视觉语言跨模态特征语义相似度计算改进--表征空间维度语义依赖感知聚合算法 ACM MM
论文链接:Unlocking the Power of Cross-Dimensional Semantic Dependency for Image-Text Matching (ACM MM23)
代码主页:https://github.com/CrossmodalGroup/X-Dim
主要优势 (Highlights):
1)模型设计简单有效,仅改变视觉特征和文本特征之间相似度计算的 维度对应聚合方式,在基础基线SCAN上取得显著性能提升,达到SOTA;
2)理论上分析,所提出方法等价于在相似度计算过程中引入核函数,理论上可以将原始表征空间从有限的$d$维变换到无限维高维空间,使特征表示更具备可区分性;
3)在可解释性上,对表征空间中维度的语义表征倾向具有可解释性,同时所提方法能够促进更好的跨模态表征学习。
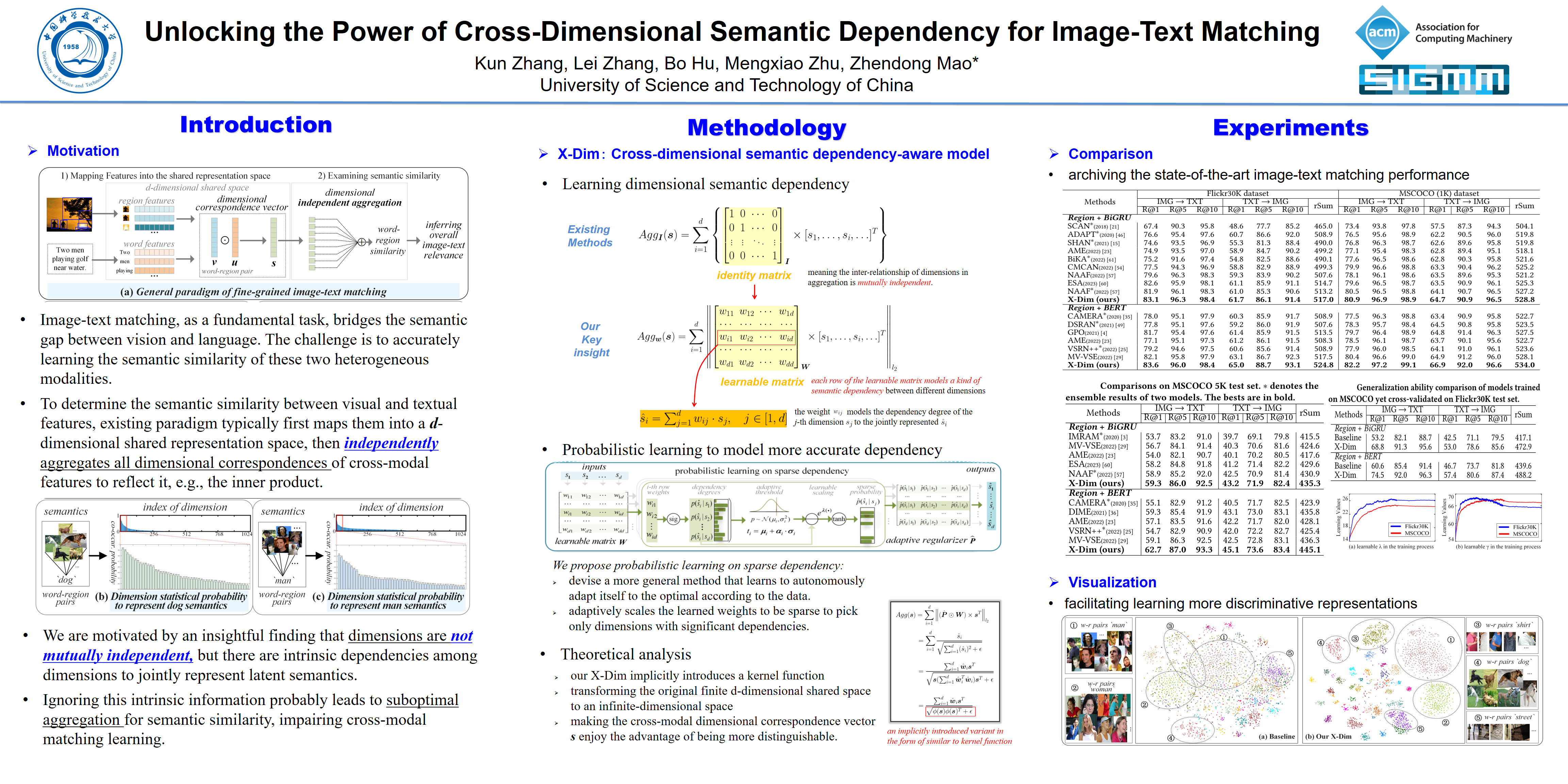
一、前言 Motivation
图像-文本关联匹配的一般范式首先是将图像和文本映射到一个共享表示空间中,然后检查这两种模态之间的语义相似程度,如图1(a)所示。基于模态表示的粒度,现有方法大致可以分为两类:全局和局部。全局方法倾向于学习整个图像和文本的整体表示,以直接测量图像-文本相似性。与粗粒度的整体表示相比,局部方法考虑显著图像区域和文本词之间的细粒度对应关系,因此通常会导致更好的性能。其关键思想是学习所有单词-区域语义相似性以获取整体图像-文本关联性,其中广为研究的交叉注意力SCAN及其变种是这一研究路线中的主流方式。对于任意单词特征$\boldsymbol{u} =\{u_i\}_{i=1}^{d}$与区域特征$\boldsymbol{v} = \{v_i\}_{i=1}^{d}$之间的语义相似性,如图1(a)所示,现有方法通常采用隐式的独立聚合来反映所有维度对应关系,即$\sum_{i=1}^{d} s_i$,其中$s_i$可以通过内积操作中的标量$v_i$和标量$u_i$的乘积确定。换言之,对于共享表示空间中跨模态对应向量$\boldsymbol{s} = \{s_i\}_{i=1}^{d}$的聚合过程,现有方法的默认假设是任一个维度$s_i$都是孤立元素,并且彼此相互独立。
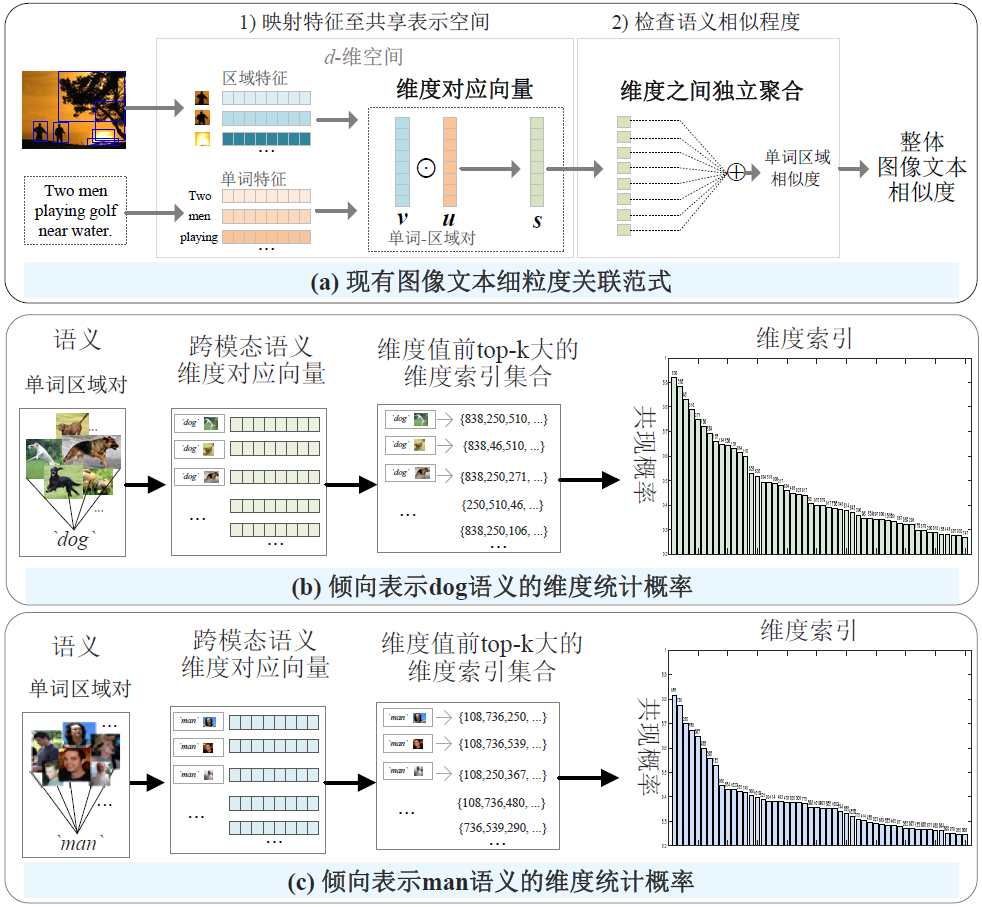
图1 跨维度语义依赖感知建模的研究动机。
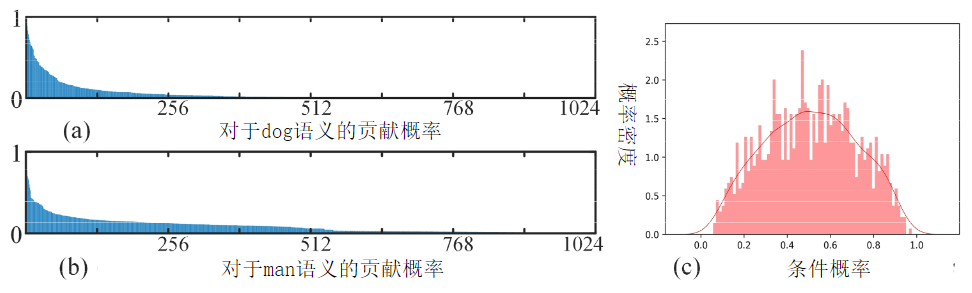
注:(a)对于在$d$维共享表示空间中映射的视觉区域和文本单词特征,可以表示为维度语义对应向量,现有的范式通常采用独立聚合方法,将所有维度对应独立聚合构成单词-区域的语义相似性。然而,如本章针对先进模型NAAF的调查实验所示,在表示空间中的维度并不是相互独立的,其中有部分维度具有显著倾向性,即统计共现概率,联合表示特定语义,例如图(b)为倾向表示语义‘dog’的维度,以及图(c)为倾向表示语义‘man’的维度。
