【中文同义词近义词】词向量 vs 同义词近义词库
方案一:利用预训练好的词向量模型
优点: (1)能把词进行语义上的向量化(2)能得到词与词的相似度
缺点: (1)词向量的效果和语料库的大小和质量有较大的关系(2)用most_similar() 得到往往不是“同义词”,而是“共现词”
from gensim.models.keyedvectors import KeyedVectors
wv = KeyedVectors.load_word2vec_format('model/w2v_chisim_300d.bin', binary=True)
print "wv.vector_size:", wv.vector_size #
print "len(wv.vocab):", len(wv.vocab) #
def get_similar_words(kw):
if kw in wv.vocab:
print kw, "/".join([word for word, sim in wv.most_similar(kw, topn=10)])
# for word, sim in wv.most_similar(kw): # most_similar()的默认topn=10
# print word, sim # 相似词、相似度
if __name__ == '__main__':
kws = [u"群众", u"男人", u"女人", u"国王", u"皇后"]
for kw in kws:
get_similar_words(kw)
"""
wv.vector_size: 300
len(wv.vocab): 414638
群众 广大群众/百姓/职工群众/村民/老百姓/干部群众/农民/党员干部/困难群众/居民
男人 女人/女孩子/伴侣/女性/你/异性/男性/闺蜜/她们/花心
女人 男人/女孩子/女性/她们/你/花心/闺蜜/伴侣/异性/男性
国王 五世/王后/四世/君主/七世/六世/教皇/伊莉莎白/二世/路易十四
皇后 娘娘/公主/妃子/皇太后/皇帝/日本天皇/武则天/董鄂氏/太后/那拉氏
"""
方案二:同义词近义词库
比较经典的是哈工大社会计算与信息检索研究中心同义词词林扩展版
把词条按照树状的层次结果组织到一起,并区分了同义词和近义词,例如:

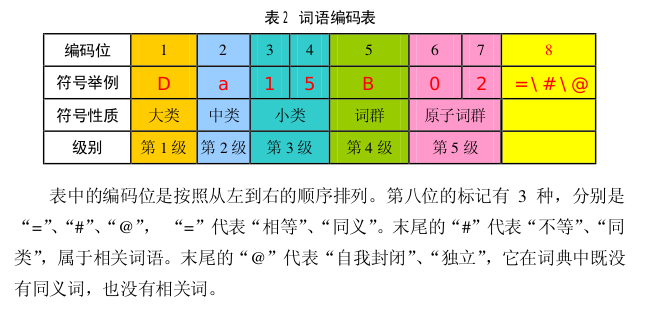
为了和上面词向量的结果进行对比,这里贴出了词林的结果:
Aa01B02= 群众 大众 公众 民众 万众 众生 千夫
Ab01A01= 男人 男子 男子汉 男儿 汉子 汉 士 丈夫 官人 男人家 光身汉 须眉 壮汉 男士
Ab01B01= 女人 女子 女性 女士 女儿 女 娘 妇 妇女 妇道 妇人 女人家 小娘子 女郎 巾帼 半边天 娘子军 石女 红装 家庭妇女 农妇 才女
Af05A01= 皇帝 帝 王 上 君 天子 天皇 帝王 君王 国王 国君 君主 当今 皇上 圣上 陛下 主公 九五 九五之尊 可汗 单于 大帝 沙皇 天骄 天王 五帝 太岁 王者 至尊 统治者
Af05B02= 皇后 王后 娘娘
可以看到词林在“同义”上的效果会更好一些。
1. 数据下载
哈工大同义词词林扩展版官网:https://www.ltp-cloud.com/download/#down_cilin
注册账户之后会看到下载链接和密码(z55c)
我在linux下打开文件出现乱码,需要用iconv命令进行转码(参考本人前面的文章Linux下打开windows中文文本乱码问题)
如果文件中因存在不能识别的字符导致转码失败,用gedit打开并把那一行的非法字符删除就可以了。原有17817行,转码之后我保留了17815行。
(本来想贴到这里来的,但因为包含了gongchandang, jiangzemin, dalai, qietingqi等等,博客园会报错“Post operation failed. The error message related to this problem was as follows: 博文中含有违规内容: xxx!”......)
