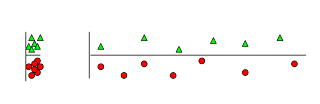
5. Irrelevant features: Why irrelevant features hurt kNN, clustering, and other similarity based methods. The figure on the left shows two classes well separated on the vertical axis. The figure on the right adds an irrelevant horizontal axis which destroys the grouping and makes many points nearest neighbors of the opposite class.
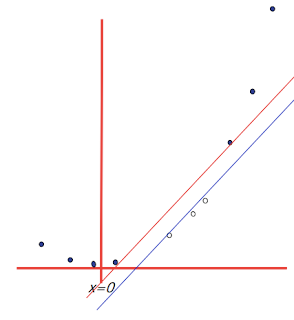
6. Basis functions: How non-linear basis functions turn a low dimensional classification problem without a linear boundary into a high dimensional problem with a linear boundary. From SVM tutorial slides by Andrew Moore: a one dimensional non-linear classification problem with input x is turned into a 2-D problem z=(x, x^2) that is linearly separable.
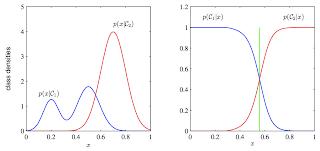
7. Discriminative vs. Generative: Why discriminative learning may be easier than generative: PRML Figure 1.27. Example of the class-conditional densities for two classes having a single input variable x (left plot) together with the corresponding posterior probabilities (right plot). Note that the left-hand mode of the class-conditional density p(x|C1), shown in blue on the left plot, has no effect on the posterior probabilities. The vertical green line in the right plot shows the decision boundary in x that gives the minimum misclassification rate.
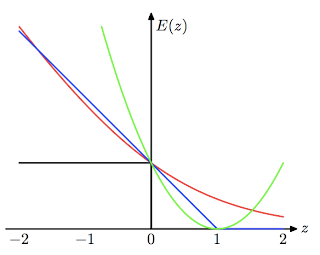
8. Loss functions: Learning algorithms can be viewed as optimizing different loss functions: PRML Figure 7.5. Plot of the ‘hinge’ error function used in support vector machines, shown in blue, along with the error function for logistic regression, rescaled by a factor of 1/ln(2) so that it passes through the point (0, 1), shown in red. Also shown are the misclassification error in black and the squared error in green.
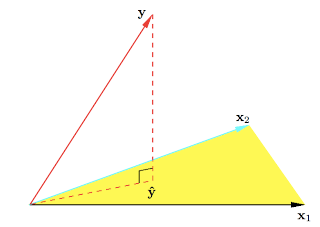
9. Geometry of least squares: ESL Figure 3.2. The N-dimensional geometry of least squares regression with two predictors. The outcome vector y is orthogonally projected onto the hyperplane spanned by the input vectors x1 and x2. The projection yˆ represents the vector of the least squares predictions.
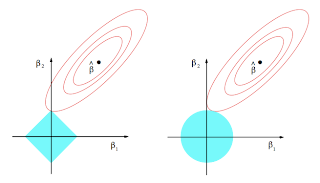
10. Sparsity: Why Lasso (L1 regularization or Laplacian prior) gives sparse solutions (i.e. weight vectors with more zeros): ESL Figure 3.11. Estimation picture for the lasso (left) and ridge regression (right). Shown are contours of the error and constraint functions. The solid blue areas are the constraint regions |β1| + |β2| ≤ t and β12 + β22 ≤ t2, respectively, while the red ellipses are the contours of the least squares error function.
from: http://www.denizyuret.com/2014/02/machine-learning-in-5-pictures.html
用10张图来看机器学习Machine learning in 10 pictures的更多相关文章
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- 机器学习(Machine Learning)&深入学习(Deep Learning)资料
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost 到随机森林. ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料汇总 (上)
转载:http://dataunion.org/8463.html?utm_source=tuicool&utm_medium=referral <Brief History of Ma ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料
机器学习(Machine Learning)&深度学习(Deep Learning)资料 機器學習.深度學習方面不錯的資料,轉載. 原作:https://github.com/ty4z2008 ...
- 机器学习(Machine Learning)与深度学习(Deep Learning)资料汇总
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)
##机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)---#####注:机器学习资料[篇目一](https://github.co ...
- 数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)的区别是什么? 数据科学(data science)和商业分析(business analytics)之间有什么关系?
本来我以为不需要解释这个问题的,到底数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)有什么区别,但是前几天因为有个学弟问我,我想了想发现我竟然也回答 ...
随机推荐
- springcloud 显示服务详细健康信息
pom.xml <?xml version="1.0" encoding="UTF-8"?> <project xmlns="htt ...
- C++ 字符串基本操作
C++ 规定,不能直接进行数组名的赋值,因为数组名是一个常量,而结构类型的变量可以赋值,不同结构体的变量不允许相互赋值,即使这两个变量可能具有相同的成员.在程序中不能同时出现无参构造函数和带有全部默认 ...
- java_方法
方法 1.1方法概述 在我们的日常生活中,方法可以理解为要做某件事情,而采取的解决办法. 如:小明同学在路边准备坐车来学校学习.这就面临着一件事情(坐车到学校这件事情)需要解决,解决办法呢?可采用坐公 ...
- 浅谈MVVM模式和MVP模式——Vue.js向
浅谈MVVM模式和MVP模式--Vue.js向 传统前端开发的MVP模式 MVP开发模式的理解过程 首先代码分为三层: model层(数据层), presenter层(控制层/业务逻辑相关) view ...
- python 多进程操作
由于python 多线程是无法在多核上发挥优势的,所以才用多进程的方式来折中将这个问题解决. from multiprocessing import Pool import os def f(x): ...
- RxSwift 系列(八)
前言 本篇文章我们将学习RxSwift中的错误处理,包括: catchErrorJustReturn catchError retry retry(_:) catchErrorJustReturn 遇 ...
- Scrapy实战篇(四)之周杰伦到底唱了啥
从小到大,一直很喜欢听周杰伦唱的歌,可是相信很多人和我一样,并不能完全听明白歌词究竟是什么,今天我们就来研究一下周董最喜欢在歌词中用的词,这一小节的构思是这样的,我们爬取周杰伦的歌词信息,并且将其进行 ...
- 【BZOJ 4148】 4148: [AMPPZ2014]Pillars (乱搞)
4148: [AMPPZ2014]Pillars Time Limit: 5 Sec Memory Limit: 256 MBSec Special JudgeSubmit: 100 Solve ...
- 【BZOJ 2006】2006: [NOI2010]超级钢琴(RMQ+优先队列)
2006: [NOI2010]超级钢琴 Time Limit: 20 Sec Memory Limit: 552 MBSubmit: 2792 Solved: 1388 Description 小 ...
- NOIP2017 D1T2时间复杂度
这道题在考试时看到感觉与第一题放反了位置(因为我还没有看到第一题是结论题) 对于每个语句进行栈的模拟,而如果有语法错误就特判. 对于每一条for语句我们将其与栈顶元素连边,复杂度是1的我们不用考虑,如 ...