然而,共享表示空间中的局部维度\textbf{{并非相互独立}}。为了验证这一观点,本章使用先进方法NAAF在Flickr30K测试数据集上进行了统计实验,以调查局部维度之间潜在的语义依赖性,即计算维度倾向于表达某种语义的共现概率。具体而言,对于具有相同语义的单词-区域对,其语义相似性反映在所有跨模态维度对应$s_i$的总和上,$s_i$越大,第$i$维度对该语义的贡献程度就越大。换句话说,共享空间中的第$i$维度更倾向于表示这一语义概念。例如,选取Flickr30K测试集上所有‘dog’语义的单词-区域对,本章首先获得所有跨模态语义对应向量,并收集每个向量中维度值最大的前$k$个${s_i}$的维度索引集合,即最显著反映‘dog’语义的$k$个维度($k$被设为50)。然后,本章计算维度索引的共现概率,如图1(b)所示,我们可以发现某些维度明显倾向于共同表示‘dog’的语义概念,例如索引为${838, 250, 46}$的维度,它们的共现概率超过$80\%$。类似地,对于‘man’的语义概念,如图1(c)所示,我们得到实验结果表明一些维度共享并倾向于表示这一语义。因此,共享空间中的维度并非完全独立,其中部分局部维度间存在潜在关系共同表示特定的语义,本章将其定义为跨维度语义依赖性。
我们认为现有方法通常利用维度独立聚合的方式,完全忽视了内在的依赖性,这可能会导致语义相似度和表示学习方面的局限性。首先,如图2(a)所示,在前向过程中,将维度对应聚合以构成语义相似度时,现有聚合方法中所有维度都是独立求和的,其中具有联合依赖性的维度(用相同颜色标记)不能被明确利用和相互增强,导致次优的相似度。其次,在优化信息的后向传播过程中,具有依赖性的维度不能共同优化,而是孤立地学习,这可能会损害表示学习。
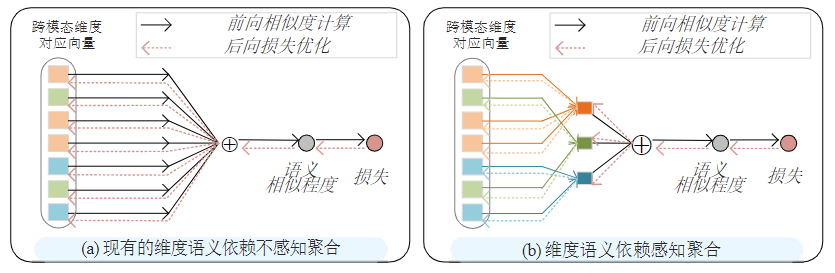
图2 现有的维度语义依赖不感知聚合和所提维度语义依赖感知聚合的对比。
为了解决上述问题,本文提出一种新颖的跨维度语义依赖感知方法,其使所提方法能够明确挖掘和建模维度之间的语义依赖关系,以充分利用这一固有信息。具体而言,本章首先提出将现有的维度独立聚合泛化为一个可学习的框架。在这个框架内,学习到的用于聚合局部维度作为联合表示潜在语义的权重,指示了共享空间中维度之间的依赖程度。此外,本章发现更应该关注具有显著依赖关系的维度,因此提出了一种简单而有效的自适应稀疏依赖概率学习。这种设计引入了每个维度用于联合表示语义的条件概率,并将其作为稀疏正则化器自适应地缩放,自主使模型适应以学习更精确的维度语义依赖。通过这种方式,潜在的维度语义依赖信息可以被明确地揭示和利用,如图2(b)所示。
二、方法与实现 Methods
2.1 问题分析
细粒度图像文本语义关联的范式是首先将显著视觉区域和文本单词映射到共享表示空间,然后检查所有单词区域对的语义相似性以推断图像文本相关性。具体来说,对于映射的任意区域特征$\boldsymbol{v} = \{v_i\}_{i=1}^{d}$和单词特征$\boldsymbol{u} =\{u_i\}_{i=1}^{d}$,在$d$维共享表示空间中,它们可以表示为跨模态语义对应向量$\boldsymbol{s} = \{s_i\}_{i=1}^{d}$,其中$s_i$表示由$v_i$和$u_i$计算出的第$i$个跨模态维度对应关系。现有方法通常聚合$\boldsymbol{s}$ 中的所有维度对应关系以反映它们的语义相似性,可以表示为:
$\begin{matrix}Agg(\boldsymbol{s}) = \sum_{i=1}^{d} \ s_i\end{matrix},$
