我如何调优SQL Server查询
我是个懒人,我只想干尽可能少的活。当我干活的时候我不想太多。是,你没看错,这看起来很糟糕,作为一个DBA这很不合格。但在今天的文章里,我想给你展示下,当你想对特定查询创建索引设计时,你如何把你的工作和思考过程传达给查询优化器。听起来很有意思?嗯,那就进入我的索引调优世界吧!
有问题的查询
我们来看下列查询:
DECLARE @i INT = 999
SELECT
SalesOrderID,
SalesOrderDetailID,
CarrierTrackingNumber,
OrderQty,
LineTotal
FROM Sales.SalesOrderDetail
WHERE ProductID < @i
ORDER BY CarrierTrackingNumber
GO
如你所见,这里用了一个本地变量与一个不等于谓语来从Sales.SalesOrderDetail表来获取一些记录。当你执行那个查询,看它的执行计划时,你会发现它有一些严重的问题:

- SQL Server需要扫描Sales.SalesOrderDetail表的整个非聚集索引,因为没有支持的非聚集索引。对这个扫描,查询需要1382个逻辑读,运行时间近800毫秒。
- 查询优化器在查询计划里引入了筛选器(Filter)运算符,它进行逐行比较用来检查符合的行(ProductID < @i)
- 因为ORDER BY CarrierTrackingNumber,在执行计划里一个排序(Sort)运算符被引入。
- 排序运算符蔓延到了TempDb,因为不正确的基数计算(Cardinality Estimation)。用了带了本地变量与不等于谓语的组合,SQL Server从表的基数硬码估计30%的行。在我们的情况里估计行数是36395(121317 * 30%)。实际上查询返回120621行,这意味这排序(Sort)运算符必须蔓延到TempDb,因为请求的内存授予太小了。
现在我问你——你能改善这个查询么?你的建议是什么?休息下,想个几分钟。不修改查询本身,你如何改善这个查询?
我们来调试查询!
当然,我们要做索引相关的调整来改善。没有支持的非聚集索引,那只能是查询优化器唯一可以使用计划来运行我们的查询。但对这个指定查询,什么是好的非聚集索引呢?一般来说,我通过看搜索谓语来考虑可能的非聚集索引。在我们的例子里,搜索谓语如下:
WHERE ProductID < @i
我们请求在ProductID列过滤的行。因此我们想在那个列创建支持的非聚集索引。我们建立索引:
CREATE NONCLUSTERED INDEX idx_Test ON Sales.SalesOrderDetail(ProductID)
GO
在非聚集索引创建后,我们需要验证下改变,因此我们再次执行刚才的查询代码。结果如何捏?查询优化器并没有使用我们刚创建的非聚集索引!我们在搜索谓语上创建了支持的非聚集索引,查询优化器没有引用它?通常人们对此就无辙了。其实我们可以提示查询优化器来使用非聚集索引,来更好的理解“为什么”查询优化器没有自动选择索引:
DECLARE @i INT = 999 SELECT
SalesOrderID,
SalesOrderDetailID,
CarrierTrackingNumber,
OrderQty,
LineTotal
FROM Sales.SalesOrderDetail WITH (INDEX(idx_Test))
WHERE ProductID < @i
ORDER BY CarrierTrackingNumber
GO
当你现在看执行计划时,你会看到下列的野性——一个并行计划:
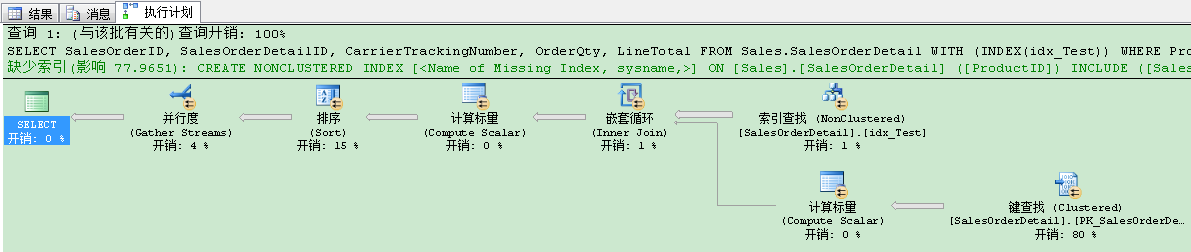

