【深度学习】c++部署onnx模型(Yolov5、PP-HumanSeg、GoogLeNet、UNet)
这两天部署了好多模型,记录一下。代码链接。
- onnxruntime在第一张图的推理上比opencv快很多,但在后面的图上略微慢了一点。

- 不同的模型的部署时的输出不同,处理时需要对输出比较了解,下面分别处理了目标检测、语义分割和分类模型的输出。
onnxruntime模型部署
例1:onnxruntime部署PP-HumanSeg语义分割模型
根据博客的代码做了一点补充:多图并行推理
1. 生成模型时更改inputshape,想要并行推理几张图就写几。
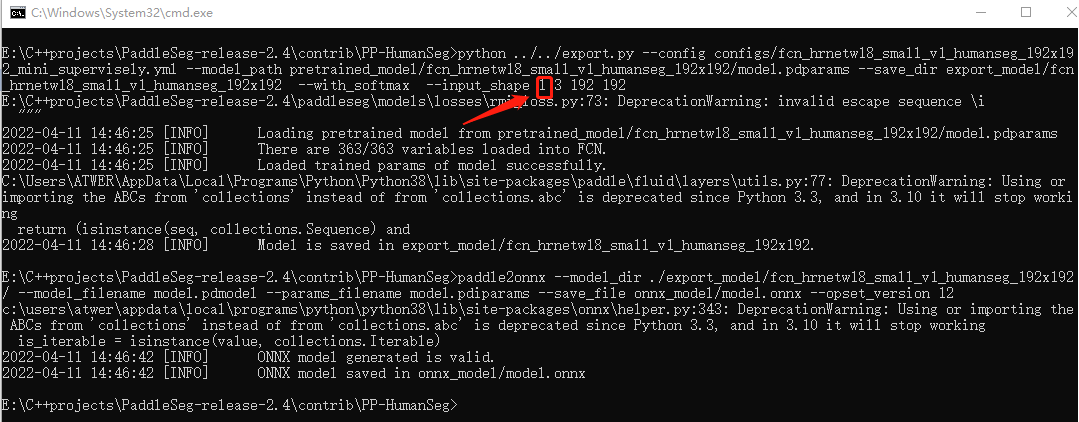
2. 加载模型时选择对应的.onnx
3. 改输入维度
HumanSeg human_seg(model_path, 1, { 3, 3, 192, 192 });//3张
HumanSeg human_seg(model_path, 1, { 8, 3, 192, 192 });//8张
4. 在推理前,将多张图放入vector,后处理时多一层遍历
void HumanSeg::predict_images_together(const std::string& imgpath) {
std::vector<std::string> filenames;
cv::glob(imgpath, filenames);
cv::Mat src, dst;
std::vector<cv::Mat> src_images;
std::vector<cv::Mat> in_images;
int image_count = filenames.size();
clock_t start{ clock() }, end;
//预处理
for (size_t i = 0; i < image_count; ++i) {
src = cv::imread(filenames[i]);
src_images.push_back(src);
dst = preprocess(src);
in_images.push_back(dst);
}
cv::Mat blob = cv::dnn::blobFromImages(in_images, 1, input_size, cv::Scalar(0, 0, 0), false, true);
//推理
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
input_tensors_.emplace_back(Ort::Value::CreateTensor<float>(memory_info, blob.ptr<float>(), blob.total(), input_node_dims_.data(), input_node_dims_.size()));
std::vector<Ort::Value> output_tensors_ = session_.Run(
Ort::RunOptions{ nullptr },
input_node_names_.data(),
input_tensors_.data(),
input_node_names_.size(),
out_node_names_.data(),
out_node_names_.size()
);
int64* floatarr = output_tensors_.front().GetTensorMutableData<int64>();
//后处理
std::vector<cv::Mat> out_images;
for(int k=0;k< image_count;k++){
cv::Mat mask = cv::Mat::zeros(input_size, CV_8UC1);
for (int i{ 0 }; i < static_cast<int>(input_node_dims_[2]); i++) {
for (int j{ 0 }; j < static_cast<int>(input_node_dims_[3]); ++j) {
mask.at<uchar>(i, j) = static_cast<uchar>(floatarr[i * static_cast<int>(input_node_dims_[3]) + j + k * 192 * 192]);
}
}
cv::resize(mask, mask, cv::Size(image_w, image_h));
cv::Mat mask1 = mask * 255;
cv::Mat predict_image;
cv::bitwise_and(src_images[k], src_images[k], predict_image, mask = mask);
out_images.push_back(predict_image);
cv::imwrite(imgpath +"\\" +std::to_string(k) + ".jpg", predict_image);
}
end = clock();
std::cout << (end - start)/ image_count*1.0 << std::endl;
input_tensors_.clear();
return;
}
例2:onnxruntime部署googlenet 4分类模型
void onnxruntime::predict(cv::Mat& blob)
{
clock_t start{ clock() }, end;
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault); input_tensors_.emplace_back(Ort::Value::CreateTensor<float>(memory_info, blob.ptr<float>(), blob.total(), input_node_dims_.data(), input_node_dims_.size())); std::vector<Ort::Value> output_tensors_ = session_.Run(
Ort::RunOptions{ nullptr },
input_node_names_.data(),
input_tensors_.data(),
input_node_names_.size(),
out_node_names_.data(),
out_node_names_.size());
float* floatarr = output_tensors_[0].GetTensorMutableData<float>();
end = clock();
std::cout << "onnxruntime:" << end - start << "ms" << std::endl;
for (int i = 0; i < 4; i++) {