其中$s_i$可以被确定为常用的$s_i = v_i \cdot u_i $(内积) 或$s_i = \frac{v_i}{\|\boldsymbol{v}\|} \cdot \frac{u_i}{\|\boldsymbol{u}\|}$(余弦距离)等。
并非关注维度对应的计算,本章关注它们在$d$维共享表示空间中的聚合过程。 因此,重新考虑该空间中所有维度对应$ s_i$ 的聚合,上式可以重写为:
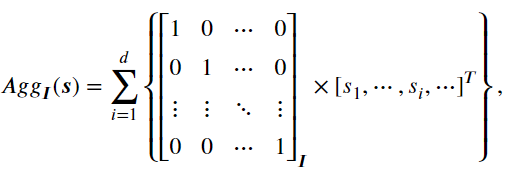
其中${\boldsymbol{I}}$是$d \times d$单位矩阵。 一个重要的属性是${\boldsymbol{I}}$中的每一行表示聚合中维度的相互关系,是相互正交且独立的。
然而,事实上,如图1所示,本章发现维度之间存在依赖关系,可以共同表示潜在语义。正如本文的分析,忽视这种内在的依赖关系信息可能会导致局限性,即具有依赖关系的维度既不能在语义相似性聚合中相互增强,也不能在表示学习过程中进行联合优化。这促使我们探索与共享空间中维度依赖性特性相一致的更合理聚合方法。
2.2 方法概览
为解决上述问题,本章提出跨维度语义依赖感知建模方法(Cross-Dimensional semantic dependency-aware modeling,X-Dim),其显式学习跨维度之间的语义依赖关系以产生新的相似度聚合方式。本章首先提出关于语义依赖建模的关键见解,然后设计一种自适应依赖建模方法。具体而言,所提方法如图3所示,首先,为输入语义对应向量引入可学习矩阵,其中每一行挖掘潜在语义的一种维度依赖性。 然后,基于由相应权重表示的依赖程度,设计了稀疏依赖的概率学习。其自适应地学习稀疏正则化器,自主地使模型捕获更准确的依赖关系。 最后,通过所有细粒度的单词区域相似性来推断图像文本相关性。下面将详细介绍跨维度语义依赖感知关键见解以及自适应学习等模块,并总结所提方法的理论分析和创新优势。
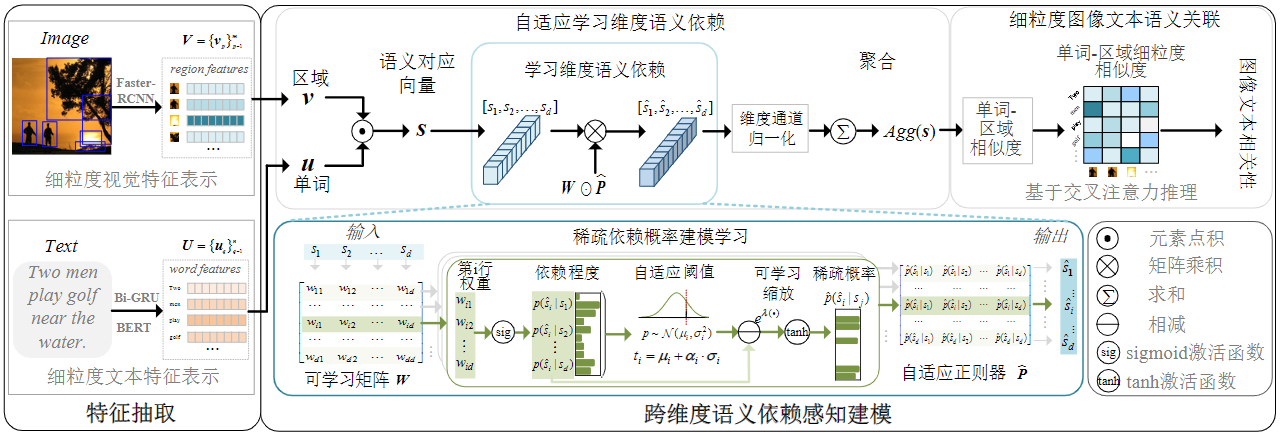
图3 跨维度语义依赖感知建模方法
2.3 跨维度语义依赖感知关键见解
受到部分局部维度具有相互依赖性这一发现的启发,本章的目标是设计一种新颖的聚合,探索共享表示空间中维度之间的语义依赖关系。这样,可以显式地揭示现有聚合过程中被忽略的跨维度依赖信息,从而使得具有联合意义的维度能够得到增强和利用。
(1)可学习的维度语义依赖感知聚合
与现有的方法无意识地使用对角矩阵来独立建模聚合过程中维度之间的相互关系不同,本章的关键见解是将其泛化为可学习的维度依赖性感知聚合框架:
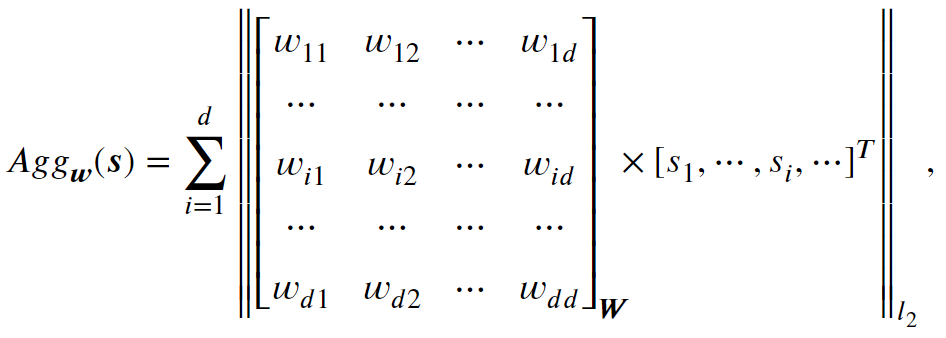
其中${\boldsymbol{W}} \in \mathbb{R}^{d \times d}$是一个学习权重矩阵,其每一行模拟不同维度之间的一种语义依赖关系。 具体来说,对于权重矩阵的第$i$行,有:
$\begin{matrix}\hat{s}_i =\sum_{j=1}^{d} w_{ij} \cdot s_j, \quad j\in[1, d] \end{matrix},$
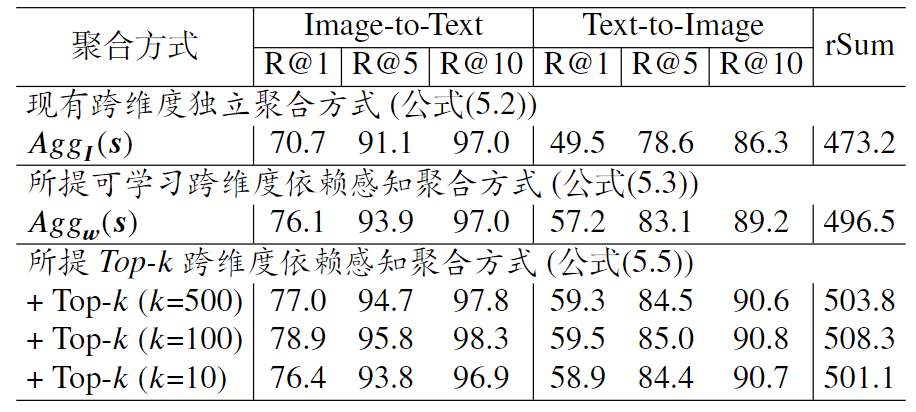