查询花费了370109个逻辑读!运行时间基本和刚才的一样。这里到底发生了什么?当你仔细看执行计划,你会发现查询优化器引入了书签查找,因为刚才创建的非聚集索引,对于查询来说,不是一个覆盖非聚集索引。查询越过了所谓的临界点(Tipping Point),因为我们用当前的搜索谓语来获得几乎所有行。因此用非聚集索引和书签查找来组合没有意义。
不去想为什么查询优化器不选择刚才创建的非聚集索引,我们已经把自己的思路表达给了查询优化器本身,通过查询提示进行了询问了查询优化器,为什么非聚集索引没被自动选择。如我刚开始说的:我不想考虑太多。
使用非聚集索引解决这个问题,在非聚集索引的叶子层,我们必须对从SELECT列表的请求的额外列进行包含。你可以再次看下书签查找来看下在叶子层哪些列当前丢失:
- CarrierTrackingNumber
- OrderQty
- UnitPrice
- UnitDiscountPrice
我们重建那个非聚集索引:
CREATE NONCLUSTERED INDEX idx_Test ON Sales.SalesOrderDetail(ProductID)
INCLUDE (CarrierTrackingNumber, OrderQty, UnitPrice, UnitPriceDiscount)
WITH
(
DROP_EXISTING = ON
)
GO
我们已经做出了另1个改变,因此我们可以重新运行了查询来验证下。但是这次我们不加查询提示,因为现在查询优化器会自动选择非聚集索引。结果如何捏?当你看执行计划时,索引现在已被选择。
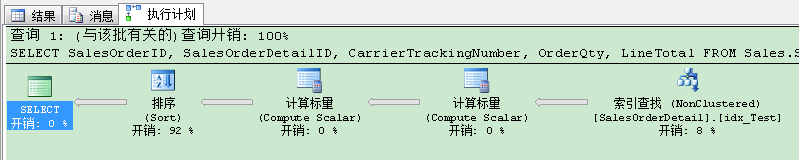

SQL Server现在在非聚集索引上进行了查找操作,但在执行计划里我们还有排序(Sort)运算符。因为基数计算30%的硬编码,排序(Sort)还是要蔓延到TempDb。偶滴神!我们的逻辑读已经降到了757,但运行时间还是近800毫秒。你现在应该怎么做?
现在我们可以尝试在非聚集索引的导航结构直接包含CarrierTrackingNumber列。这是SQL Server进行排序运算符的列。当我们在非聚集索引直接加了这列(作为主键),我们就物理排序了那列,因此排序(Sort)运算符应该会消失。作为积极的副作用,也不会蔓延到TempDb。在执行计划里,现在也没有运算符关心错误的基数计算。因此我们尝试那个假设,再次重建非聚集索引:
CREATE NONCLUSTERED INDEX idx_Test ON Sales.SalesOrderDetail(CarrierTrackingNumber, ProductID)
INCLUDE (OrderQty, UnitPrice, UnitPriceDiscount)
WITH
(
DROP_EXISTING = ON
)
GO
从索引定义可以看到,现在我们已经对CarrierTrackingNumber和ProductID列的数据物理预排序。当你再次重新执行查询,在你查看执行计划时,你会看到排序(Sort)运算符已经消失,SQL Server扫描了非聚集索引的整个叶子层(使用剩余谓语(residual predicate)作为搜索谓语)。
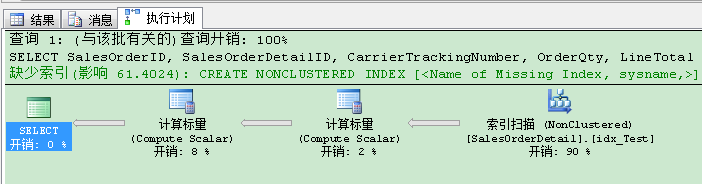

这个执行计划并不坏!我们只需要763个逻辑读,现在的运行时间已经降至600毫秒。和刚才的相比已经有25%的改善!但是:查询优化器建议我们一个更好的非聚集索引,通过缺少索引建议(Missing Index Recommendations)!暂且相信下,我们创建建议的非聚集索引:
CREATE NONCLUSTERED INDEX [SQL Server doesn't care about names, why I should care about names?]
