Fluid 助力阿里云 Serverless 容器极致提速
简介: 本文展示了一个在 ASK 环境中运行 Fluid 的完整数据访问示例,希望能够帮助大家了解 Fluid 的使用体验、运行效果以及 Serverless 和数据密集型应用结合的更多可行性。
作者:东伝
背景
数据对于当今互联网业务的重要性不言而喻,它几乎渗透到了当今这个世界的每一个角落。但单有数据是不够的,真正让数据产生价值的,是针对各业务场景运行的对大量数据的密集分析与计算,如机器学习、大数据分析、OLAP 聚合分析等等。近些年,随着数据规模的增大,这些对于资源有着更高要求的数据密集应用自然地导向了以弹性资源著称的云服务。
在这种数据密集应用上云的趋势下,Serverless 似乎并不是这个趋势的明显受益者。尽管几乎所有人都对这种计算资源无限扩容、弹性敏捷交付、低运维成本的架构不吝赞美之词,但由于它将计算存储分离的架构推向了一个更纯粹的极端,具有强数据依赖的数据密集应用想要高效运行于 Serverless 环境变得极其困难。
举例来说,如果我们想将 AI 推理服务应用部署在 Serverless 架构下,每个服务应用启动前必须将存放在外部存储系统的 AI 模型首先拉取到本地内存中。考虑到近年来 AI 大模型已经成为业界主流,让我们假设这个 AI 模型的大小为 30GB,并且存储于 OSS 对象存储服务中,如果需要同时启动 100 个这样的 AI 推理服务应用,那么总共的数据读取量就是 3000GB。OSS 存储默认的数据访问限速是 10Gbps,这就意味着 100 个应用都需要等待 2400 秒(3000GB * 8 / 10Gbps)才可以真正开始对外提供服务。如果每个服务我们创建一个 ecs.gn7i-c32g1.16xlarge 的实例(按每小时单价折算每秒 0.008 元),这意味着光在等待数据上就已经花掉了 1920 元(0.008 元/秒 * 2400 秒 * 100)。总结来说,我们大量的费用没有花在产生价值的计算上,这显然不是我们想要的。(*实际价格以阿里云官网显示为准)
那么,有没有什么方法可以优化上述过程?这就引入了本文的主角:Fluid。Fluid 是一个 Kubernetes 原生的分布式数据集编排和加速引擎。Fluid 诞生的初衷即是为应用的数据访问延时问题提供云原生的解决方案。对于困扰着 Serverless 数据密集应用的上述相关问题,Fluid 在保证用户简单易用的使用体验前提下,给出了一套 Serverless 环境新的数据访问架构方案,帮助用户提升数据访问效率。
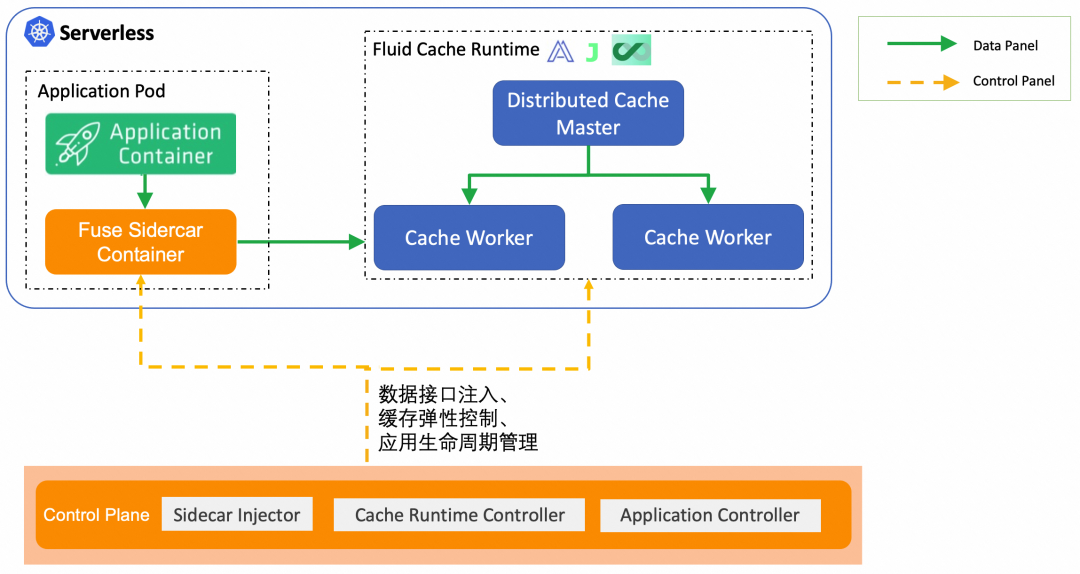
本文将 step by step 地介绍 Fluid 的运行示例,帮助大家了解如何在阿里云 ASK(Alibaba Serverless Kubernetes)环境中使用 Fluid,展示如何借助 Fluid 实现 zero to zero 的(从零资源使用开始到全部资源释放结束)规模化数据密集型任务执行模式,并取得降本提速的效果。
Fluid on ASK 运行示例
Fluid 数据编排加速 Serverless Kubernetes 功能尚处于公测阶段,可点击阅读原文申请体验席位。
Fluid 部署
在运行以下示例前,首先需要搭建一个 ASK 集群,并配置好连接该集群的 Kubeconfig。相关步骤可参考文末文档《如何创建 ASK 集群》。在使用 Fluid 的各项功能前,需要将 Fluid 的各控制面组件部署到 ASK 集群中。这个部署过程可以通过阿里云容器服务-Kubernetes 控制台轻松完成。
如下图所示:
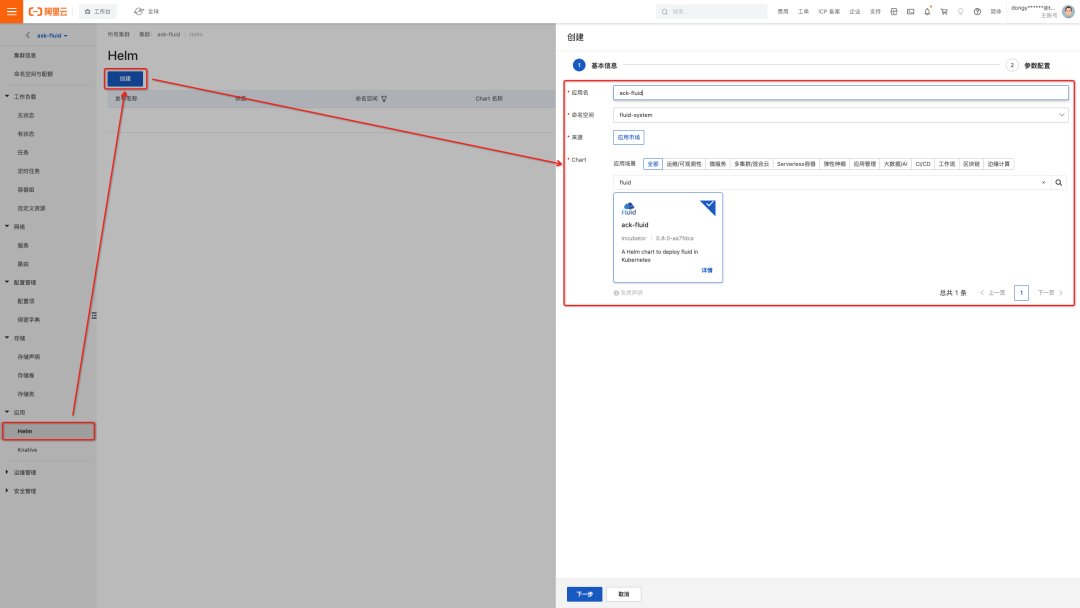
- 选择 ASK 集群面板右侧的“应用-Helm”子面板
- 点击"创建"按钮
