hand first python 选读(2)
文件读取与异常
文件读取与判断
os模块是调用来处理文件的。
先从最原始的读取txt文件开始吧!
新建一个aaa.txt文档,键入如下英文名篇:
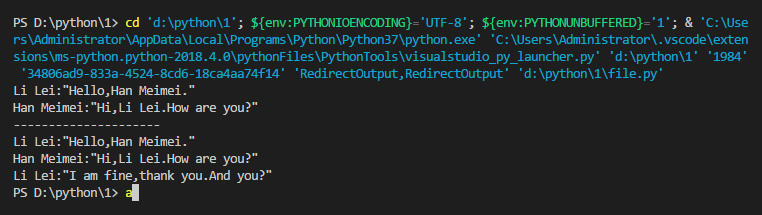
Li Lei:"Hello,Han Meimei."
Han Meimei:"Hi,Li Lei.How are you?"
Li Lei:"I am fine,thank you.And you?"
同目录下创建一个新的file.py文档
import os
os.getcwd()
data=open('aaa.txt')
# 打开文件
print(data.readline(),end='')
# 读取文件
print(data.readline(), end='')
data.seek(0)
# 又回到最初的起点
for line in data:
print(line,end='')
结果如下
如果文件不存在怎么办?
import os
if os.path.exists('aaa.txt'):
# 业务代码
else:
print('error:the file is not existed.')
split切分
现在我们要把这个桥段转化为第三人称的形式
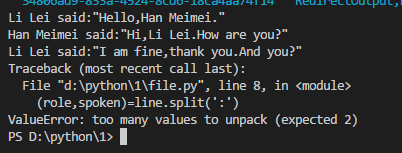
for line in data:
(role,spoken)=line.split(':')
print(role,end='')
print(' said:',end='')
print(spoken,end='')
这里是个极其简单对话区分。如果我把对话稍微复杂点
。。。
Han Meimei:"There is a question:shall we go to the bed together?"
(pause)
Li Lei:"Oh,let us go to the bed together!"
关键时刻岂可报错。
首先发现问题出在冒号,split方法允许第二个参数.
以下实例展示了split()函数的使用方法:
#!/usr/bin/python str = "Line1-abcdef \nLine2-abc \nLine4-abcd";
print str.split( );
print str.split(' ', 1 );以上实例输出结果如下:
['Line1-abcdef', 'Line2-abc', 'Line4-abcd']
['Line1-abcdef', '\nLine2-abc \nLine4-abcd']
data = open('aaa.txt')
# 打开文件
for line in data:
(role,spoken)=line.split(':',1)
print(role,end='')
print(' said:',end='')
print(spoken,end='')
取反:not
结果pause解析不了。每一行做多一个判断。取反用的是not方法,查找用的是find方法。
Python find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。
find()方法语法:
str.find(str, beg=0, end=len(string))
考虑这样写
for line in data:
if not line.find(':')==-1:
(role,spoken)=line.split(':',1)
print(role,end='')
print(' said:',end='')
print(spoken,end='')
data.close()
关注代码本身的目的功能:try...except...捕获处理异常
剧本里的对话千差万别,而我只想要人物的对话。不断增加代码复杂度是绝对不明智的。
python遇到代码错误会以traceback方式告诉你大概出了什么错,并中断处理流程(程序崩了!)。
而try...except...类似try...catch语法,允许代码中的错误发生,不中断业务流程。
在上述业务代码中我想统一忽略掉所有
只显示
木有冒号的文本行
可以 这么写:
for line in data:
try:
(role,spoken)=line.split(':',1)
print(role,end='')
print(' said:',end='')
print(spoken,end='')
except:
pass
pass是python中的null语句,理解为啥也不做。
通过这个语法,忽略处理掉了所有不必要的复杂逻辑。
复杂系统中,aaa.txt可能是不存在的,你固然可以用if 读取,还有一个更激进(先进)的写法:
import os
try:
data = open('aaa.txt')
# 打开文件
for line in data:
try:
(role,spoken)=line.split(':',1)
print(role,end='')
print(' said:',end='')
print(spoken,end='')
except:
pass
except:
print('error:could not read the file.')
