Huggingface初上手即ERNIE-gram句子相似性实战
大模型如火如荼的今天,不学点语言模型(LM)相关的技术实在是说不过去了。只不过由于过往项目用到LM较少,所以学习也主要停留在直面——动眼不动手的水平。Huggingface(HF)也是现在搞LM离不开的工具了。
出于项目需要,以及实践出真知的想法,在此记录一下第一次使用HF和微调ERNIE-gram的过程。
开始的开始
HF已经做的很好了。但是对于第一次上手实操LM的我来说,还是有点陌生的。上手时有几个问题是一直困扰我的:
- HF上这么多模型,我该用哪一个?
- 每个LM的主要作用是对文本进行Embedding,可我的任务是句子对相似性计算,这该怎么搞?
- 我想在自己的数据上继续微调模型,该怎么做?
模型选择
简单描述一下我的任务:给定两个句子,判断两个句子的语义是否等价。
从NLP的角度出发,这是一类STS(Semantic Textual Similarity)任务,本质是在比较两个文本的语义是否相似。通过检索,找到了一些相关的比赛,例如问题匹配的比赛和相关的模型,这里简单罗列一下:
- 千言数据集:问题匹配鲁棒性。
- 千言-问题匹配鲁棒性评测基线。
- Quora Question Pairs。
- ATEC学习赛:NLP之问题相似度计算。
- 第三届魔镜杯大赛—— 语义相似度算法设计。
- LCQMC通用领域问题匹配数据集。
- [Chinese-BERT-wwm]。
通过以上资料,我大致确定了我要使用的模型——ERNIE-Gram[1]。
如何使用选好的模型
首先,我找到了ERNIE-Gram的代码仓库[2]。代码里开源了模型的结构以及微调的代码,相对来说还是比较齐全的。但是有一个最不方便的地方——它是用飞浆写的(不是说飞浆不好,只是一直以来都用pytorch)。当然,很快我又找到了pytorch版的ERNIE-Gram,并且在HF找到了ERNIE-Gram模型。如果我知道怎么使用HF,那么或许我可以很快开始我的微调了,可惜没有如果。
那怎么使用HF上的模型,在自己的数据上进行微调呢?
找到了一篇比较合适的参考资料[3],其中介绍了如何在HF中调用ERNIE模型:
from transformers import BertTokenizer, ErnieModel
tokenizer = BertTokenizer.from_pretrained("nghuyong/ernie-1.0-base-zh")
model = ErnieModel.from_pretrained("nghuyong/ernie-1.0-base-zh")
根据这个,我发现通过HF使用某个模型的方法是从transformers库中导入对应的模型和工具即可。那么,我只需要找到对应的模型名和工具,然后以此作为基座,再添加一些可训练层就可以了?
分析dir(transformers)看看都有哪些和Ernie相关的类:
d = dir(transformers)
dd = [e for e in d if 'ernie' in e.lower()]
len(dd) # 26
print(dd)
# ====
['ERNIE_M_PRETRAINED_CONFIG_ARCHIVE_MAP', 'ERNIE_M_PRETRAINED_MODEL_ARCHIVE_LIST', 'ERNIE_PRETRAINED_CONFIG_ARCHIVE_MAP', 'ERNIE_PRETRAINED_MODEL_ARCHIVE_LIST', 'ErnieConfig', 'ErnieForCausalLM', 'ErnieForMaskedLM', 'ErnieForMultipleChoice', 'ErnieForNextSentencePrediction', 'ErnieForPreTraining', 'ErnieForQuestionAnswering', 'ErnieForSequenceClassification', 'ErnieForTokenClassification', 'ErnieMConfig', 