- 在 Chart 市场中搜索 ack-fluid 即可找到 Fluid 对应的 Helm Chart,填写“应用名”(例:ack-fluid)。
- 点击“下一步”后,选择使用默认的 fluid-system 作为部署的命名空间
- 接着无需对 Chart Values 进行任何修改,直接点击“确定”,即可将 Fluid 部署到 ASK 集群中。
在配置完 ASK 集群对应的 Kubeconfig 信息后,输入以下命令:
$ kubectl get pod -n fluid-system
可以观察到 Fluid 的几个组件已经正常运行起来:
NAME READY STATUS RESTARTS AGE
dataset-controller-d99998f79-dgkmh 1/1 Running 0 2m48s
fluid-webhook-55c6d9d497-dmrzb 1/1 Running 0 2m49s
其中:
- Dataset Controller:负责维护各个 Fluid 所引入的 Dataset CRs 的完整生命周期。
- Fluid Webhook: 负责对用户需要访问数据的应用 Pod 进行自动化变换(Mutation),无感知地帮助用户实现 Serverless 场景的数据访问功能。
除了上述描述的两个组件外,Fluid 的控制面仍然包含了一些与各类缓存系统(例如:JindoFS、JuiceFS、Alluxio 等)紧密关联的控制器组件,这些组件在初始部署状态下不会创建,仅当用户指定需要使用某种缓存系统时,与其相关联的缓存系统控制器组件 Pod 才会按需扩容,从而在按量付费的 ASK 环境中尽可能地帮助用户节省成本。
数据缓存部署
Fluid 世界中的一切都以 Dataset 这一自定义资源为中心:无论是对外部存储中已有数据的抽象管理还是应用 Pod 的数据访问,用户都需要和 Dataset 资源进行交互。每当用户创建一个 Dataset CR 并指定了它的缓存系统后端,Fluid 就会自动地将数据缓存部署到 Kubernetes 集群中。
在下面的实践过程中,我们以阿里云 OSS 对象存储作为外部存储系统为例,模拟一个完整的 “缓存部署-数据访问-资源回收”的标准数据使用过程。
- 数据文件准备
首先,准备一个待访问的文件。例如,这里我们使用 dd 命令快速创建一个大小约为 30G 的文件:
$ cd $(mktemp -d) $ dd if=/dev/zero of=./largefile-30G bs=10M count=3072 3072+0 records in
3072+0 records out
32212254720 bytes (32 GB) copied, 108.189 s, 298 MB/s $ ls -lh ./largefile-30G
-rw-r--r-- 1 root root 30G Sep 7 21:11 ./largefile-30G
接着,把上述创建的待访问文件上传到 OSS Bucket 中,这里以一个位于 Beijing Region 的名为 fluid-demo 的 OSS Bucket 为例。
$ ossutil cp -i <access_key_id> -k <access_key_secret> -e oss-cn-beijing-internal.aliyuncs.com ./largefile-30G oss://fluid-demo/
- 创建 Fluid Dataset 和 Runtime 资源
数据准备和上传后,即可在 Fluid 中声明上述待访问的数据。具体而言,我们需要提交一个 Dataset CR 和一个 Runtime CR。Dataset CR 中描述数据在外部存储系统中的 URL 位置,Runtime CR 描述缓存系统及系统具体配置。
首先,把访问 OSS Bucket 所需的身份凭证信息存储于 Secret 中:
$ kubectl create secret generic oss-access-key \
--from-literal=fs.oss.accessKeyId=<access_key_id> \
--from-literal=fs.oss.accessKeySecret=<access_key_secret>
接着,定义 Dataset CR 和 Runtime CR。这里我们选择 JindoFS 作为缓存系统后端,Fluid Runtime 资源为 JindoRuntime:
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
metadata:
name: demo-dataset
spec:
mounts:
- mountPoint: oss://fluid-demo # OSS Bucket URL
name: demo
path: /
options:
fs.oss.endpoint: oss-cn-beijing-internal.aliyuncs.com # OSS Bucket内网访问端点
encryptOptions:
- name: fs.oss.accessKeyId
valueFrom:
secretKeyRef:
name: oss-access-key
key: fs.oss.accessKeyId
- name: fs.oss.accessKeySecret
valueFrom:
secretKeyRef:
name: oss-access-key
key: fs.oss.accessKeySecret
---
apiVersion: data.fluid.io/v1alpha1
kind: JindoRuntime
metadata:
name: demo-dataset
spec:
# 缓存Worker节点数量
replicas: 5
podMetadata:
annotations:
# 选择JindoFS Pod使用的实例规格
k8s.aliyun.com/eci-use-specs: ecs.d1ne.6xlarge
# 启用实例镜像缓存,加速Pod启动过程
k8s.aliyun.com/eci-image-cache: "true"
tieredstore:
levels:
# 以40GiB的内存作为每个缓存Worker节点的缓存介质
- mediumtype: MEM
volumeType: emptyDir
path: /dev/shm
quota: 40Gi
high: "0.99"
low: "0.99"
创建上述 Dataset CR 和 JindoRuntime CR 到 ASK 集群:
$ kubectl create -f dataset.yaml
- 查看 Dataset 部署状态
Dataset CR 和 JindoRuntime CR 创建后,约 1 到 2 分钟后,Dataset 将部署完成,届时可以查看到与缓存系统以及后端存储系统中数据的相关信息。
$ kubectl get dataset demo-dataset
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
demo-dataset 30.00GiB 0.00B 200.00GiB 0.0% Bound 2m9s
例如,上方示例展示了 Fluid Dataset 的相关信息
- OSS 中数据集总大小(UFS TOTAL SIZE) :30.00GiB
- 当前缓存量(CACHED):0.00B
- 缓存系统容量(CACHE CAPACITY):200.00GiB
- 数据集缓存百分比(CACHED PERCENTAGE): 0.0%
- Dataset 状态(PHASE):Bound,表示已成功部署。