两种逻辑是不一样的,上述是无法读取(可能读取出错),if是路径不存在。于是引发了最后一个问题。
错误类型指定
过于一般化的代码,总是不能很好地判断就是是哪出了错。try语句无法判断:究竟是文件路径不对还是别的问题
import os
try:
data = open('aaa.txt')
# 打开文件
for line in data:
try:
(role,spoken)=line.split(':',1)
print(role,end='')
print(' said:',end='')
print(spoken,end='')
except ValueError:
# 参数出错
pass
except IOError:
# 输入输出出错
print('error:could not find the file.')
python中异常对象有很多,可自行查阅。
数据不符合期望格式:ValueError
IOError:路径出错
数据储存到文件
业务代码工作流程可以储存到文件中保存下来。下面先看一个需求:
- 分别创建一个名为lilei和hanmeimei的空列表
- 删除一个line里面的换行符(replace方法和js中几乎一样。去除左右空格用
strip方法)- 给出条件和代码,根据role的值将line添加到适当的列表中
- 输出各自列表。
简单说就是一个条件查询的实现。
try:
data = open('aaa.txt')
lilei = []
hanmeimei = []
for line in data:
try:
(role, spoken) = line.split(':', 1)
spoken = spoken.replace('\n', '')
if role == 'Li Lei':
lilei.append(spoken)
else:
hanmeimei.append(spoken)
except ValueError:
pass
data.close()
except IOError:
print('error:the file is not found.')
print(lilei)
print(hanmeimei)
很简单。
写模式:open('bbb.txt',w')
open方法默认为读模式open('bbb.txt','r'),写模式对因为open('bbb.txt','w')。
在同目录下创建一个bbb.txt
写入文件可以用以下命令:
out = open('bbb.txt', 'w')
print('we are who we are.', file=out)
out.close()
| 文件访问模式 | 释义 |
|---|---|
| r | 读取,是为默认模式 |
| w | 打开一个文件,覆写文件内容,如没有则创建。 |
| w+ | 读取和追加写入(不清除) |
| a | 追加写入 |
打开的文件必须运行关闭!
好了,介绍完知识之后可以在上一节代码中分别写入文件吧
try:
data = open('aaa.txt')
lilei = []
hanmeimei = []
for line in data:
try:
(role, spoken) = line.split(':', 1)
spoken = spoken.strip()
if role == 'Li Lei':
lilei.append(spoken)
else:
hanmeimei.append(spoken)
except ValueError:
pass
data.close()
try:
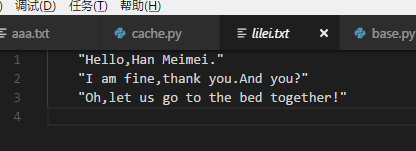
_lilei = open('lilei.txt', 'w')
_hanmeimei = open('hanmeimei.txt', 'w')
print(lilei,file=_lilei)
print(hanmeimei,file=_hanmeimei)
_lilei.close()
_hanmeimei.close()
print('works completed.')
except IOError:
print('file error.')
except IOError:
print('error:the file is not found.')
测试成功,但以上代码有个问题:我需要无论IOError都运行一套代码。并且在文件创建后关闭
扩展try语句
当我尝试以read模式打开一个文件,:
try:
data = open('lilei.txt')
except IOError as err:
print('file error.'+str(err))
finally:
if 'data' in locals():
_lilei.close()
print('works completed.')
- finally:无论是否运行成功都执行的代码。
- locals():告诉你文件是否成功被创建并打开。
- as xxx:为异常对象命名,并且通过str()转化为字符以便打印,也是一个赋值过程
实在太麻烦了。
with语句
with语句利用了一个上下文管理协议。有了它就不用些finally了。
目前为止条件查找的方案是这样的
# ...
try:
_lilei = open('lilei.txt','w')
_hanmeimei = open('hanmeimei.txt','w')
print(lilei, file=_lilei)
print(hanmeimei, file=_hanmeimei)
except IOError as err:
print('file error.'+str(err))
finally:
if '_lilei' in locals():
_lilei.close()
if '_hanmeimei' in locals():
_hanmeimei.close()
print('works completed.')
except IOError:
print('error:the file is not found.')
