7.18考试总结(NOIP模拟19)[u·v·w]
我们不是狼,我们只是长着獠牙的羊......
前言
我真 TM 爱死 \(\frac{1}{4}\) 了。
老实说,这套题是真恶心,第一题还有一点思路,到了后面是一点都搞不定了。
总的来说,主要原因是最近几天状态有些不好,需要及时调整。。
T1 u
解题思路
主要就是二维差分,对于一般的差分而言,都是以行和列进行差分。
由于这个题是一个直角三角形,因此我们需要改变一下差分的“方向”。
对于列和斜的方向进行差分(假设 1 数组为列方向的差分数组, 2 数组为斜着的),以下图为例。
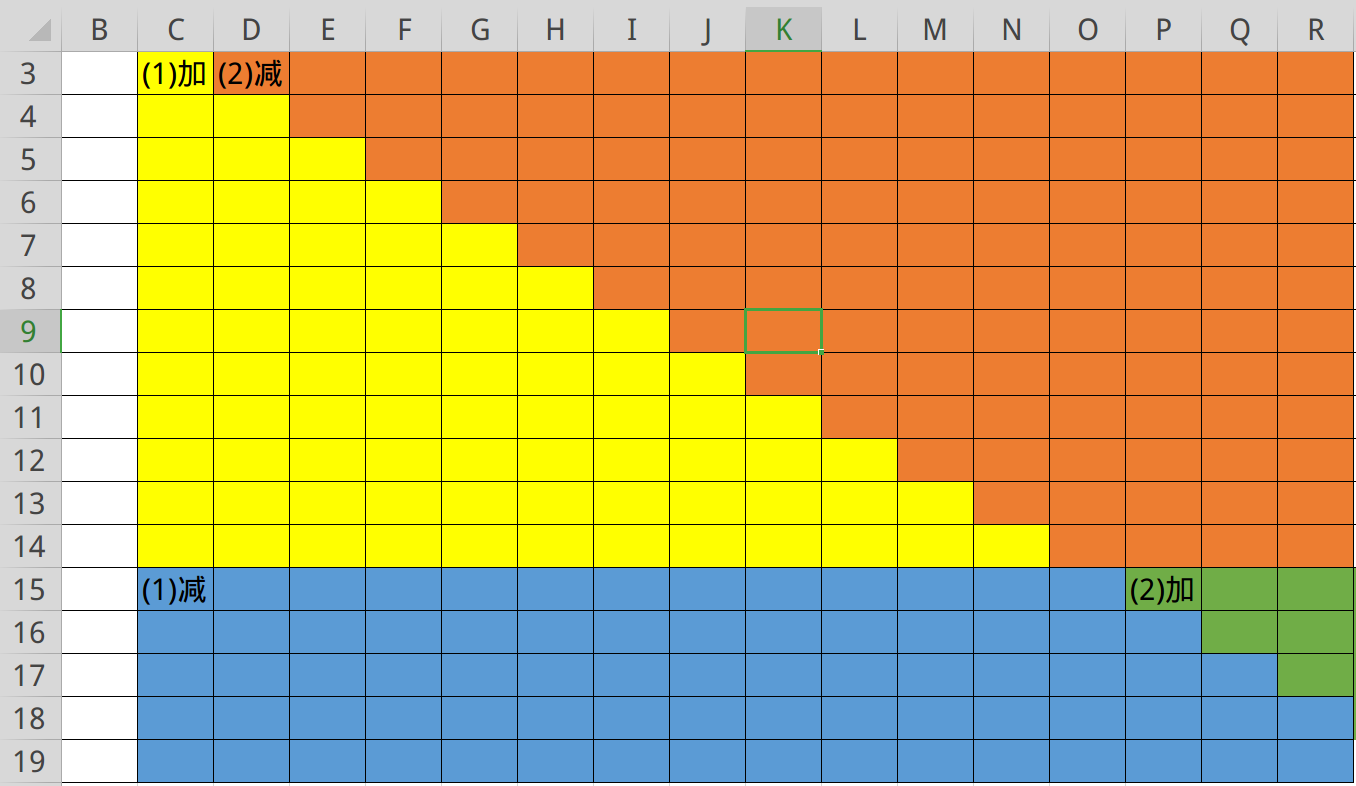
当我们需要给黄色区域加上数时,先给 \((3.C)\) 位置的 1 加上,那我们就相当与给所有的有颜色的位置都加上了。
因此在 \((15,C)\) 位置的 1 减去就可以除去在蓝色以及绿色区域多加上的数。
接下来考虑如何除去橙色部分的影响,可以看作这个大的三角形减去绿色部分。
于是就可以给 \((3,D)\) 位置的 2 减去,给 \((15,P)\) 位置的 2 加上就好了。
code
#include<bits/stdc++.h>
#define int long long
using namespace std;
inline int read()
{
int x=0,f=1;
char ch=getchar();
while(ch>'9'||ch<'0')
{
if(ch=='-') f=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9')
{
x=(x<<1)+(x<<3)+(ch^48);
ch=getchar();
}
return x*f;
}
const int N=1e3+10;
int n,m,ans,q1[N][N],q2[N][N];
void solve(int x,int y,int len,int num)
{
q1[x][y]+=num;
if(y+1<=n) q2[x][y+1]-=num;
if(x+len<=n)
{
q1[x+len][y]-=num;
if(y+len+1<=n)
q2[x+len][y+len+1]+=num;
}
}
signed main()
{
n=read();
m=read();
for(int i=1,x,y,len,num;i<=m;i++)
{
x=read();
y=read();
len=read();
num=read();
solve(x,y,len,num);
}
for(int i=1;i<=n;i++)
{
int num=0;
for(int j=1;j<=n;j++)
{
q1[i][j]+=q1[i-1][j];
q2[i][j]+=q2[i-1][j-1];
num+=q1[i][j]+q2[i][j];
ans^=num;
}
}
printf("%lld",ans);
return 0;
}
T2 v
解题思路
正解比较简单粗暴。。
其实就是记忆化状压暴搜,有一个需要注意的点就是对于比较小的用数组,大的用 map 这样可以大大缩小空间。
当然也可以“特判”过。。(不难发现当序列中白色和黑色数量相同时,并且操作数为 n 或者 n-1 的时候期望值一定是\(\dfrac{n}{2}\))
然后对于状压中去除第 i 位并且将它之后的向左移一位的操作有两种实现:
(sta>>i<<i-1)|(sta&(1<<i-1)-1)(sta>>1&~((1<<i-1)-1))|(sta&(1<<i-1)-1)
然后,也就没啥好说的了。。。
code
#include<bits/stdc++.h>
#define int long long
using namespace std;
inline int read()
{
int x=0,f=1;
char ch=getchar();
while(ch>'9'||ch<'0')
{
if(ch=='-') f=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9')