数据缓存预热
Fluid 实现的 Kubernetes 集群内数据访问加速不是什么 Magic Trick:其本质是通过数据分流(Data Offloading)来降低中心存储的访问压力:Fluid 会把需要访问的数据缓存到与应用 Pod 更近的分布式缓存系统(例如:JindoFS、JuiceFS、Alluxio 等)中,于是,与缓存系统位于同一 VPC 网络的应用 Pod,就能够以远比直接访问中心存储带宽更高的 VPC 内网带宽进行数据访问。进一步地,由于对接的是分布式缓存系统,所以当单个缓存系统 Worker 节点提供带宽不足时,可将分布式缓存系统扩容,从而实现数据访问带宽的弹性伸缩,匹配 Serverless 场景下的计算资源弹性。
因此,为了通过数据分流实现高带宽数据访问,在应用 Pod 进行数据访问前执行数据缓存预热是一个“磨刀不误砍柴工”的必要操作。
- 创建 DataLoad CR
在 Fluid 中执行数据缓存预热只需创建如下的 DataLoad CR:
apiVersion: data.fluid.io/v1alpha1
kind: DataLoad
metadata:
name: demo-dataset-warmup
spec:
# 指定需要预热的Dataset
dataset:
name: demo-dataset
namespace: default
loadMetadata: true
target:
- path: / # 指定预热的数据子路径,“/”表示预热整个数据集
replicas: 5 # 预热后数据在缓存系统中的副本数量
$ kubectl create -f dataload.yaml
- 查看预热后 Dataset 状态
查看 DataLoad CR 状态,直至其 PHASE 变为 Complete 状态:
$ kubectl get dataload demo-dataset-warmup
NAME DATASET PHASE AGE DURATION
demo-dataset-warmup demo-dataset Complete 2m38s 2m20s
通过 Duration 可以查看数据预热耗费的时间,上述示例中预热耗时为 2m20s。
在数据缓存预热完成后,Dataset 上相关的缓存状态也会随即更新:
$ kubectl get dataset demo-dataset
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
demo-dataset 30.00GiB 150.00GiB 200.00GiB 100.0% Bound 8m27s
可以看到,数据预热完成后,整个数据集都已经被缓存在了分布式缓存系统中,缓存比例 100.0%,由于预热时指定了预热的缓存副本数量为 5,预热后缓存占用总量为数据集大小的 5 倍。
注:增加缓存副本数量有助于减轻数据访问时对分布式缓存 Worker 节点的单点访问性能瓶颈。
数据访问
紧接着,尝试创建应用 Pod 来访问 OSS 中的数据。我们将会一次性拉起 100 个应用 Pod,让这些 Pod 同时访问 OSS 中的数据文件。这样的数据读取模式在 AI 推理服务弹性扩容、自动驾驶仿真等具体场景中都十分常见。
- 创建数据访问应用
例如:下面是一个 Argo Workflow 应用示例:
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: parallelism-fluid-
spec:
entrypoint: parallelism-fluid
# Argo Workflow Task最大并发数,即同时启动100个Pod
parallelism: 100
podSpecPatch: '{"terminationGracePeriodSeconds": 0}'