ON [Sales].[SalesOrderDetail] ([ProductID])
INCLUDE ([SalesOrderID],[SalesOrderDetailID],[CarrierTrackingNumber],[OrderQty],[LineTotal])
GO
当你现在重新执行最初的查询,你会发现令人惊讶的事情:查询优化器使用“我们”刚才创建的非聚集索引,缺少索引建议已经消失!
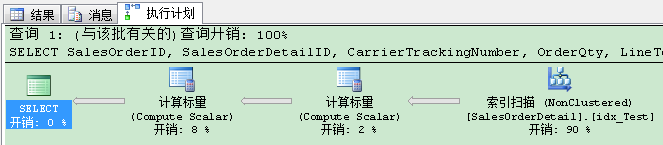
你刚刚创建了SQL Server从不使用的索引——除了INSERT,UPDATE和DELETE语句,SQL Server都要去维护你的非聚集索引。对于你的数据库,你刚创建了“单纯”浪费空间的索引。当另一方面,你已经通过消除丢失索引建议,满足了查询优化器。但这不是目的:目的是创建会被再次使用的索引。
结论:永不相信查询优化器!
小结
今天的文章有点争议性,但我想你向你展示下,但你在创建索引时,查询优化器如何帮助你,还有查询优化器如何愚弄你。因此做出小的调整,就立即运行你的查询,验证改变非常重要。还有当你使用来查询优化器的缺少索引建议时,请考虑下这个建议是个好的么。额,我已经说过——我会直接咔嚓掉。呵呵~~~
感谢关注!
参考文章:
https://www.sqlpassion.at/archive/2015/01/20/how-i-tune-sql-server-queries/
我如何调优SQL Server查询的更多相关文章
- Sql Server查询性能优化之走出索引的误区
据了解绝大多数开发人员对于索引的理解都是一知半解,局限于大多数日常工作没有机会.也什么没有必要去关心.了解索引,实在哪天某个查询太慢了找到查询条件建个索引就ok,哪天又有个查询慢了,再建立个索引就是, ...
- 调优SQL思路
--调优SQL --sqlreview ->logshipping -> ag辅助副本 --查看正确的执行计划 打开实际的执行计划set statistics io on --查看错误的执 ...
- [转] 利用SET STATISTICS IO和SET STATISTICS TIME 优化SQL Server查询性能
首先需要说明的是这篇文章的内容并不是如何调节SQL Server查询性能的(有关这方面的内容能写一本书),而是如何在SQL Server查询性能的调节中利用SET STATISTICS IO和SET ...
- SQL SERVER 查询性能优化——分析事务与锁(五)
SQL SERVER 查询性能优化——分析事务与锁(一) SQL SERVER 查询性能优化——分析事务与锁(二) SQL SERVER 查询性能优化——分析事务与锁(三) 上接SQL SERVER ...
- SQL Server 查询性能优化 相关文章
来自: SQL Server 查询性能优化——堆表.碎片与索引(一) SQL Server 查询性能优化——堆表.碎片与索引(二) SQL Server 查询性能优化——覆盖索引(一) SQL Ser ...