用with重写之后:
try:
with open('lilei.txt','w') as _lilei:
print(lilei, file=_lilei)
with open('hanmeimei.txt','w') as _hanmeimei:
print(hanmeimei, file=_hanmeimei)
print('works completed.')
except IOError as err:
print('file error.'+str(err))
写好之后就非常简洁了。
因地制宜选择输出样式
对于列表数据来说,直接存字符串是很不合适的。现在我要把第二章中的flatten加进来并加以改造。
# base.py
def flatten(_list, count=False, level=0):
if(isinstance(_list, list)):
for _item in _list:
flatten(_item,count,level+1)
else:
if count:
for step in range(level):
print("\t", end='')
print(_list)
else:
print(_list)
需求:向flatten添加第四个参数,标识数据写入的位置,并允许缺省。
# base.py
def flatten(_list, count=False, level=0,_file=False):
if(isinstance(_list, list)):
for _item in _list:
flatten(_item,count,level+1,_file)
else:
if count:
for step in range(level):
print("\t", end='',file=_file)
print(_list,file=_file)
else:
print(_list)
调用
import base as utils
try:
data = open('aaa.txt')
lilei = []
hanmeimei = []
for line in data:
try:
(role, spoken) = line.split(':', 1)
spoken = spoken.strip()
if role == 'Li Lei':
lilei.append(spoken)
else:
hanmeimei.append(spoken)
except ValueError:
pass
data.close()
try:
with open('lilei.txt','w') as _lilei:
utils.flatten(lilei,True,0,_lilei)
with open('hanmeimei.txt','w') as _hanmeimei:
utils.flatten(hanmeimei, True, 0, _hanmeimei)
print('works completed.')
except IOError as err:
print('file error.'+str(err))
except IOError:
print('error:the file is not found.')
输出成功
把格局拉高点吧,这仍然是一个高度定制化的代码。
pickle库的使用
pickle库介绍
pickle是python语言的一个标准模块,安装python后已包含pickle库,不需要单独再安装。
pickle模块实现了基本的数据序列化和反序列化。通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
一、内存中操作:
import pickle
#dumps 转化为二进制文件
li = [11,22,33]
r = pickle.dumps(li)
print(r) #loads 将二进制数据编译出来
result = pickle.loads(r)
print(result)
二、文件中操作:
#dump:以二进制形式打开(读取:rb,写入wb)文件
li = [11,22,33]
pickle.dump(li,open('db','wb')) #load
ret = pickle.load(open('db','rb'))
print(ret)
把二进制文件写入文件中:
try:
with open('lilei.txt','wb') as _lilei:
# utils.flatten(lilei,True,0,_lilei)
pickle.dump(lilei,_lilei)
with open('hanmeimei.txt','wb') as _hanmeimei:
# utils.flatten(hanmeimei, True, 0, _hanmeimei)
pickle.dump(hanmeimei,_hanmeimei)
print('works completed.')
except IOError as err:
print('file error.'+str(err))
except pickle.PickleError as pError:
print('err:'+str(pError))
数据已经被写入。

举例说:如何打开lileii.txt并正确编译呢?
new_lilei=[]
try:
with open('lilei.txt','rb') as _new_lilei:
new_lilei = pickle.load(_new_lilei)
print(utils.flatten(new_lilei))
except IOError as io:
print('err:'+str(io))
except pickle.PickleError as pError:
print('pickleError'+str(pError))
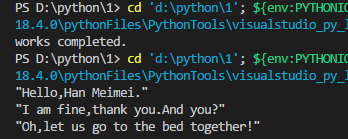
测试成功。
用pickle的通用io才是上策。
hand first python 选读(2)的更多相关文章
- head first python选读(5)
python web 开发 犯了低级错误,这本书看了一半了才知道书名应为<head first python>,不是hand first.. 现在开始一个web应用. 总算是熟悉的内容了. ...
- hand first python 选读(1)
列表(list) 基本操作 比如说我要整理一个近期热映的电影列表: movies = ["venom", "My Neighbor Totor", " ...
- python之进程与线程
什么是操作系统 可能很多人都会说,我们平时装的windows7 windows10都是操作系统,没错,他们都是操作系统.还有没有其他的? 想想我们使用的手机,Google公司的Androi ...