podMetadata:
labels:
# 添加如下label打开Fluid对Serverless场景的数据访问支持
alibabacloud.com/fluid-sidecar-target: eci
annotations:
# 启用实例镜像缓存,加速Pod启动过程
k8s.aliyun.com/eci-image-cache: "true"
# 选择Argo Workflow Pod使用的实例规格
k8s.aliyun.com/eci-use-specs: ecs.g6e.4xlarge
templates:
- name: parallelism-fluid
steps:
- - name: domd5sum
template: md5sum
withSequence:
start: "1"
end: "100"
- name: md5sum
container:
imagePullPolicy: IfNotPresent
image: alpine:latest
# 每个pod计算待读取文件的md5sum
command: ["/bin/sh", "-c", "md5sum /data/largefile-30G"]
volumeMounts:
- name: data-vol
mountPath: /data
volumes:
- name: data-vol
persistentVolumeClaim:
claimName: demo-dataset # claimName须与Fluid Dataset名字一致
$ argo submit workflow.yaml
- 查看数据访问应用状态
上述示例的 Argo Workflow 将会一次性拉起 100 个 Pod 进行并行数据访问。待上述 100 个 Pod 全部完成后,可以看到如下结果:
$ argo list
NAME STATUS AGE DURATION PRIORITY
parallelism-fluid-x677t Succeeded 8m 5m 0
查看任务的具体信息:
$ argo get parallelism-fluid-x677t
Name: parallelism-fluid-x677t
Namespace: default
ServiceAccount: unset (will run with the default ServiceAccount)
Status: Succeeded
Conditions:
PodRunning False
Completed True
Created: Wed Sep 07 21:25:30 +0800 (7 minutes ago)
Started: Wed Sep 07 21:25:30 +0800 (7 minutes ago)
Finished: Wed Sep 07 21:31:28 +0800 (1 minute ago)
Duration: 5 minutes 58 seconds
Progress: 100/100
ResourcesDuration: 8h10m22s*(1 alibabacloud.com/vfuse),24h15m6s*(1 cpu),24h15m6s*(100Mi memory) STEP TEMPLATE PODNAME DURATION MESSAGE
parallelism-fluid-x677t parallelism-fluid
└─┬─ domd5sum(0:1) md5sum parallelism-fluid-x677t-2855796525 5m
├─ domd5sum(1:2) md5sum parallelism-fluid-x677t-1226856655 5m
├─ domd5sum(2:3) md5sum parallelism-fluid-x677t-2858910973 5m