2. 数据处理和应用
在哈工大的同义词词林中,由于它给词分了类别,同一个词在不同的类别下可能会有不同的同义词,例如“男人”的同义词有:
Ab01A01= 男人 男子 男子汉 男儿 汉子 汉 士 丈夫 官人 男人家 光身汉 须眉 壮汉 男士
Ah08A01= 夫 丈夫 爱人 男人 先生 女婿 老公 汉子 当家的 人夫 那口子
为方便后续的应用,这里把这两行的词都合并到“男人”的同义词列表中,并在词后面加上type(=或者#),方便区分同义词与近义词,生成字典{词type: 同义词列表},例如:
{"毛乎乎=": ["糙", "毛糙", "麻", "毛", "粗糙"], "车次#": ["等次", "名次", "班次", "航次", "场次"]}
代码如下:
def get_kw2similar_words(fin, fout):
kw2similar_words = defaultdict(set) # 去重
with codecs.open(fin, "r", "utf-8") as fr:
for idx, line in enumerate(fr):
try:
row = line.strip().split(" ")
if row[0][-1] == u"@": continue
for kw in row[1:]:
row.remove(kw)
kw_and_type = kw + row[0][-1]
kw2similar_words[kw_and_type].update(row[1:])
row.insert(-1, kw)
except Exception as error:
print "Error line", idx, line, error
if idx % 1000 == 0: print idx
for kw, similar_words in kw2similar_words.iteritems():
kw2similar_words[kw] = list(similar_words) # kw2similar_words = defaultdict(list)
json.dump(kw2similar_words, open(fout, "w"), ensure_ascii=False) get_kw2similar_words(fin="data/cilin.txt", fout="data/kw2similar_words.json")
测试:
if __name__ == '__main__':
kw2similar_words = json.load(open("data/kw2similar_words.json", "r"))
keys_set = set(kw2similar_words.keys())
kws = [u"群众", u"男人", u"女人", u"国王", u"皇后"]
for kw in kws:
for kw_and_type in [kw + u"=", kw + u"#"]:
if kw_and_type in keys_set:
print kw_and_type, "/".join(kw2similar_words[kw_and_type]) """
群众= 大众/万众/民众/公众/众生/千夫
男人= 男人家/爱人/女婿/先生/壮汉/汉/汉子/士/人夫/男士/老公/那口子/官人/丈夫/男子汉/男子/男儿/当家的/光身汉/须眉/夫
女人= 妇道/太太/妇/老婆/娘/娘子/女人家/红装/妻子/女儿/媳妇儿/老婆子/内/家/婆姨/妻/女性/巾帼/婆娘/家庭妇女/娘儿们/女子/小娘子/妻妾/老小/娘子军/农妇/女郎/才女/妻室/妇女/半边天/内助/贤内助/石女/爱妻/爱人/家里/妇人/女士/女/老伴/夫人
国王= 可汗/王/上/沙皇/至尊/君王/君/帝/帝王/主公/圣上/五帝/君主/大帝/国君/天王/单于/统治者/天骄/天皇/九五/九五之尊/皇帝/陛下/皇上/王者/天子/当今/太岁
皇后= 娘娘/王后
"""
3. 中文同义词近义词的其它在线词典
词林在线词典 http://www.cilin.org/
同义词库 http://chinese.abcthesaurus.com/
参考:
【中文同义词近义词】词向量 vs 同义词近义词库的更多相关文章
- 【Lucene3.6.2入门系列】第05节_自定义停用词分词器和同义词分词器
首先是用于显示分词信息的HelloCustomAnalyzer.java package com.jadyer.lucene; import java.io.IOException; import j ...
- 词嵌入向量WordEmbedding
词嵌入向量WordEmbedding的原理和生成方法 WordEmbedding 词嵌入向量(WordEmbedding)是NLP里面一个重要的概念,我们可以利用WordEmbedding将一个单 ...
- elasticsearch高亮之词项向量
一.什么是词项向量 词项向量(term vector)是有elasticsearch在index document的时候产生,其包含对document解析过程中产生的分词的一些信息,例如分词在字段值中 ...