{
x=(x<<1)+(x<<3)+(ch^48);
ch=getchar();
}
return x*f;
}
const int N=35;
map<int,double> f[N];
int n,m,s;
string ch;
double dfs(int sta,int pos)
{
if(pos==n-m) return 0;
if(f[pos].find(sta)!=f[pos].end()) return f[pos][sta];
double sum=0;
for(int i=1;i<=pos/2;i++)
{
int clo1=(sta>>(i-1))&1,clo2=(sta>>(pos-i))&1;
int t1=(sta>>i<<i-1)|(sta&(1<<i-1)-1);
int t2=(sta>>(pos-i+1)<<pos-i)|(sta&((1<<pos-i)-1));
sum+=2*max(dfs(t1,pos-1)+clo1,dfs(t2,pos-1)+clo2);
}
if(pos&1)
{
int i=(pos+1)/2;
int clo=(sta>>(i-1))&1;
int temp=(sta>>1&~((1<<i-1)-1))|(sta&(1<<i-1)-1);
sum+=dfs(temp,pos-1)+clo;
}
sum=sum/(1.0*pos);
f[pos][sta]=sum;
return sum;
}
void check()
{
if(n&1||(m!=n-1&&m!=n))
return ;
int h=0,b=0;
for(int i=0;i<n;i++)
if(ch[i]=='W') b++;
else h++;
if(h!=b) return ;
printf("%.10lf",(double)n/2.0);
exit(0);
}
signed main()
{
n=read();
m=read();
cin>>ch;
check();
for(int i=1;i<=n;i++)
s=(s<<1)|(ch[i-1]=='W');
printf("%.20lf",dfs(s,n));
return 0;
}
T3 w
解题思路
树形 DP 设 f[i][1/0] 表示节点 i 是否与父亲连边。
设我们要翻转的边集为S,那么我们的最少的路径条数就是这个边集所能连接的点中度数为奇数的点的一半,
其实是那些可以配对为偶数的边都可以连成一条,所以只有奇数点才为路径的端点而且需要除以2
这样我们就会有一个状态了,状态中有两个量,一个是路径条数,一个是边的数量。
对于奇数点而言,其实就像相当与是好几对点,加上一个点,如果再加上一条边就不会增加操作次数。
偶数点也类似。对于 DP 方程的转移就好似 奇数+奇数=偶数 这一类的东西了。。。
code
#include<bits/stdc++.h>
#define int long long
using namespace std;
inline int read()
{
int x=0,f=1;
char ch=getchar();
while(ch>'9'||ch<'0')
{
if(ch=='-') f=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9')
{
x=(x<<1)+(x<<3)+(ch^48);
ch=getchar();
}
return x*f;
}
const int N=1e5+10,M=N<<1,INF=1e9;
int n;
int tot,head[N],nxt[M],ver[M],edge[M];
struct Node
{
int opt,len;
Node friend operator + (Node x,Node y)
{
return (Node){x.opt+y.opt,x.len+y.len};
}
bool friend operator < (Node x,Node y)
{