std::cout << *floatarr++ << std::endl;
}
}
结果:(最大数的索引就是类别)

opencv::dnn模型部署
例1:Yolov5 3分类检测模型部署
#include"yolov5_dnn.h"
using namespace cv; //初始化网络,classname
void YOLOv5Detector::initConfig(std::string onnxpath, string classpath, int iw, int ih, float threshold) {
this->input_w = iw;
this->input_h = ih;
this->threshold_score = threshold;
this->net = cv::dnn::readNetFromONNX(onnxpath);
this->class_list = readClassNames(classpath);
} //检测
void YOLOv5Detector::detect(cv::Mat& frame, std::vector<DetectResult>& results) { //图像预处理
int w = frame.cols;
int h = frame.rows;
int _max = std::max(h, w);
cv::Mat image = cv::Mat::zeros(cv::Size(_max, _max), CV_8UC3);
cv::Rect roi(0, 0, w, h);
frame.copyTo(image(roi)); float x_factor = image.cols / 640.0f;
float y_factor = image.rows / 640.0f; // 推理
cv::Mat blob = cv::dnn::blobFromImage(image, 1 / 255.0, cv::Size(this->input_w, this->input_h), cv::Scalar(0, 0, 0), true, false);
this->net.setInput(blob);
cv::Mat preds = this->net.forward(); // 后处理, 1x25200x8
std::cout << "rows: "<< preds.size[1]<< " data: " << preds.size[2] << std::endl;
cv::Mat det_output(preds.size[1], preds.size[2], CV_32F, preds.ptr<float>());
float confidence_threshold = 0.5;
std::vector<cv::Rect> boxes;
std::vector<int> classIds;
std::vector<float> confidences;
for (int i = 0; i < det_output.rows; i++) {
float confidence = det_output.at<float>(i, 4); if (confidence < 0.4) {
continue;
} cv::Mat classes_scores = det_output.row(i).colRange(5, 8);//此处改动了,因为是三分类,所以输出中先是xywh,confidence,然后是3个类别的分数
cv::Point classIdPoint;
double score;
minMaxLoc(classes_scores, 0, &score, 0, &classIdPoint); // 置信度 0~1之间
if (score > this->threshold_score)
{
float cx = det_output.at<float>(i, 0);
float cy = det_output.at<float>(i, 1);
float ow = det_output.at<float>(i, 2);
float oh = det_output.at<float>(i, 3);
int x = static_cast<int>((cx - 0.5 * ow) * x_factor);
int y = static_cast<int>((cy - 0.5 * oh) * y_factor);
int width = static_cast<int>(ow * x_factor);
int height = static_cast<int>(oh * y_factor);
cv::Rect box;
box.x = x;
box.y = y;
box.width = width;
box.height = height; boxes.push_back(box);
classIds.push_back(classIdPoint.x);
confidences.push_back(score);
}
} // NMS
std::vector<int> indexes;
cv::dnn::NMSBoxes(boxes, confidences, 0.25, 0.45, indexes);
for (size_t i = 0; i < indexes.size(); i++) {
DetectResult dr;
int index = indexes[i];
int idx = classIds[index];
dr.box = boxes[index];
dr.classId = idx;
dr.score = confidences[index];
cv::rectangle(frame, boxes[index], cv::Scalar(0, 255, 0), 2, 8);
cv::rectangle(frame, cv::Point(boxes[index].tl().x, boxes[index].tl().y - 20),
cv::Point(boxes[index].br().x, boxes[index].tl().y), cv::Scalar(0, 255, 0), -1);
cv::putText(frame, class_list[idx], cv::Point(boxes[index].tl().x, boxes[index].tl().y), cv::FONT_HERSHEY_SIMPLEX, 1, cv::Scalar(255, 0, 0),2);
results.push_back(dr);
} std::ostringstream ss;
std::vector<double> layersTimings;
double freq = cv::getTickFrequency() / 1000.0;
double time = net.getPerfProfile(layersTimings) / freq;