- 机器学习入门-文本特征-word2vec词向量模型 1.word2vec(进行word2vec映射编码)2.model.wv['sky']输出这个词的向量映射 3.model.wv.index2vec(输出经过映射的词名称)
函数说明: 1. from gensim.model import word2vec 构建模型 word2vec(corpus_token, size=feature_size, min_count ...
- DeepNLP的核心关键/NLP词的表示方法类型/NLP语言模型 /词的分布式表示/word embedding/word2vec
DeepNLP的核心关键/NLP语言模型 /word embedding/word2vec Indexing: 〇.序 一.DeepNLP的核心关键:语言表示(Representation) 二.NL ...
- NLP基础——词集模型(SOW)和词袋模型(BOW)
(1)词集模型(Set Of Words): 单词构成的集合,集合自然每个元素都只有一个,也即词集中的每个单词都只有一个. (2)词袋模型(Bag Of Words): 如果一个单词在文档中出现不止一 ...
- Python 爬取 热词并进行分类数据分析-[解释修复+热词引用]
日期:2020.02.02 博客期:141 星期日 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- 机器学习入门-文本数据-构造Ngram词袋模型 1.CountVectorizer(ngram_range) 构建Ngram词袋模型
函数说明: 1 CountVectorizer(ngram_range=(2, 2)) 进行字符串的前后组合,构造出新的词袋标签 参数说明:ngram_range=(2, 2) 表示选用2个词进行前后 ...
- 纯前端实现词云展示+附微博热搜词云Demo代码
前言 最近工作中做了几个数据可视化大屏项目,其中也有用到了词云展示,以前做词云都是用python库来生成图片显示的,这次用了纯前端的实现(Ctrl+V真好用),同时顺手做个微博热搜的词云然后记录一下~ ...
随机推荐
- An Example for Javascript Function Scoping and Closure
1. An Real World Example In the patron detail page of the CRM system I'm working with, there’re larg ...
- maven问题:如何启动maven项目
maven是项目构建工具,用于解决jar间的依赖,启动maven项目的命令:tomcat:run 步骤如下: 1.在pom.xml文件中配置插件,此处配置的是tomcat8 2.右击项目名,找到Run ...
- How To Use Coordinates To Extract Sequences In Fasta File
[1] bedtools (https://github.com/arq5x/bedtools2) here is also bedtools (https://github.com/arq5x/be ...
- shiro对事务的影响
记一个 No transaction aspect-managed TransactionStatus in scope 错误的解决方法 昨天出现一个BUG,事务没有加回滚成功,修改管理员密码事务没有 ...
- scala(一)方法&函数
写在前面 众所周知,scala一向宣称自己是面向函数的编程,(java表示不服,我是面向bean的编程!)那什么是函数? 在接触java的时候,有时候用函数来称呼某个method(实在找不出词了),有 ...
- Docker 推送镜像到 阿里Docker镜像
登录 阿里云Docker镜像 https://cr.console.aliyun.com 创建一个镜像 成功之后点击 “管理” 阿里有详细的 使用说明 PS : 注意的地方是 sudo docker ...
- 51Nod 1433 0和5(9的倍数理论)
http://www.51nod.com/onlineJudge/questionCode.html#!problemId=1433 思路: 数论中关于9的倍数的理论:若是一个数能被9整除,则各位数之 ...
- 《用 Python 学微积分》笔记 1
<用 Python 学微积分>原文见参考资料 1. 1.多项式 f(x)=x3-5x2+9 def f(x): return x**3 - 5*x**2 + 9 print f(3) pr ...
- .net的根目录区别
很久没搞.net了,时间一场,全忘记了,倒,,, “~/” 是应用程序根目录“/” 也是表示根目录 “./” 是当前目录“../”表示当前目录的上一级目录
- 英语每日阅读---8、VOA慢速英语(翻译+字幕+讲解):脸肓症患者记不住别人的脸
英语每日阅读---8.VOA慢速英语(翻译+字幕+讲解):脸肓症患者记不住别人的脸 一.总结 一句话总结: a.neural abnormalities are more widespread:Duc ...