if(x.opt!=y.opt)
return x.opt<y.opt;
return x.len<y.len;
}
}f[N][2];
void add_edge(int x,int y,int val)
{
ver[++tot]=y;
edge[tot]=val;
nxt[tot]=head[x];
head[x]=tot;
}
Node min(Node x,Node y)
{
if(x<y) return x;
return y;
}
void dfs(int x,int fa,int opt)
{
Node k1=(Node){INF,INF},k2=(Node){0,0};
for(int i=head[x];i;i=nxt[i])
{
int to=ver[i];
if(to==fa) continue;
dfs(to,x,edge[i]);
Node tmp1=min(k1+f[to][0],k2+f[to][1]);
Node tmp2=min(k1+f[to][1],k2+f[to][0]);
k1=tmp1;
k2=tmp2;
}
if(opt==1||opt==2) f[x][1]=min((Node){k1.opt,k1.len+1},(Node){k2.opt+1,k2.len+1});
else f[x][1]=(Node){INF,INF};
if(opt==0||opt==2) f[x][0]=min((Node){k1.opt+1,k1.len},k2);
else f[x][0]=(Node){INF,INF};
}
signed main()
{
n=read();
for(int i=1,x,y,c,d,temp;i<n;i++)
{
x=read();
y=read();
c=read();
d=read();
if(d==2) temp=2;
else temp=(c!=d);
add_edge(x,y,temp);
add_edge(y,x,temp);
}
dfs(1,0,2);
printf("%lld %lld",f[1][0].opt/2,f[1][0].len);
return 0;
}
7.18考试总结(NOIP模拟19)[u·v·w]的更多相关文章
- 8.18考试总结[NOIP模拟43]
又挂了$80$ 好气哦,但要保持优雅.(草 T1 地衣体 小小的贪心:每次肯定从深度较小的点向深度较大的点转移更优. 模拟一下,把边按链接点的子树最大深度排序,发现实际上只有上一个遍历到的点是对当前考 ...
- [考试总结]noip模拟19
连挂3场 \(\color{green}{\huge{\text{菜}}}\) 真 . 挂分王 ... 没什么好说的了,菜就是了. \(T1\) 一波手推想到了性质 \(1\),然后因为数组原因挂成比 ...
- 8.3考试总结(NOIP模拟19)[最长不下降子序列·完全背包问题·最近公共祖先]
一定要保护自己的梦想,即使牺牲一切. 前言 把人给考没了... 看出来 T1 是一个周期性的东西了,先是打了一个暴力,想着打完 T2 T3 暴力就回来打.. 然后,就看着 T2 上头了,后来发现是看错 ...
- 2021.10.18考试总结[NOIP模拟76]
T1 洛希极限 不难发现每个点肯定是被它上一行或上一列的点转移.可以预处理出每个点上一行,上一列最远的能转移到它的点,然后单调队列优化. 预处理稍显ex.可以用并查集维护一个链表,记录当前点之后第一个 ...
- 2021.9.18考试总结[NOIP模拟56]
T1 爆零 贪心地想,肯定要先走完整个子树再走下一个,且要尽量晚地走深度大的叶子.所以对每个点的儿子以子树树高为关键字排序$DFS$即可. 也可$DP$. $code:$ T1 #include< ...
- NOIP 模拟 $19\; \rm v$
题解 一道概率与期望的状压题目 这种最优性的题目,我们一般都是倒着转移,因为它的选择是随机的所以我们无法判断从左还是从右更有,所以我们都搜一遍 时间一定会爆,采用记忆化搜索,一种状态的答案一定是固定的 ...