- 利用SET STATISTICS IO和SET STATISTICS TIME 优化SQL Server查询性能
首先需要说明的是这篇文章的内容并不是如何调节SQL Server查询性能的(有关这方面的内容能写一本书),而是如何在SQL Server查询性能的调节中利用SET STATISTICS IO和SET ...
- 如何找出你性能最差的SQL Server查询
我经常会被反复问到这样的问题:”我有一个性能很差的SQL Server.我如何找出最差性能的查询?“.因此在今天的文章里会给你一些让你很容易找到问题答案的信息向导. 问SQL Server! SQL ...
- 使用WinDbg调试SQL Server查询
上一篇文章我给你介绍了WinDbg的入门,还有你如何能附加到SQL Server.今天的文章,我们继续往前一步,我会向你展示使用WinDbg调试SQL Server查询需要的步骤.听起来很有意思?我们 ...
- sql server 查询分析器消息栏里去掉“(5 行受影响)”
sql server 查询分析器消息栏里去掉"(5 行受影响)" 在你代码的开始部分加上这个命令: set nocount on 记住在代码结尾的地方再加上: set ...
随机推荐
- 如何把.cs文件编译成DLL文件
开始--程序--Microsoft Visual Studio.NET 2013--Visual Studio.NET工具,点击其中的"VS2013 开发人员命令提示",就会进入M ...
- [Asp.net 开发系列之SignalR篇]专题二:使用SignalR实现酷炫端对端聊天功能
一.引言 在前一篇文章已经详细介绍了SignalR了,并且简单介绍它在Asp.net MVC 和WPF中的应用.在上篇博文介绍的都是群发消息的实现,然而,对于SignalR是为了实时聊天而生的,自然少 ...
- UWP的一种下拉刷新实现
简介 我们最近实现了一个在UWP中使用的下拉刷新功能,以满足用户的需求,因为这是下拉刷新是一种常见的操作方式,而UWP本身并不提供这一机制. 通过下拉刷新这一机制,可以让移动端的界面设计变得更加简单, ...
- 坑爹的BufferManager
特别记录一下 国内外各种关于 Socket 的例子或开源项目,大部分都采用了 BufferManager.cs(代码类似). 也不知道是哪一个坑货写的.有一定几率会导致内存无法复用,导致数据是上一个的 ...
- jsp模仿QQ空间说说的发表
1.在文本域中输入文字(可以不添加) 2.点击添加图片(可以不添加) 3.点击发表 4.发表成功,文字和图片是超链接,点击就可以查看全部内容 5.点击图片查看原图,没有图片则不显示查看原图的超链接 主 ...
- 运用JS设置cookie、读取cookie、删除cookie
JavaScript是运行在客户端的脚本,因此一般是不能够设置Session的,因为Session是运行在服务器端的.而cookie是运行在客户端的,所以可以用JS来设置cookie. 假设有这样一种 ...
- rabbitmq消息队列——"工作队列"
二."工作队列" 在第一节中我们发送接收消息直接从队列中进行.这节中我们会创建一个工作队列来分发处理多个工作者中的耗时性任务. 工作队列主要是为了避免进行一些必须同步等待的资源密集 ...
- WPF入门教程系列六——布局介绍与Canvas(一)
从这篇文章开始是对WPF中的界面如何布局做一个较简单的介绍,大家都知道:UI是做好一个软件很重要的因素,如果没有一个漂亮的UI,功能做的再好也无法吸引很多用户使用,而且没有漂亮的界面,那么普通用户会感 ...
- Tomcat源码阅读(二)初始化
近来,我开始阅读tomcat的源码,感觉还挺清晰易懂:为了方便理解,我参考了网上的一些文章,把tomcat的组成归纳一下:整个tomcat的组成如下图所示: Tomcat在接收到用户请求时,将会通过以 ...
- IDE:Eclipse查看Servlet源码
一.源码下载 1.打开tomcat官网:http://tomcat.apache.org/ , 点击右侧下载菜单(以tomcat-7为例)进入下载页面:http://tomcat.apache. ...