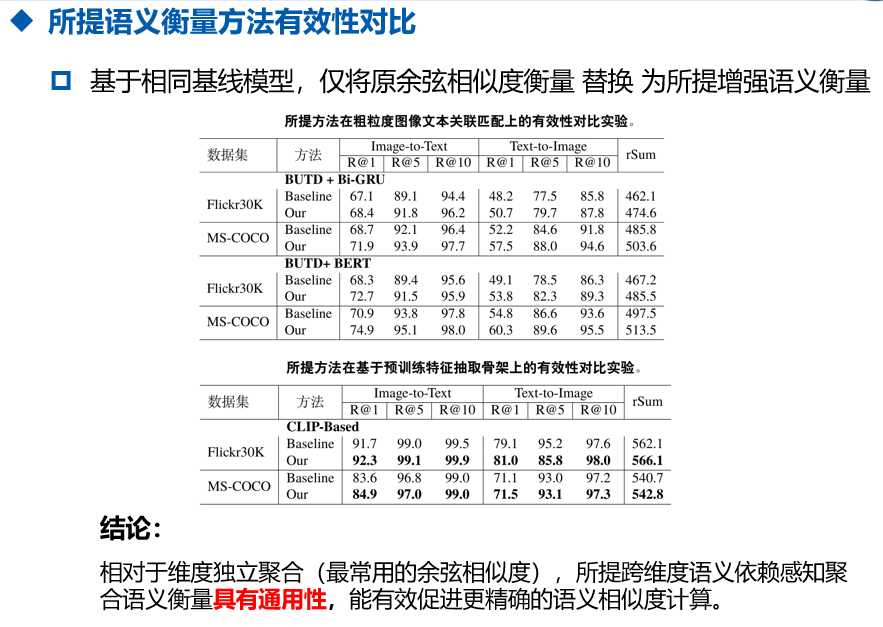
其中$\hat{s}_i$ 作为中间变量,表示第$i$个联合表示的潜在语义,权重$w_{ij}$建模第 $j$个维度的依赖关系$s_j$到共同表示的$\hat{s}_i$。 $\| \cdot\|_{l_2}$表示维度通道的归一化。通过实验发现,如表1所示,我们可以看到,仅通过将原始独立聚合替换为可学习的维度依赖感知聚合,就可以实现显著的性能提升(跨模态关联匹配推理详见后文)。这一发现激发了我们进一步探索更好的维度依赖感知聚合方法。
表1 所提跨维度依赖感知聚合关键见解和现有跨维度独立聚合的性能对比
(2)可学习的Top-k维度语义依赖感知聚合
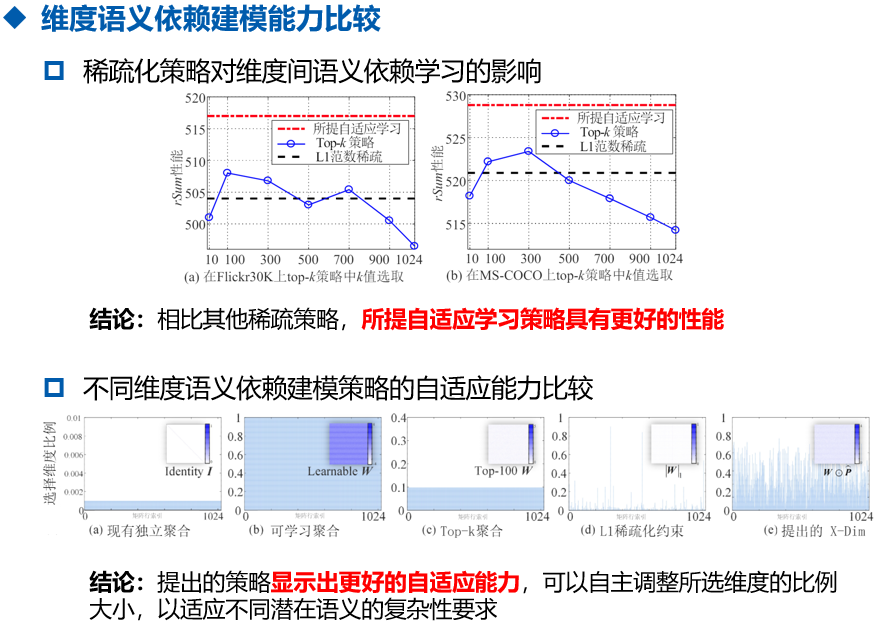
如图4中的统计结果(a)和(b)所示,只有部分维度具有显著的语义依赖性,这是上述公式中进一步实现更准确的交互建模的主要障碍,即维度依赖性聚合了所有维度。 虽然可以学习较大的权重来表明这些维度具有显著的依赖性,从而在聚合过程中贡献更多,但其他具有较小权重的维度也会被聚合,这将引入或多或少的干扰。
为了证明上述思考的有效性,对于可学习权重矩阵中的每一行,本章首先提出可学习维度语义依赖感知聚合的一个变体,其利用 top-k策略来建模维度依赖性:
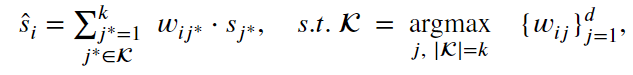
其中$\mathcal{K}$是第$i$行学习权重的 top-k索引子集。
实验发现,即使仅使用简单的 top-k维度依赖感知聚合,在选择合适 k 的前提下,也与最近的先进方法有可比较的性能。
(3)跨维度语义依赖感知自适应学习
对于top-k策略而言,仍然存在一些限制。 首先,手动调整超参数k需要大量重复实验,不仅费时费力,而且可能只针对特定任务和数据,缺乏适应性。 其次,选择相同且固定的 k 维度来建模所有潜在语义依赖关系并不是最佳选择。 由于不同的语义概念具有不同的复杂度,因此需要共同表示的维度也不同。 例如,在图4(a)和图4(b)中,对于“man”和“dog”的语义,具有依赖关系的维度数量明显不同。
考虑到这些因素,同时结合本文从学习维度依赖感知聚合中获得的见解,我们的目标是设计一种更通用的方法,根据数据自主适应学习最佳状态。 为此,本章提出了一种新颖的稀疏依赖自适应概率学习,它引入了每个维度的条件概率来表示联合语义,并自适应地将学习权重缩放为稀疏,以仅选择具有显著依赖性的维度。\textbf{稀疏依赖概率建模学习}。本章首先回顾公式\ref{5-E3}中的维度依赖感知聚合为:
$\hat{s}_i = w_{i1}\cdot s_1 + \ldots + w_{ij}\cdot s_j + \ldots + w_{id}\cdot s_d, \quad j\in[1, d], $
其含义为:共享表示空间中所有维度针对第$i$个联合表示潜在语义的依赖关系进行建模。 为了明确量化,所提方法引入每个维度的条件概率为:
$p(\hat{s}_i|s_j) = Sigmoid(w_{ij}), \quad j\in[1, d],$
其中$p(\hat{s}_i|s_j) \in [0, 1]$反映了第$j$维对联合表示$\hat{s}_i$的依赖程度。$p(\hat{s}_i|s_j)$的值越大,共享空间中的该维度就越倾向于参与联合表示。