├─ domd5sum(3:4) md5sum parallelism-fluid-x677t-2609269875 4m
├─ domd5sum(4:5) md5sum parallelism-fluid-x677t-616770109 5m
├─ domd5sum(5:6) md5sum parallelism-fluid-x677t-3071900311 5m
├─ domd5sum(6:7) md5sum parallelism-fluid-x677t-3841084237 5m
├─ domd5sum(7:8) md5sum parallelism-fluid-x677t-120540963 5m
├─ domd5sum(8:9) md5sum parallelism-fluid-x677t-1353329645 5m
├─ domd5sum(9:10) md5sum parallelism-fluid-x677t-2391364586 5m
├─ domd5sum(10:11) md5sum parallelism-fluid-x677t-4083824607 5m
├─ domd5sum(11:12) md5sum parallelism-fluid-x677t-258640575 5m
├─ domd5sum(12:13) md5sum parallelism-fluid-x677t-3913466863 5m
├─ domd5sum(13:14) md5sum parallelism-fluid-x677t-1949266799 5m
├─ domd5sum(14:15) md5sum parallelism-fluid-x677t-214569823 5m
├─ domd5sum(15:16) md5sum parallelism-fluid-x677t-684353087 5m
可以看到,整个任务的运行时长为 5m58s。
资源回收
- 数据缓存资源回收
用户可以在不再需要数据缓存时,将缓存从 ASK 集群中回收以节省集群资源并降低成本。Fluid 中对于缓存系统的回收仅需要将关联的 Fluid Dataset 删除,例如:
$ kubectl delete dataset demo-dataset
执行上述删除命令后等待一段时间(Fluid 将会进行一些清理工作),缓存系统的相关 Pod 都会被回收。
- Fluid 控制面组件回收
在缓存系统相关 Pod 回收后,用户同样可以试情况回收控制面组件占用的资源。执行下面的脚本,缩容控制面组件。
$ kubectl get deployments.apps -n fluid-system | awk 'NR>1 {print $1}' | xargs kubectl scale deployments -n fluid-system --replicas=0
当再次需要使用 Fluid 时,执行下面的扩容命令,创建新的控制面组件 Pod 即可:
$ kubectl scale -n fluid-system deployment dataset-controller --replicas=1 $ kubectl scale -n fluid-system deployment fluid-webhook --replicas=1
方案效果
多次运行上述示例,并调整缓存系统 Worker 的数量(5 个或 10 个)或选择直接访问 OSS 对象存储,我们得到了如下效果数据:
效果 1:可弹性伸缩的数据访问带宽
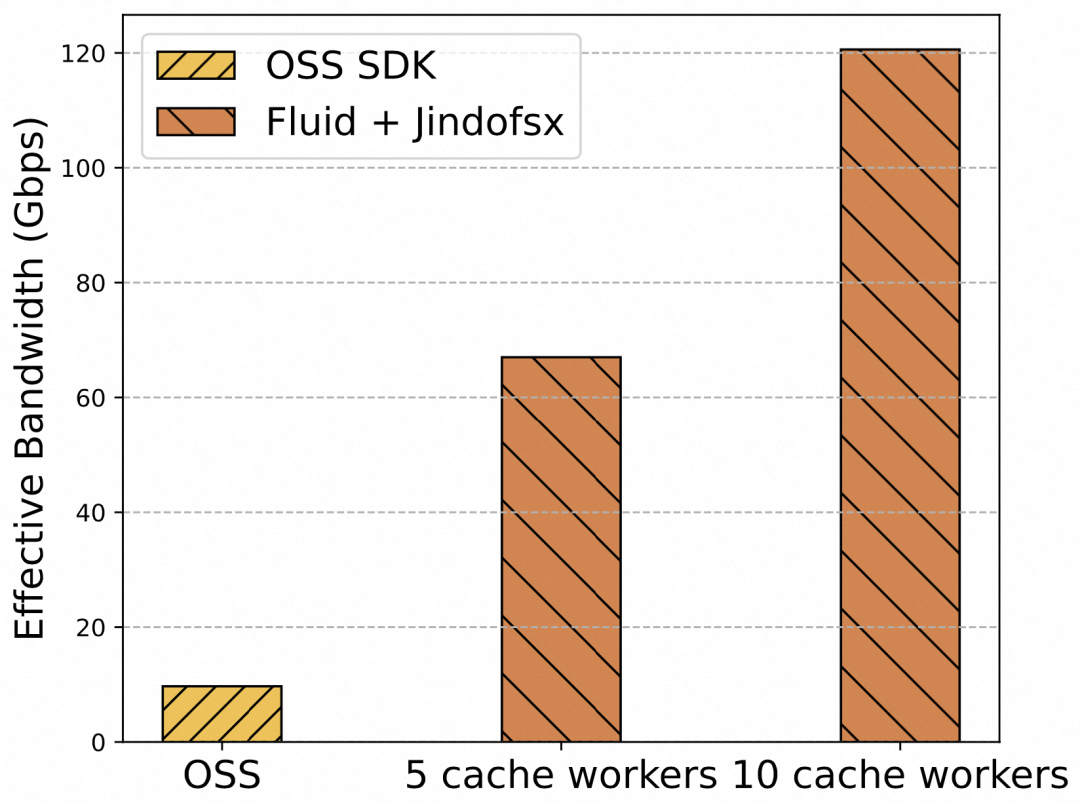
图 1 缓存/存储系统提供的有效数据访问带宽对比