'ErnieMForInformationExtraction', 'ErnieMForMultipleChoice', 'ErnieMForQuestionAnswering', 'ErnieMForSequenceClassification', 'ErnieMForTokenClassification', 'ErnieMModel', 'ErnieMPreTrainedModel', 'ErnieMTokenizer', 'ErnieModel', 'ErniePreTrainedModel', 'models.ernie', 'models.ernie_m']
为了更好了解每个类是干啥的,直接上transformers库来看各个类的介绍[4]。很快啊,我就发现ErnieForSequenceClassification很适合我的任务:
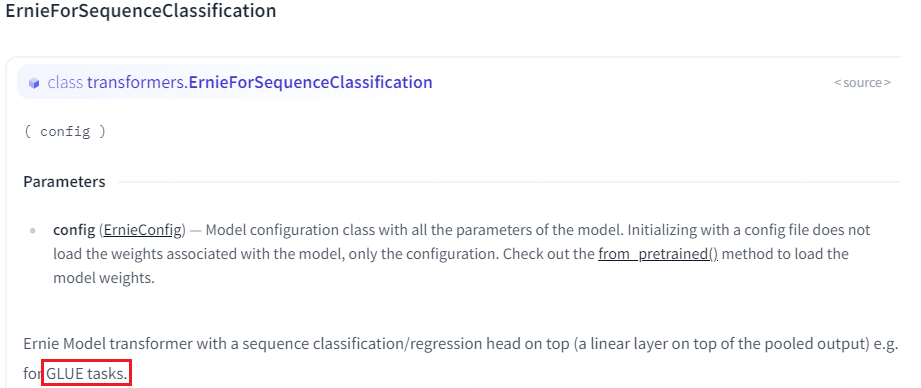
图中的GLUE(General Language Understanding Evaluation )[5]是一系列评测任务集合,显然,我的任务属于Similarity那一类。

很好,大致可以确定该怎么使用HF上的Ernie-Gram模型来完成我的任务了(可惜没有对应的示例)。
怎么微调
在实操之前,对于在预训练好的模型上进行微调,我的想法是:把预训练模型包起来,添加一个分类层,学习分类层的参数就可以了。
但是如果我选择了ErnieForSequenceClassification,通过源码可以发现该类其实是在ErnieModel的基础上添加了一个分类层,那我是否直接加载模型后,选择训练哪些参数就可以了呢?
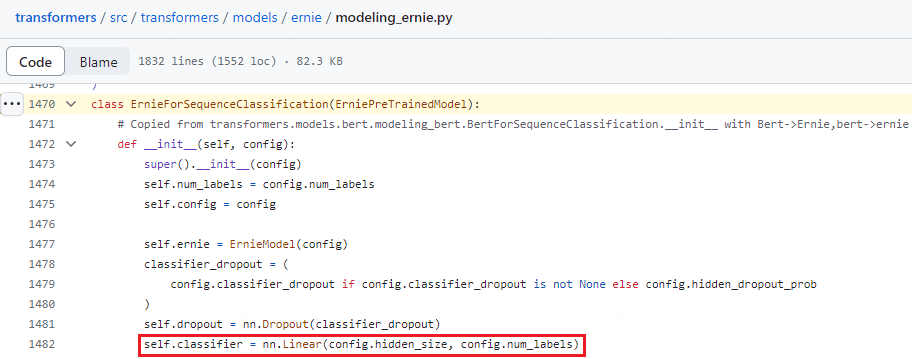
其实,广义的来说,这等价于一个问题:在HuggingFace中如何微调模型?[6][7][8]。
其实,微调和平常的模型训练没有太大区别,只不过需要加载预训练好的模型,以及利用现成的工具搭建训练流程,其中主要涉及到的就两点:模型的定义、训练流程的搭建。
模型定义
由于transformers中已经定义好了很多模型,如果某个完全符合要求,那就可以直接使用了。根据自己的需求,选择冻结和训练哪些参数就可以了。
但是有些时候只是用预训练的模型作为自己模型的一部分,这个时候就需要我们做一些额外的工作了——把预训练模型作为一块积木,搭建我们自己的模型。正如ErnieForSequenceClassification所做的一样。
训练流程
训练流程类似。可以重头自己搭建训练流程,或者使用transformes自带的Trainer接口。
这里直接参考HF的教程即可:Fine-tuning a model with the Trainer API、自己搭建训练流程。
参考
Huggingface初上手即ERNIE-gram句子相似性实战的更多相关文章
- 利用Hugging Face中的模型进行句子相似性实践
Hugging Face是什么?它作为一个GitHub史上增长最快的AI项目,创始人将它的成功归功于弥补了科学与生产之间的鸿沟.什么意思呢?因为现在很多AI研究者写了大量的论文和开源了大量的代码, ...
- 学习Keras:《Keras快速上手基于Python的深度学习实战》PDF代码+mobi
有一定Python和TensorFlow基础的人看应该很容易,各领域的应用,但比较广泛,不深刻,讲硬件的部分可以作为入门人的参考. <Keras快速上手基于Python的深度学习实战>系统 ...
- 力扣每日一题2023.1.16---1813. 句子相似性 III
一个句子是由一些单词与它们之间的单个空格组成,且句子的开头和结尾没有多余空格.比方说,"Hello World" ,"HELLO" ,"hello w ...
- Android 5.0 Lollipop初上手体验
在等了好几天还没有等到OTA升级提示,前天笔者给Nexus4线刷入了官方提供的Lollipop的镜像,在试用了这两天之后,现在总结下自己感觉很惊艳的地方和一些地方的吐槽.(点击图片可以查看大图) 1. ...