我们期望模型能够根据要联合表示的潜在语义自主挖掘具有联合依赖关系的维度,并且挖掘出的维度能够尽可能简洁地聚合,以避免其他不具有显著依赖关系维度的干扰。具体来说,基于学习到的条件概率$\{p(\hat{s}_i|s_j)\}_{j=1}^{d}$表示所有维度对潜在语义的依赖程度$\hat{s}_i$,我们在训练过程中观察到它们的直方图统计概率密度近似正态分布,如图4(c)。因此,根据条件概率的统计特征$(\mu_{i}, \sigma_{i})$,所提方法首先使模型自主学习一个软阈值来区分维度是否具有联合依赖的含义:
$t_{i} = \mu_{i} + \alpha_{i} \cdot \sigma_{i},$
其中$\mu_{i}$和$\sigma_{i}$分别为采样概率值$\{p(\hat{s}_i|s_j)\}_{j=1}^{d}$的平均值和标准差,$\alpha_{i}$ 是一个可学习的调整参数。
在这种设计中,模型可以根据要表示的潜在语义的复杂性自适应地调整软阈值$t_i$,从而能够控制被选择为具有显著语义依赖性的维度的比例。 如图\ref{mm_framework},基于$t_i$,比例可以计算为:
$P_{i} = \int_{t_i}^{+\infty} f_{i}(p) \ d{p},$
其中$f_{i}(p) \sim \mathcal{N} (\mu_i, \sigma_{i}^{2})$是相对于维度依赖程度的拟合正态概率分布。
然后,经过缩放操作,可以得到修正后的稀疏概率:
$\hat{p}(\hat{s}_i|s_j) = \delta(e^{\kappa(p(\hat{s}_i|s_j)-t_i)}),$
其中$\kappa$是可学习的缩放参数,$\delta(\cdot)$表示$tanh$激活函数。
也就是说,在条件概率$p(\hat{s}_i|s_j)$的指导下,那些依赖度大于$t_i$的维度被保留,而其他小于$t_i$的维度被压缩到接近于零而被舍弃。 因此,可以将可学习维度语义依赖感知公式\ref{5-E3}重写为:
$\begin{matrix}\hat{s}_i =\sum_{i=1}^{d} \ \ \hat{p}(\hat{s}_i|s_j) \cdot w_{ij} \cdot s_j, \quad j\in[1, d] \text{。} \end{matrix}$
最后,自适应维度语义依赖感知聚合可以表述为:
$Agg(\boldsymbol{s}) =\sum_{i=1}^{d} \left \| (\hat{\boldsymbol{P}}\odot {\boldsymbol{W}}) \times {\boldsymbol{s}}^{T} \right\|_{l_2},$
其中$\hat{\boldsymbol{P}} = \{\hat{p}(\hat{s}_i|s_j)\}$, $i,j\!\!\in\!\![1, d]$可以被视为自适应正则化器,以实现更准确的维度依赖建模。
(4)细粒度图文相关性计算