根据数据访问应用的整体耗时、访问的数据文件大小以及数据访问的 Pod 数量,我们可以计算出图 1 中的“有效数据访问带宽*”性能表现。从图 1 来看,相比于 OSS 存储系统提供的默认带宽(10Gbps),Fluid 的数据分流机制可以为 Serverless 应用提供更大的有效访问带宽,并且该带宽可通过增加缓存 Worker 节点数量弹性提升。
*有效数据访问带宽 = Serverless 数据访问 Pod 数量 x 每 Pod 访问的数据量 / 数据访问应用整体耗时
效果 2:因数据访问加速而降低的费用成本
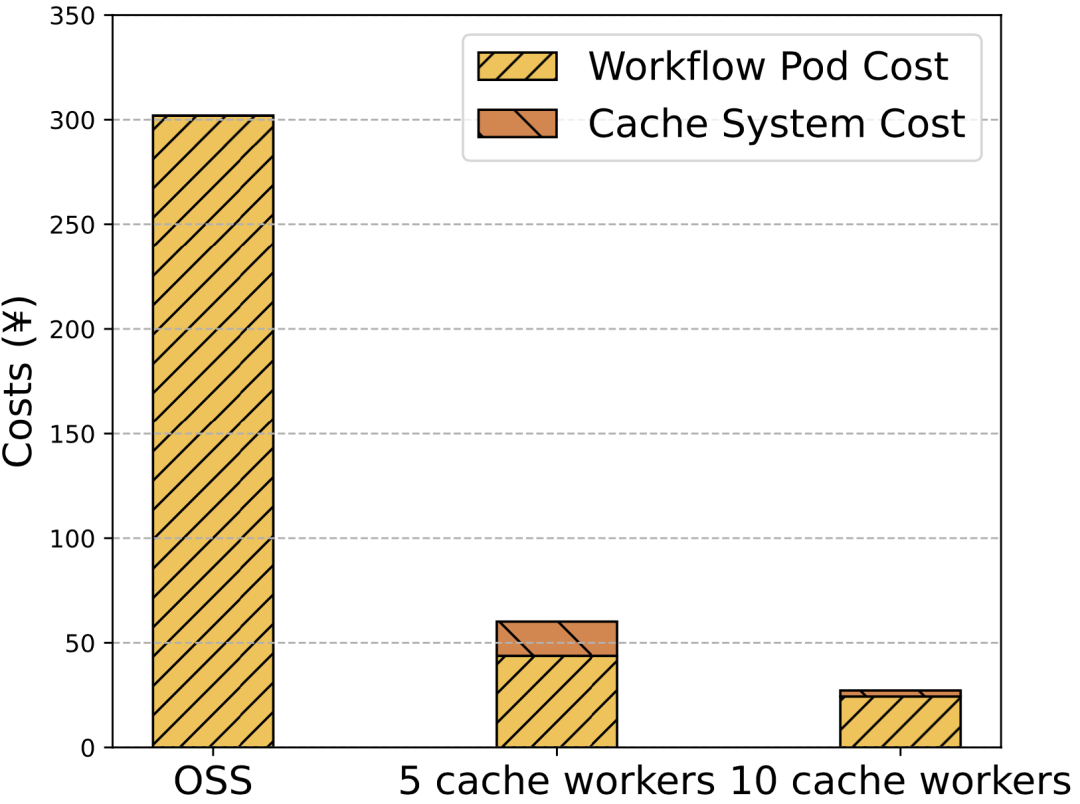
图 2 直接访问 OSS vs. Fluid 成本对比
上述示例中我们使用如下的 ECI 实例规格:
- Argo Workflow 任务 Pod:ecs.g6e.4xlarge (每秒单价 0.0012 元)
- 缓存系统 Pod:ecs.d1ne.6xlarge (每秒单价 0.0056 元)
由此可计算得到“图 2 直接访问 OSS vs. Fluid 成本对比”。观察图 2 不难发现,通过 Fluid 访问 OSS 中的数据能够将成本削减为原来的约六分之一到八分之一。另外,在同样使用 Fluid 访问数据的前提下,使用更多的缓存 Worker 节点可以节省更多成本。这背后的主要原因是 Fluid 提供了更大的数据访问带宽,从而使得数据访问性能提升,缩短了应用花在数据读取上的时间(见图 3),从而使得购买的 Serverless 弹性算力真正做到物尽其用。
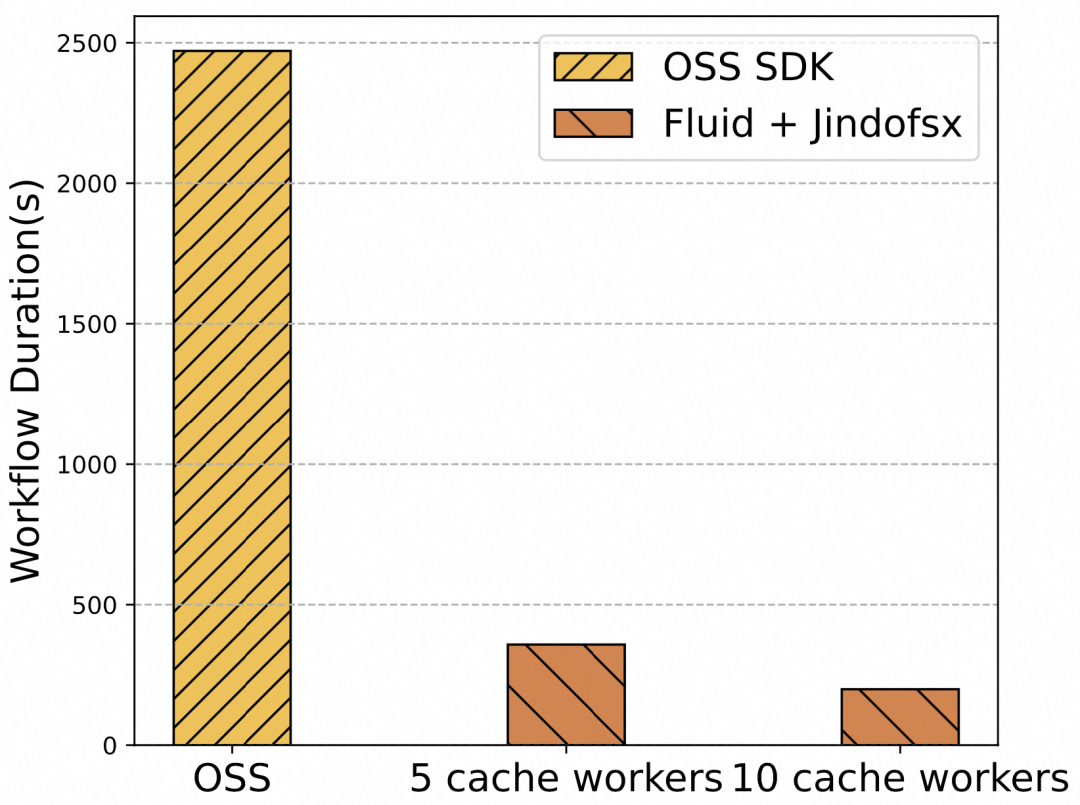
图 3 Argo Workflow 任务耗时对比
总结
本文展示了一个在 ASK 环境中运行 Fluid 的完整数据访问示例,希望能够帮助大家了解 Fluid 的使用体验、运行效果以及 Serverless 和数据密集型应用结合的更多可行性。具体而言,我们看到:
- 用户使用 Fluid 访问数据是简单易用的:用户只需要把原来访问 OSS 的 PVC 修改为 Fluid Dataset 对应的 PVC。
- Fluid 能够提供可弹性伸缩的数据访问带宽,帮助规模化的数据访问应用提升数据读取效率。
- 由于数据读取效率的提升,Fluid 能够帮助规模化的数据访问应用大幅降低费用成本。
参考链接
[1] 如何创建 ASK 集群:
https://help.aliyun.com/document_detail/86377.html
[2] ACK 云原生 AI 套件详情:
https://help.aliyun.com/document_detail/201994.html
[3] Fluid 项目 github 地址:
https://github.com/fluid-cloudnative/fluid
点击此处,申请 ACK 云原生 AI 套件免费体验席位!
Fluid 助力阿里云 Serverless 容器极致提速的更多相关文章
- 阿里云弹性容器实例产品 ECI ——云原生时代的基础设施
阿里云弹性容器实例产品 ECI ——云原生时代的基础设施 1. 什么是 ECI 弹性容器实例 ECI (Elastic Container Instance) 是阿里云在云原生时代为用户提供的基础计算 ...
- 阿里云Serverless应用引擎(SAE)3大核心优势全解析
软件发展到今,企业业务系统日趋复杂,开发一个业务系统需要掌握和关注的知识点越来越多.除实现业务逻辑本身,还需考虑很多非业务的基础技术系统:如分布式cache和队列.基础服务能力集成.容量规划.弹性伸缩 ...
- 中国唯一入选 Forrester 领导者象限,阿里云 Serverless 全球领先
3 月 26 日消息,权威咨询机构 Forrester 发布 2021 年第一季度 FaaS 平台评估报告,阿里云函数计算凭借在产品能力.安全性.战略愿景和市场规模等方面的优势脱颖而出,产品能力位列全 ...