- xss挖掘初上手
本文主要总结了xss可能出现的场景.偏向于案例,最后分享一哈简单的绕过和比较好用的标签. 1.搜索框 首先看能否闭合前面的标签. 如输入111”><svg/onload=alert(1)& ...
- TensorFlow.org教程笔记(一)Tensorflow初上手
本文同时也发布在自建博客地址. 本文翻译自www.tensorflow.org的英文教程. 本文档介绍了TensorFlow编程环境,并向您展示了如何使用Tensorflow解决鸢尾花分类问题. 先决 ...
- centos7初上手3-安装apache服务
前两篇学习安装了mysql服务器,tomcat服务,这篇文章学习安装apache服务 1.执行yum install httpd,安装完成后查看httpd rpm -qa|grep httpd 2.新 ...
- centos7初上手2-安装tomcat服务
上一篇文章说完安装mysql数据库,这篇文章来学习一下tomcat安装 1.先做准备工作,安装jdk,先看服务器上有没有安装相关java文件 下载好1.8版本的安装包,用xftp传到服务器上(根据个人 ...
- centos7初上手1-安装mysql数据库
随着云服务器的普及,购入云服务器的门槛越来越低,对一个程序员来说,很多人会购买一款云服务器.以前买过两年windows服务器(没有什么实际用途,就是为了玩),最近有机会接触一下linux服务器,选择了 ...
- Linux初上手!
虚拟机Virtual Box装的Kali Linux,是Debian的发行版本,安装过程不说了,不是硬盘安装也没什么说的,由于是新手所以只有两个分区,一个[/]和一个[swap] 装好之后是xwind ...
随机推荐
- 使用influxdb以及Grafana监控vCenter的操作步骤
1. 下载安装介质 计划telegraf和influxdb 使用rpm包进行安装.Grafana使用docker容器方式安装 下载路径为: https://repos.influxdata.com/r ...
- 从源代码构建TensorFlow流程记录
京东科技隐私计算产品部 曹雨晨 为什么从源代码构建 通常情况下,直接安装构建好的.whl即可.不过,当需要一些特殊配置(或者闲来无事想体会 TensorFlow 构建过程到底有多麻烦)的时候,则需要选 ...
- vue如何获取动态添加的类
动态添加的类.你在声明周期中的mounted中是拿不到的. 是有在updata这个声明周期中才可以拿到的. 因为此时数据才跟新完成
- minIO系列文章02---linux安装
目录 1.Minio介绍 2.安装MinIO 3. MinIO客户端 1.Minio介绍MinIO 是一个基于Apache License v2.0开源协议的对象存储服务.适合于存储大容量非结构化的数 ...
- # 再次推荐github 6.7k star开源IM项目OpenIM性能测试及消息可靠性测试报告
本报告主要分为两部分,性能测试和消息可靠性测试.前者主要关注吞吐,延时,同时在线用户等,即通常所说的性能指标.后者主要模拟真实环境(比如离线,在线,弱网)消息通道的可靠性. 先说结论,对于容量和性能: ...
- yum 安装失败解决思路$releasever(curl#6 - "Could not resolve host: mirrorlist.centos.org; Unknown error")
问题 公司使用刀片机的系统版本是CentOS 7.9.2009(Core),本人在重新安装虚拟机时,也使用对应的系统版本,在安装软件时,yum无法正常使用,一开始觉得,centos的release版本 ...
- 内存池是什么原理?|内存池简易模拟实现|为学习高并发内存池tcmalloc做准备
前言 那么这里博主先安利一些干货满满的专栏了! 这两个都是博主在学习Linux操作系统过程中的记录,希望对大家的学习有帮助! 操作系统Operating Syshttps://blog.csdn.ne ...
- 模式识别实验:基于主成分分析(PCA)的人脸识别
前言 本文使用Python实现了PCA算法,并使用ORL人脸数据集进行了测试并输出特征脸,简单实现了人脸识别的功能. 1. 准备 ORL人脸数据集共包含40个不同人的400张图像,是在1992年4月至 ...
- CF455D Serega and Fun 题解
题目链接:CF 或者洛谷 本题是可以用平衡树去做的,具体的为每个 \(k\) 开一棵平衡树去维护相对位置,而这种移动操作用平衡树维护又是很容易做到的,这种做法是双 \(log\).在 \(1e5\) ...
- Linux用户被锁定后如何解锁
客户的一台机器,按照提供的常用密码尝试使用oracle用户登陆,超过指定次数账号被锁定,提示如下: Account locked due to 6 failed logins 这需要使用root用户解 ...