本章通过将提出的跨维度语义依赖感知建模方法X-Dim 整合到现有交叉注意来构建跨模态细粒度图像文本语义关联。 具体来说,对于给定的图像文本对$(\boldsymbol{U}, \boldsymbol{V})$,由$n$个文本单词 $\{\boldsymbol{u_i}\}_{i=1}^{n}$和$m$显著图像区域$\{ \boldsymbol{v_j} \}_{j=1}^{m}$。所提方法首先获得所有单词区域对$(\boldsymbol{u_i}, \boldsymbol{v_j})$, $i \in [1, n]$, $j\in [1, m]$的语义相似度为:
$r_{ij}=Agg(\boldsymbol{s}_{ij}), \quad \text{s.t.} \ \ \boldsymbol{s}_{ij}= \boldsymbol{u_i} \odot \boldsymbol{v_j}.$
对于每个单词查询$\boldsymbol{u_i}$,我们找到其相关区域为:
$\boldsymbol{\tilde{v}_j }=\sum_{j=1}^{m}\beta_{ij}v_{j}, \quad \text{s.t.} \ \ \beta_{ij} = \frac{exp(\lambda \cdot \delta({r}_{ij}))}{\sum_{j=1}^{m}exp(\lambda \cdot \delta({r}_{ij}))},$
其中$\beta_{ij}$表示注意力权重,$\lambda$是可学习的缩放参数。类似地,第$i$个单词和图像之间的相关性得分可以计算为:
$\tilde{r}_{i} = Agg(\boldsymbol{\tilde{s}}_{i}),$
其中 $\boldsymbol{\tilde{s}}_{i} = \boldsymbol{ u_i } \odot \boldsymbol{\tilde{v}_i }$。
最后,整体图像文本相关性推理为:
$\begin{matrix}S(\boldsymbol{U}, \boldsymbol{V}) = \frac{1}{n}\sum_{i=1}^{n} \tilde{r}_{q} \text{。} \end{matrix}$
(5)理论分析
本章所提方法的伪代码如算法如下所示,其中‘仅训练’表示只在训练过程中执行,推理阶段可以忽略。

从理论上分析,本章节所提出的X-Dim在跨维度语义依赖学习中隐式引入了核函数,增强了跨模态特征的区分性。 实验也验证了这一观点的有效性。
先验知识:对于自适应维度语义依赖感知聚合,即,$\boldsymbol{s} \in \mathbb{R}^{1 \times d}$是输入的跨模态对应向量,令$\hat{\boldsymbol{w}}_i \in \mathbb{R}^{1 \times d}$表示矩阵$\hat{\boldsymbol{P}}\odot {\boldsymbol{W}}$的第$i$行,$\hat{s}_i = \hat{\boldsymbol{w}}_i \boldsymbol{s}^{T}$作为其联合表示的中间变量。
我们首先通过所有中间变量$\{\hat{s}_i \}_{i=1}^{d}$将公式中的自适应维度语义依赖感知聚合重写为:
$Agg(\boldsymbol{s})=\sum_{i=1}^{d}\frac{\hat{s}_i }{\sqrt{\sum_{i=1}^{d}(\hat{s}_i)^{2} + \epsilon}}=\frac{\sum_{i=1}^{d}\hat{\boldsymbol{w}}_i \boldsymbol{s}^{T} }{\sqrt{ \boldsymbol{s}(\sum_{i=1}^{d}\hat{\boldsymbol{w}}_i^T\hat{\boldsymbol{w}}_i)\boldsymbol{s}^{T} + \epsilon}},$
其中$\sum_{i=1}^{d}\hat{\boldsymbol{w}}_i^T\hat{\boldsymbol{w}}_i \succeq 0$是半正定矩阵,可以表示为$U\Lambda U^{T}$通过特征值分解。 $\epsilon$ 是一个接近于零的常数,以避免在实现中的数值问题。 因此,通过替换操作,我们有:
$Agg(\boldsymbol{s}) =\frac{\sum_{i=1}^{d}\hat{\boldsymbol{w}}_i \boldsymbol{s}^{T} }{ \sqrt{ {\phi (\boldsymbol{s}) \phi (\boldsymbol{s})^{T}}+ \epsilon}},$
其中$\phi (\boldsymbol{s}) = {\boldsymbol{s}U \sqrt{\Lambda} }$,分母项$\sqrt{ {\phi (\boldsymbol{s}) \phi (\boldsymbol{s})^{T}}+ \epsilon}$是所提跨维语义依赖建模的隐式引入的变体,其形式类似于核函数。根据核函数理论,可以表示为$\phi (\boldsymbol{s}) \phi (\boldsymbol{s})^{T}$上在$\epsilon$处的无限阶多项式处的泰勒展开式,相当于将原始共享空间中从有限$d$维$\boldsymbol{s}$变换到无限维空间。 因此,通过本章提出的 X-Dim,跨模态维度对应向量$\boldsymbol{s}$具有更容易区分的优点。
并且,值得注意的是,学习到的$\hat{\boldsymbol{P}}\odot {\boldsymbol{W}}$在推理阶段不需要额外的重新计算,可以直接使用。因为随着训练的结束,共享表示空间中的跨维度语义依赖关系被确定。所提方法中计算复杂度最大的操作为自适应维度语义依赖感知聚合中$d \times d$矩阵与$d \times 1$矩阵的乘法操作,因此所提X-Dim的计算复杂度为$\mathcal{O}(d^2)$。
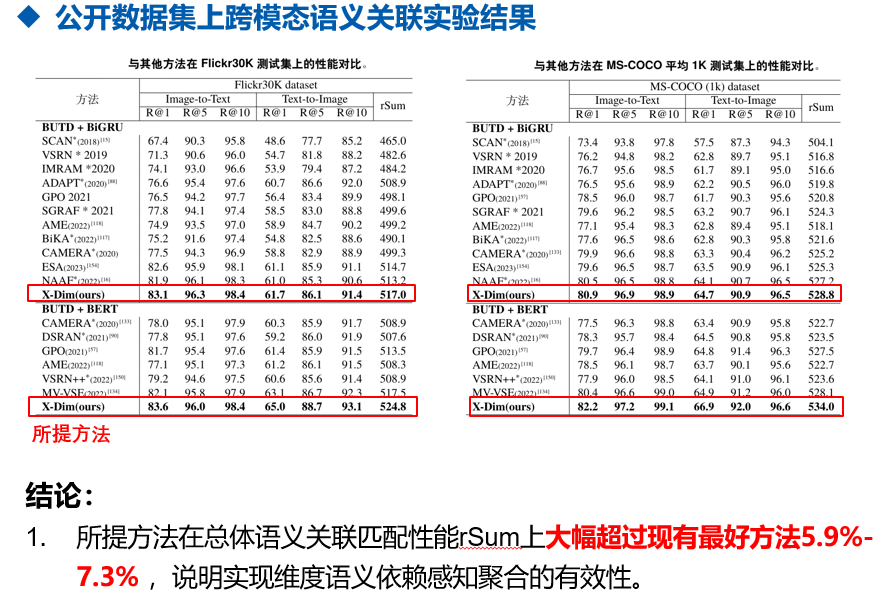
三、实验结果 Experiments

四、论文
If you found this useful, please cite the following paper:
Zhang K, Zhang L, Hu B, et al. Unlocking the Power of Cross-Dimensional Semantic Dependency for Image-Text Matching[C]//Proceedings of the 31st ACM International Conference on Multimedia. 2023: 4828-4837.
