HDFS的常用操作
本文地址:http://www.cnblogs.com/archimedes/p/hdfs-operations.html,转载请注明源地址。
1、HDFS文件的权限以及读写操作
HDFS文件的权限:
•与Linux文件权限类似
•r: read; w:write; x:execute,权限x对于文件忽略,对于文件夹表示是否允许访问其内容
•如果Linux系统用户zhangsan使用hadoop命令创建一个文件,那么这个文件在HDFS中owner就是zhangsan
•HDFS的权限目的:阻止好人错错事,而不是阻止坏人做坏事。HDFS相信,你告诉我你是谁,我就认为你是谁
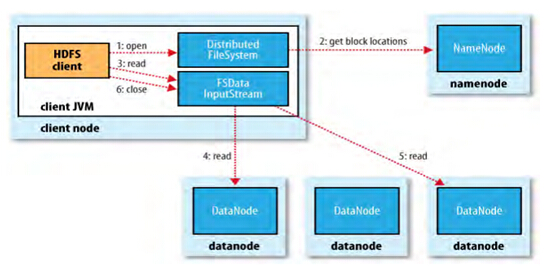
HDFS文件的读取:
HDFS文件的写入:

HDFS文件存储:
两个文件,一个文件156M,一个文件128在HDFS里面怎么存储?
--Block为64MB
--rapliction默认拷贝3份
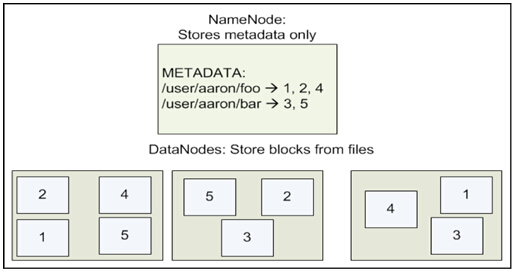
HDFS文件存储结构:
2、HDFS下的文件操作
1、列出HDFS文件
通过“-ls”命令列出HDFS下的文件
wu@ubuntu:~/opt/hadoop-0.20.$ bin/hadoop dfs -ls
执行结果如图:

注意:在HDFS中未带参数的“-ls”命令没有返回任何值,它默认返回HDFS的“home”目录下的内容。在HDFS中,没有当前工作目录这样的概念,也没有cd这个命令
2、列出HDFS目录下某个文档中的文件
此处展示的是“-ls 文件名”命令浏览HDFS下名为in的文档中的文件
wu@ubuntu:~/opt/hadoop-0.20.$ bin/hadoop dfs -ls in

3、上传文件到HDFS
此处展示的是“-put 文件1 文件2”命令将hadoop-0.20.2目录下的test1文件上传到HDFS上并重命名为test
wu@ubuntu:~/opt/hadoop-0.20.$ bin/hadoop dfs -put test1 test
注意:在执行“-put”时只有两种可能,即是执行成功和执行失败。在上传文件时,文件首先复制到DataNode上,只有所有的DataNode都成功接收完数据,文件上传才是成功的。
4、将HDFS中的文件复制到本地系统中
此处展示的是“-get 文件1 文件2”命令将HDFS中的in文件复制到本地系统并命名为getin:
wu@ubuntu:~/opt/hadoop-0.20.$ bin/hadoop dfs -get in getin
5、删除HDFS下的文档
此处展示的是“-rmr 文件”命令删除HDFS下名为out的文档:
wu@ubuntu:~/opt/hadoop-0.20.$ bin/hadoop dfs -rmr out
执行命令后,查看只剩下一个in文件,删除成功:

