【转载】Beautiful Soup库(bs4)入门
from bs4 import BeautifulSoup
import requests
r = requests.get('http://www.23us.so/')
html = r.text
soup = BeautifulSoup(html,'html.parser')
print soup.prettify()
from bs4 import BeautifulSoup
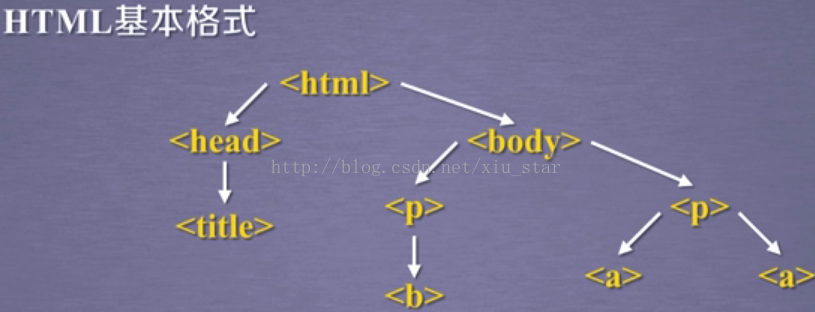
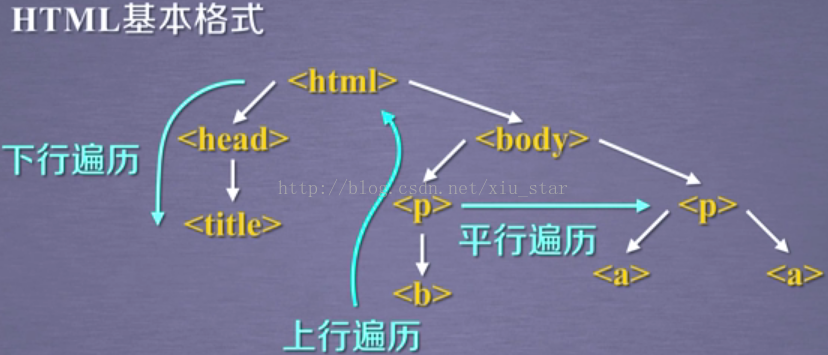
标签树的下行遍历:
- .contents属性:子节点的列表,将<tag>所有儿子节点存入列表
- .children属性:子节点的迭代类型,与.contents类似,用于循环遍历儿子节点
- .descendants属性:子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
from bs4 import BeautifulSoup #beautifulsoup4库使用时是简写的bs4
import requests
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo,'html.parser') #解析器:html.parser
child = soup.body.contents
print(child)
for child in soup.body.descendants:
print(child)
- .parent属性:节点的父标签
- parents属性:节点先辈标签的迭代类型,用于循环遍历先辈节点


from bs4 import BeautifulSoup #beautifulsoup4库使用时是简写的bs4
import requests
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo,'html.parser') #解析器:html.parser
print(soup.prettify()) #打印解析好的内容
from bs4 import BeautifulSoup


标签树的下行遍历:
- .contents属性:子节点的列表,将<tag>所有儿子节点存入列表
- .children属性:子节点的迭代类型,与.contents类似,用于循环遍历儿子节点
- .descendants属性:子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
import requests
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo,'html.parser') #解析器:html.parser
child = soup.body.contents
print(child)
for child in soup.body.descendants:
- .parent属性:节点的父标签
- parents属性:节点先辈标签的迭代类型,用于循环遍历先辈节点
【转载】Beautiful Soup库(bs4)入门的更多相关文章
- Beautiful Soup库入门
1.安装:pip install beautifulsoup4 Beautiful Soup库是解析.遍历.维护“标签树”的功能库 2.引用:(1)from bs4 import BeautifulS ...
- Beautiful Soup库基础用法(爬虫)
初识Beautiful Soup 官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/# 中文文档:https://www.crumm ...
- Python Beautiful Soup库
Beautiful Soup库 Beautiful Soup库:https://www.crummy.com/software/BeautifulSoup/ 安装Beautiful Soup: 使用B ...
- crawler碎碎念4 关于python requests、Beautiful Soup库、SQLlite的基本操作
Requests import requests from PIL import Image from io improt BytesTO import jason url = "..... ...
- 【Python爬虫学习笔记(3)】Beautiful Soup库相关知识点总结
1. Beautiful Soup简介 Beautiful Soup是将数据从HTML和XML文件中解析出来的一个python库,它能够提供一种符合习惯的方法去遍历搜索和修改解析树,这将大大减 ...
- python beautiful soup库的超详细用法
原文地址https://blog.csdn.net/love666666shen/article/details/77512353 参考文章https://cuiqingcai.com/1319.ht ...
- python之Beautiful Soup库
1.简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索 ...
- Beautiful Soup库介绍
开始前需安装Beautiful Soup 和lxml. Beautiful Soup在解析时依赖解析器,下表列出bs4支持的解析器. 解析器 使用方法 Python标准库 BeautifulSoup( ...
- Beautiful Soup库
原文传送门:静觅 » Python爬虫利器二之Beautiful Soup的用法
随机推荐
- 洛谷 3201 [HNOI2009]梦幻布丁 解题报告
3201 [HNOI2009]梦幻布丁 题目描述 \(N\)个布丁摆成一行,进行\(M\)次操作.每次将某个颜色的布丁全部变成另一种颜色的,然后再询问当前一共有多少段颜色.例如颜色分别为\(1,2,2 ...
- Linux内核分析第五周学习总结——分析system_call中断处理过程
Linux内核分析第五周学习总结--分析system_call中断处理过程 zl + <Linux内核分析>MOOC课程http://mooc.study.163.com/course/U ...
- python基础(5)
使用dict和set dict Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度. 举个例子 ...
- 常用Actoin算子 与 内存管理 、共享变量、内存机制
一.常用Actoin算子 (reduce .collect .count .take .saveAsTextFile . countByKey .foreach ) collect:从集群中将所有的计 ...
- 在VS2010中使用Git【图文】
http://blog.csdn.net/laogong5i0/article/details/10974285 在之前的一片博客<Windows 下使用Git管理Github项目>中简单 ...
- selenium - webdriver - 截图方法get_screenshot_as_file()
WebDriver提供了截图函数get_screenshot_as_file()来截取当前窗口. from selenium import webdriver from time import sle ...
- Hdu1542 Atlantis
Atlantis Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Su ...
- bzoj 2081 [Poi2010]Beads hash+调和级数
2081: [Poi2010]Beads Time Limit: 10 Sec Memory Limit: 259 MBSubmit: 1003 Solved: 334[Submit][Statu ...
- 修改Tomcat端口
1.自己的tomcat修改端口号,在tomcat解压缩目录中conf目录下又一个server.xml,将HTTP协议的端口修改为自己想要的即可 <Connector port="808 ...
- JNI实现JAVA和C++互相调用
SDK.h #ifndef SDK_H #define SDK_H #include "AsyncProxy.h" #include "Module.h" #i ...