- 专访阿里云 Serverless 负责人:无服务器不会让后端失业
2012 年,云基础设施服务提供商 Iron.io 的副总裁 Ken 谈到软件开发行业的未来,首次提出了 Serverless 的概念,为云中运行的应用程序描述了一种全新的系统体系架构.此后,以 AW ...
- 阿里云 Serverless 应用引擎(SAE)发布 v1.2.0,支持一键启停、NAS 存储、小规格实例等实用特性
近日,阿里云 Serverless 应用引擎(SAE)发布 v1.2.0版本,新版本实现了以下新功能/新特性: 一键启停开发测试环境:企业开发测试环境一般晚上不常用,长期保有应用实例,闲置浪费很高.使 ...
- 阿里云 Serverless 再升级,从体验上拉开差距
差距都在细节上. Serverless 要成就云计算的下一个 10 年,不仅需要在技术上持续精进,也需要在产品体验上精耕细作. 近日,阿里云 Serverless 再度升级,发布了一系列围绕产品体验方 ...
- 云计算之路-阿里云上-容器难容:容器服务故障以及自建 docker swarm 集群故障
3月21日,由于使用阿里云服务器自建 docker swarm 集群的不稳定,我们将自建 docker swarm 集群上的所有应用切换阿里云容器服务 swarm 版(非swarm mode). 3月 ...
- 倒计时 | 7.24 阿里云 Serverless Developer Meetup 杭州站报名火热进行中!
本周六阿里云 Serverless Developer Meetup 即将亮相杭州 时间:7.24 本周六 13:30 - 17:30 地点:杭州市良睦路 999 号乐佳国际 1-3-7 特洛伊星 ...
- PouchContainer 容器技术演进助力阿里云原生升级
点击下载<不一样的 双11 技术:阿里巴巴经济体云原生实践> 作者 | 杨育兵(沈陵) 阿里巴巴高级技术专家 我们从 2016 年开始在集团推广全面的镜像化容器化,今年是集团全面镜像化容器 ...
- 云计算之路-阿里云上-容器难容:自建docker swarm集群遭遇无法解决的问题
我们从今年6月开始在生产环境进行 docker 容器化部署,将已经迁移至 ASP.NET Core 的站点部署到 docker swarm 集群上.开始我们选用的阿里云容器服务,但是在使用过程中我们遭 ...
随机推荐
- 50HZ陷波器的原理和实物开发设计
原理 陷波滤波器指的是一种可以在某一个频率点迅速衰减输入信号,以达到阻碍此频率信号通过的滤波效果的滤波器.陷波滤波器属于带阻滤波器的一种,只是它的阻带非常狭窄,起阶数必须是二阶(含二阶)以上. ...
- 怎样给U盘加密
给U盘加密其实很简单,下载一个叫U盘超级加密3000的U盘加密软件就可以了. 这款U盘加密的软件最大的特点是不用安装,只要一个exe文件.你把它放到你需要加密的U盘里,就可以加密U盘里的数据了.并且到 ...
- TTS 擂台: 文本转语音模型的自由搏击场
对文本转语音 (text-to-speech, TTS) 模型的质量进行自动度量非常困难.虽然评估声音的自然度和语调变化对人类来说是一项微不足道的任务,但对人工智能来说要困难得多.为了推进这一领域的发 ...
- 【Django】HTML如何显示富文本内容
一.背景 我采用的前端样式是 LayUI,通过它的富文本编辑器保存内容到数据库后,遇到了一个回显到页面的问题 二.方案 在不考虑使用 Vue 的情况下,有一种简单的方式 <div id=&quo ...
- C++ Qt开发:QTcpSocket网络通信组件
Qt 是一个跨平台C++图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本章将重点介绍如何运用QTc ...
- 英语文档阅读学习系列之ZYNQ-7000 All Programmable SOC Packaging and Pinout
UG865-Zynq-7000-pkg-pinout 1.Table 一个overview和其他部分的构成一个整体. 2.overview This section describes the pin ...
- Oracle 触发器迁移至KingbaseES常见的问题
oracle数据库的触发器迁移到KingbaseES的时候经常会出现一下两类错误: 1.SQL 错误 [42809]: 错误: "xxxxxxxx" 是一个视图.Detail: 视 ...
- KingbaseES V8R3 集群运维案例 --操作系统‘soft lockup’引起的failover切换
案例说明: 在国产中标麒麟系统生产环境中,监控发现KingbaseES V8R3集群发生了failover的主备切换,客户需要给出分析报告,说明此次集群发生failover切换的原因,本次文档通过分析 ...
- 【Java】归并排序
代码: 1 public static void mergeSort(int[] arr) { 2 if (arr == null || arr.length < 2) { 3 return; ...
- Linux内核数据管理利器--红黑树
目录 写在前面 1. 红黑树的原理 2. 红黑树操作 2.1 红黑树的节点插入 2.2 红黑树的节点删除 2.3 红黑树的查询操作 3. 红黑树操作实验 附录A: 实验代码 写在前面 本文通过两个方面 ...