6、查看HDFS下的某个文件
此处展示的是“-cat 文件”命令查看HDFS下in文件中的内容:
wu@ubuntu:~/opt/hadoop-0.20.$ bin/hadoop dfs -cat in/*
输出:
hello world
hello hadoop
PS:bin/hadoop dfs 的命令远不止这些,但是本文的这些命令很实用,对于其他的操作,可以通过“-help commandName”命令所列出的清单来进一步的学习
3、管理与更新
1、报告HDFS的基本统计信息
通过“-report”命令查看HDFS的基本统计信息:
wu@ubuntu:~/opt/hadoop-0.20.$ bin/hadoop dfsadmin -report
执行结果如下所示:
14/12/02 05:19:05 WARN conf.Configuration: DEPRECATED: hadoop-site.xml found in the classpath. Usage of hadoop-site.xml is deprecated. Instead use core-site.xml, mapred-site.xml and hdfs-site.xml to override properties of core-default.xml, mapred-default.xml and hdfs-default.xml respectively
Configured Capacity: 19945680896 (18.58 GB)
Present Capacity: 13558165504 (12.63 GB)
DFS Remaining: 13558099968 (12.63 GB)
DFS Used: 65536 (64 KB)
DFS Used%: 0%
Under replicated blocks: 1
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Datanodes available: 1 (1 total, 0 dead)
Name: 127.0.0.1:50010
Decommission Status : Normal
Configured Capacity: 19945680896 (18.58 GB)
DFS Used: 65536 (64 KB)
Non DFS Used: 6387515392 (5.95 GB)
DFS Remaining: 13558099968(12.63 GB)
DFS Used%: 0%
DFS Remaining%: 67.98%
Last contact: Tue Dec 02 05:19:04 PST 2014
2、退出安全模式
NameNode在启动时会自动进入安全模式。安全模式是NameNode的一种状态,在这个阶段,文件系统不允许有任何的修改。安全模式的目的是在系统启动时检查各个DataNode
上数据块的有效性,同时根据策略对数据块进行必要的复制和删除,当数据块的最小百分比数满足配置的最小副本数条件时,会自动退出安全模式。
wu@ubuntu:~/opt/hadoop-0.20.$ bin/hadoop dfsadmin -safemode leave
3、进入安全模式
wu@ubuntu:~/opt/hadoop-0.20.$ bin/hadoop dfsadmin -safemode enter
4、添加节点
可扩展性是HDFS的一个重要的特性,向HDFS集群中添加节点是很容易实现的。添加一个新的DataNode节点,首先在新加的节点上安装好hadoop,要和NameNode使用相同的配置,修改HADOOP_HOME/conf/master文件,加入NameNode主机名。然后在NameNode节点上修改HADOOP_HOME/conf/slaves文件,加入新节点主机名。再建立到新节点无密码SSH连接,运行启动命令:
$ bin/start-all.sh
通过http://(主机名):50070可查看到新的DataNode节点添加成功
5、负载均衡
用户可以使用下面的命令来重新平衡DataNode上的数据块的分布:
$ bin/start-balancer.sh
参考资料
《实战Hadop:开启通向云计算的捷径.刘鹏》
HDFS的常用操作的更多相关文章
- Hadoop HDFS文件常用操作及注意事项
Hadoop HDFS文件常用操作及注意事项 1.Copy a file from the local file system to HDFS The srcFile variable needs t ...
- Spark环境搭建(二)-----------HDFS shell 常用操作
配置好HDFS,也学习了点HDFS的简单操作,跟Linux命令相似 1) 配置Hadoop的环境变量,类似Java的配置 在 ~/.bash_profile 中加入 export HADOOP_HO ...
- 读Hadoop3.2源码,深入了解java调用HDFS的常用操作和HDFS原理
本文将通过一个演示工程来快速上手java调用HDFS的常见操作.接下来以创建文件为例,通过阅读HDFS的源码,一步步展开HDFS相关原理.理论知识的说明. 说明:本文档基于最新版本Hadoop3.2. ...
- Hadoop HDFS文件常用操作及注意事项(更新)
1.Copy a file from the local file system to HDFS The srcFile variable needs to contain the full name ...
- [b0002] Hadoop HDFS cmd常用命令练手
目的: 学会HDFS CLI 常用操作 环境: Hadoop 2.6.4 伪分布式版 环境搭建参考本博客前篇文章: 伪分布式 hadoop 2.6.4 帮助: hadoop@ssmaster:~$ h ...
- Hdfs常用操作
一.linux rm是删除,不是del 二.常用操作 package hdfs; import java.io.FileInputStream; import java.io.FileNotFound ...
- HDFS Java API 常用操作
package com.luogankun.hadoop.hdfs.api; import java.io.BufferedInputStream; import java.io.File; impo ...
- Hadoop2.7.6_02_HDFS常用操作
1. HDFS常用操作 1.1. 查询 1.1.1. 浏览器查询 1.1.2. 命令行查询 [yun@mini04 bin]$ hadoop fs -ls / 1.2. 上传文件 [yun@mini ...
- 三、hdfs的JavaAPI操作
下文展示Java的API如何操作hdfs,在这之前你需要先安装配置好hdfs https://www.cnblogs.com/lay2017/p/9919905.html 依赖 你需要引入依赖如下 & ...
随机推荐
- U3D 基础
千里之行,始于足下! 最先执行的方法是:1.(激活时的初始代码)Awake2.Start3.Update(FixUpdate,LateUpdate)4.渲染模块(OnGUI)5.再向后,就是卸载模块( ...
- Node.js后台开发初体验
Node.js是什么 Node.js是一个Javascript运行环境(runtime),发布于2009年5月,由Ryan Dahl开发,实质时对Chrome V8引擎进行了封装 Node.js安装 ...
- 创建操作表(UIActionSheet)
UIActionSheet用来创建一个操作表,它的初始化代码如下: - (IBAction)testActionSheet:(id)sender { UIActionSheet *actionShee ...
- python魔法方法-自定义序列详解
自定义序列的相关魔法方法允许我们自己创建的类拥有序列的特性,让其使用起来就像 python 的内置序列(dict,tuple,list,string等). 如果要实现这个功能,就要遵循 python ...
- Python 面向对象编程——初见
<什么是面向对象> 面向对象编程(Object Oriented Programming),简称OOP,是一种程序设计思想.OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的 ...
- HDU4893【线段树单点、区间更新】
题目链接[http://acm.hdu.edu.cn/showproblem.php?pid=4893] 题意:输入n.q.表示有n个数,初始化默认这n个数都为零,有q次操作,操作种类分为三种:1.输 ...
- 矩阵乘法<简单总结>
原理:矩阵相乘最重要的方法是一般矩阵乘积.它只有在第一个矩阵的 行数 和第二个矩阵的 列数 相同时才可进行.若A为m×n矩阵,B为n×p矩阵,则他们的乘积AB会是一个m×p矩阵. 若A= a ...
- 「CSA49」Card Collecting Game
「CSA49」Card Collecting Game 题目大意:有 \(n\) 种卡片,每种有 \(b_i\) 张,如果一个人集齐 \(k\) 张第 \(i\) 种卡片,那么其能获得的得分是 \(\ ...
- bzoj 2055: 80人环游世界 -- 上下界网络流
2055: 80人环游世界 Time Limit: 10 Sec Memory Limit: 64 MB Description 想必大家都看过成龙大哥的<80天环游世界>,里面 ...
- 快速排序及查找第K个大的数。
本文提供了一种基于分治法思想的,查找第K个大的数,可以使得时间复杂地低于nlogn. 因为快排的平均时间复杂度为nlogn,但是快排是全部序列的排序, 本文查找第k大的数,则不必对整个序列进行排序.请 ...