- python之面相对象程序设计
一 面向对象的程序设计的由来 面向对象设计的由来见概述:http://www.cnblogs.com/linhaifeng/articles/6428835.html 面向对象的程序设计:路飞学院版 ...
- Python 中的实用数据挖掘
本文是 2014 年 12 月我在布拉格经济大学做的名为‘ Python 数据科学’讲座的笔记.欢迎通过 @RadimRehurek 进行提问和评论. 本次讲座的目的是展示一些关于机器学习的高级概念. ...
- Python基础-week06 面向对象编程基础
一.面向对象编程 1.面向过程 与 面向对象编程 面向过程的程序设计: 核心是 过程二字,过程指的是解决问题的步骤,即先干什么再干什么......面向过程的设计就好比精心设计好一条流水线,是一种机械式 ...
- 送书福利| Python 完全自学手册
前言 这里不讨论「能不能学,要不要学,应不应该学 Python」的问题,这里只会告诉你怎么学. 首先需要强调的是,如果 Python 都学不会,那么我建议你考虑别的行业,因为 Python 之简单,令 ...
- Python 爬虫系列
爬虫简介 网络爬虫 爬虫指在使用程序模拟浏览器向服务端发出网络请求,以便获取服务端返回的内容. 但这些内容可能涉及到一些机密信息,所以爬虫领域目前来讲是属于灰色领域,切勿违法犯罪. 爬虫本身作为一门技 ...
- Python中的多进程与多线程(一)
一.背景 最近在Azkaban的测试工作中,需要在测试环境下模拟线上的调度场景进行稳定性测试.故而重操python旧业,通过python编写脚本来构造类似线上的调度场景.在脚本编写过程中,碰到这样一个 ...
随机推荐
- 一个父亲的教育札记——leo鉴书58
由于年纪和工作的原因.绝大部分小说我都不看--没空,如今小说写的也太空.但对文笔有提高的文章我是非常关注的,知道韩寒不是由于<三重门>(我报纸也不怎么看).而是此前编辑感觉我文笔差. ...
- FAQs on Android
@1: Environment Setup Ubuntu 14.04 32bits 1. Call Requires API level 11 (current min is 8) Android. ...
- 145. Binary Tree Postorder Traversal(二叉树后序遍历)
Given a binary tree, return the postorder traversal of its nodes' values. For example:Given binary t ...
- POJ - 3648 Wedding (2-SAT 输出解决方案)
题意:有N-1对夫妇和1对新郎新娘要出席婚礼,这N对人要坐在走廊两侧.要求每对夫妇要坐在不同侧.有M对人有通奸关系,对于这一对人,不能同时坐在新娘对面(新娘新郎也可能和别人有通奸关系).求如何避免冲突 ...
- android解决setOnItemClickListener没有响应
今天遇到一种情况,抽屉式导航栏里的listView的点击事件没有响应点击事件. 查看了下,原来是因为抽屉式导航栏的fragment声明,放在了内容fragment之前,导致点击动作被内容fragmen ...
- 20145316 《Java程序设计》 课程总结
###20145316许心远<Java学习笔记(第8版)>课程总结 ##每周读书笔记链接汇总 ▪ [第一周读书笔记](http://www.cnblogs.com/xxy745214 ...
- ANE报错fix:Could not generate timestamp: Connection reset.
如果你打包ANE时候 报了:Could not generate timestamp: Connection reset. 那么很有可能你用了JDK 1.8. 解决方案一 退回到 JDK 1.7,重新 ...
- 对象转化为 xml字符串
public static string ToXml<T>(this T o) where T : new() { string retVal; using (var ms = new M ...
- Django学习笔记之Queryset的高效使用
对象关系映射 (ORM) 使得与SQL数据库交互更为简单,不过也被认为效率不高,比原始的SQL要慢. 要有效的使用ORM,意味着需要多少要明白它是如何查询数据库的.本文我将重点介绍如何有效使用 Dja ...
- FactoryBean
总结自:https://www.cnblogs.com/davidwang456/p/3688250.html Spring中有两种类型的Bean,一种是普通Bean,另一种是工厂Bean,即xxxF ...