- 6.17考试总结(NOIP模拟8)[星际旅行·砍树·超级树·求和]
6.17考试总结(NOIP模拟8) 背景 考得不咋样,有一个非常遗憾的地方:最后一题少取膜了,\(100pts->40pts\),改了这么多年的错还是头一回看见以下的情景... T1星际旅行 前 ...
- 5.23考试总结(NOIP模拟2)
5.23考试总结(NOIP模拟2) 洛谷题单 看第一题第一眼,不好打呀;看第一题样例又一眼,诶,我直接一手小阶乘走人 然后就急忙去干T2T3了 后来考完一看,只有\(T1\)骗到了\(15pts\)[ ...
- 5.22考试总结(NOIP模拟1)
5.22考试总结(NOIP模拟1) 改题记录 T1 序列 题解 暴力思路很好想,分数也很好想\(QAQ\) (反正我只拿了5pts) 正解的话: 先用欧拉筛把1-n的素数筛出来 void get_Pr ...
- Noip模拟19(炸裂的开始) 2021.7.18
T1 u 差分与前缀的综合练习. 分析数据范围,只能是在修改的时候$O(1)$做到,那么只能是像打标记一样处理那个三角形 正解是建立两个二位前缀和,一个控制竖向,一个控制斜向 每次在三角的左上,右下, ...
随机推荐
- 重新点亮shell————特殊符号[五]
前言 简单整理一下特殊符号. 正文 特殊符号大全: 引号 ' 完成引用 "" 不完全引用 ` 执行命令 括号 () (()) $() 圆括号 单独使用圆括号会产生一个子shell ...
- react native 使用typescript
前言 TypeScript作为JavaScript的一个富类型扩展语言,深受代码风格严谨的前端开发者欢迎.但在react-native下,因为packager的配置困难,使用TypeScript一直是 ...
- 重新整理数据结构与算法(c#)—— 算法套路分治算法[二十五]
前言 有一个汉罗塔的游戏如下: 汉诺塔:汉诺塔(又称河内塔)问题是源于印度一个古老传说的益智玩具. 大梵天创造世界的时候做了三根金刚石柱子,在一根柱子上从下往上按照大小顺序摞着64片黄金圆盘. 大梵天 ...
- 力扣180(MySQL)-连续出现的数字(中等)
题目: 编写一个 SQL 查询,查找所有至少连续出现三次的数字. 返回的结果表中的数据可以按 任意顺序 排列. 查询结果格式如下面的例子所示: 解题思路: 原表数据: 方法一: 使用内连接(inner ...
- 二叉查找树的实现C/C++
二叉查找树是一种关键字有序存放的二叉树.在不含重复关键字的二叉查找树中,关键字"较小"的节点一定在关键字"较大"的节点的左子树中,"较小"一 ...
- [ARC174B] Bought Review 题解
[题目描述] 你开了一家店,有 \(A_i\) 个 \(i\) 星级评论,你可以花费 \(P_i\) 元买到一个 \(i\) 星评论,问使得这家店评论的星星平均值不小于 \(3\),最少要花多少钱. ...
- OpenSergo 正式开源,多家厂商共建微服务治理规范和实现
简介 OpenSergo,Open 是开放的意思,Sergo 则是取了服务治理两个英文单词 Service Governance 的前部分字母 Ser 和 Go,合起来即是一个开放的服务治理项目. ...
- 阿里云飞天论文获国际架构顶会 ATC 2021最佳论文:全球仅三篇
简介: 近日,计算机系统结构国际顶级学术会议 USENIX ATC在线上举行.ATC 始办于1992年,是由USENIX组织的计算机系统领域的顶级会议,至今已成功举办31届,计算机系统领域中Oak语言 ...
- Serverless 工程实践 | Serverless 应用开发观念的转变
简介: Serverless 架构带来的除了一种新的架构.一种新的编程范式,还包括思路上的转变,尤其是开发过程中的一些思路转变.有人说要把 Serverless 架构看成一种天然的分布式架构,需要用 ...
- Flink 在顺丰的应用实践
简介: 顺丰基于 Flink 建设实时数仓的思路,引入 Hudi On Flink 加速数仓宽表,以及实时数仓平台化建设的实践. 本⽂由社区志愿者苗文婷整理,内容源⾃顺丰科技大数据平台研发工程师龙逸 ...