- @inproceedings{zhang2023unlocking,
- title={Unlocking the Power of Cross-Dimensional Semantic Dependency for Image-Text Matching},
- author={Zhang, Kun and Zhang, Lei and Hu, Bo and Zhu, Mengxiao and Mao, Zhendong},
- booktitle={Proceedings of the 31st ACM International Conference on Multimedia},
- pages={4828--4837},
- year={2023}
- }
视觉语言跨模态特征语义相似度计算改进--表征空间维度语义依赖感知聚合算法 ACM MM的更多相关文章
- NLP 语义相似度计算 整理总结
更新中 最近更新时间: 2019-12-02 16:11:11 写在前面: 本人是喜欢这个方向的学生一枚,写文的目的意在记录自己所学,梳理自己的思路,同时share给在这个方向上一起努力的同学.写得不 ...
- 孪生网络(Siamese Network)在句子语义相似度计算中的应用
1,概述 在NLP中孪生网络基本是用来计算句子间的语义相似度的.其结构如下 在计算句子语义相似度的时候,都是以句子对的形式输入到网络中,孪生网络就是定义两个网络结构分别来表征句子对中的句子,然后通过曼 ...
- 深度学习解决NLP问题:语义相似度计算
在NLP领域,语义相似度的计算一直是个难题:搜索场景下query和Doc的语义相似度.feeds场景下Doc和Doc的语义相似度.机器翻译场景下A句子和B句子的语义相似度等等.本文通过介绍DSSM.C ...
- BERT实现QA中的问句语义相似度计算
1. BERT 语义相似度 BERT的全称是Bidirectional Encoder Representation from Transformers,是Google2018年提出的预训练模型,即双 ...
- DSSM 深度学习解决 NLP 问题:语义相似度计算
https://cloud.tencent.com/developer/article/1005600
- 对比学习下的跨模态语义对齐是最优的吗?---自适应稀疏化注意力对齐机制 IEEE Trans. MultiMedia
论文介绍:Unified Adaptive Relevance Distinguishable Attention Network for Image-Text Matching (统一的自适应相关性 ...
- java文章标题及文章相似度计算hash算法实现
参看了 https://github.com/awnuxkjy/recommend-system 对方用了 余弦 函数实现相似度计算,我则用的是 hanlp+hash 算法(Hash算法总结) 再看服 ...
- 跨模态语义关联对齐检索-图像文本匹配(Image-Text Matching)
论文介绍:Negative-Aware Attention Framework for Image-Text Matching (基于负感知注意力的图文匹配,CVPR2022) 代码主页:https: ...
- 图像文本跨模态细粒度语义对齐-置信度校正机制 AAAI2022
论文介绍:Show Your Faith: Cross-Modal Confidence-Aware Network for Image-Text Matching (跨模态置信度感知的图像文本匹配网 ...
- 使用同一个目的port的p2p协议传输的tcp流特征相似度计算
结论: (1)使用同一个目的port的p2p协议传输的tcp流特征相似度高达99%.如果他们是cc通信,那么应该都算在一起,反之就都不是cc通信流. (2)使用不同目的端口的p2p协议传输的tcp流相 ...
随机推荐
- 2018-12-27-WPF-从-DrawingVisual-转-BitmapImage-图片
title author date CreateTime categories WPF 从 DrawingVisual 转 BitmapImage 图片 lindexi 2018-12-27 11:3 ...
- Java面试题:SimpleDateFormat是线程安全的吗?使用时应该注意什么?
在日常开发中,我们经常会用到时间,我们有很多办法在Java代码中获取时间.但是不同的方法获取到的时间的格式都不尽相同,这时候就需要一种格式化工具,把时间显示成我们需要的格式. 最常用的方法就是使用Si ...
- 从原始边列表到邻接矩阵Python实现图数据处理的完整指南
本文分享自华为云社区<从原始边列表到邻接矩阵Python实现图数据处理的完整指南>,作者: 柠檬味拥抱. 在图论和网络分析中,图是一种非常重要的数据结构,它由节点(或顶点)和连接这些节点的 ...
- Node.js 万字教程
0. 基础概念 Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境,使用了一个事件驱动.非阻塞式 I/O 模型,让 JavaScript 运行在服务端的开发平台. ...
- pandas:时间序列数据的周期转换
时间序列数据是数据分析中经常遇到的类型,为了更多的挖掘出数据内部的信息,我们常常依据原始数据中的时间周期,将其转换成不同跨度的周期,然后再看数据是否会在新的周期上产生新的特性. 下面以模拟的K线数据为 ...
- Solution Set - 组合计数
CF40E Number Table Link&Submission. 显然 \(n,m\) 奇偶性不同时无解.奇偶性相同时,假设有一行全为空,剩下每行至少一个有空,则除这些位置外没有限制的位 ...
- 【python爬虫案例】爬取微博任意搜索关键词的结果,以“唐山打人”为例
目录 一.爬取目标 二.展示爬取结果 三.讲解代码 四.同步视频 4.1 演示视频 4.2 讲解视频 五.附:完整源码 一.爬取目标 大家好,我是马哥. 今天分享一期python爬虫案例,爬取目标是新 ...
- Js实现抽奖转盘,和点击返回某个模块顶部的功能
最近写了几个转盘抽奖的活动页面: 1.设定旋转的角度: HTML部分:转盘代码: <div class="lottery"> <div class="l ...
- uniapp中正确使用echart
uniapp中不能直接使用百度echart,要么就只能嵌入html,然后在html中进入echart进行使用,这样非常不方便, 下面介绍这个插件,对百度echart进行局部小改造,使他能在uniapp ...
- SimpleHTTPServer模块详解
SimpleHTTPServer实现文件的展示和下载 可以用python2.7直接启动一个进程.以命令执行的当前目录为页面根目录,如果不存在index.html,默认展示当前目录的所有文件. pyth ...