ss << "FPS: " << 1000 / time << " ; time : " << time << " ms";
putText(frame, ss.str(), cv::Point(50, 40), cv::FONT_HERSHEY_SIMPLEX, 2.0, cv::Scalar(255, 0, 0), 2, 8);
imshow("result", frame);
waitKey();
} // 读取txt文件
vector<string> YOLOv5Detector::readClassNames(string classpath)
{
vector<String> classNames;
ifstream fp(classpath);
if (!fp.is_open())
{
printf("could not open file...\n");
exit(-1);
}
std::string name;
while (!fp.eof())
{
std::getline(fp, name);
if (name.length())
classNames.push_back(name);
}
fp.close();
return classNames;
}
结果:

例2:opencv部署googlenet 4分类模型




做的是点胶的四分类,用的googlenet,准确率98.6%。
代码:
int main() {
string modelpath = "../googlenet.onnx";
try {
Mat img = imread("../3.jpg");
resize(img, img, Size(128, 128));
cvtColor(img, img, cv::COLOR_BGR2RGB);
img.convertTo(img, CV_32F, 1.0 / 255.0);
cv::Scalar default_mean(0.5, 0.5, 0.5);
cv::Scalar default_std(0.5, 0.5, 0.5);
cv::subtract(img, default_mean, img);
cv::divide(img, default_std, img);
Mat inputBlob = dnn::blobFromImage(img);
//opencv
Net net = readNetFromONNX(modelpath);
clock_t start{ clock() }, end;
net.setInput(inputBlob);
Mat prob = net.forward();
end = clock();
std::cout << "opencv:"<<end - start<<"ms" << std::endl;
float* pData = (float*)prob.data;
softmax(prob, prob);
Point maxLoc;
double maxValue = 0;
minMaxLoc(prob, 0, &maxValue, 0, &maxLoc);
int labelIndex = maxLoc.x;
double probability = maxValue;
string cla;
switch (labelIndex)
{
case 0:
cla = "断胶";
break;
case 1:
cla = "多胶";
break;
case 2:
cla = "少胶";
break;
case 3:
cla = "正常";
break;
}
cout << cla << ":" << probability;
}
catch (exception ex) {
}
}
结果:和onnxruntime的一样
例3:dnn部署UNet二分类模型(多图并行推理)
// 加载模型
int UNetInit(string onnx)
{
net = cv::dnn::readNetFromONNX(onnxPath);
// 设置计算后台和计算设备(默认为CPU)
// CPU
//net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);
//net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);
// CUDA
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
return 0;
} // 预处理
void preProcess(vector<Mat>& small_images) {
for (size_t i = 0; i < small_images.size(); i++)
{
Mat image_small = small_images[i];
copyMakeBorder(image_small, image_small, 0, baseSize - image_small.rows, 0, baseSize - image_small.cols, BORDER_CONSTANT, Scalar(0));
image_small.convertTo(image_small, CV_32FC1, 1.0 / 255);
subtract(image_small, meanVal, image_small);
divide(image_small, stdVal, image_small);
}
}
// 后处理 并行推理
void Segmentation(const cv::Mat& score, vector<Mat>& masks) {
// score.size = batch x 2 x 480 x 480
int bths = score.size[0];
int chns = score.size[1];
int rows = score.size[2];
int cols = score.size[3]; for (int batch = 0; batch < bths; batch++) {
Mat mask = Mat::zeros(rows, cols, CV_8UC1);
for (int row = 0; row < rows; row++)
{
const float* bg_score = score.ptr<float>(batch, 0, row);
const float* fg_score = score.ptr<float>(batch, 1, row);
for (int col = 0; col < cols; col++)
{
if ((fg_score[col] > bg_score[col])&& (exp(fg_score[col]) / (exp(fg_score[col]) + exp(bg_score[col])) > 0.95))
mask.at<uchar>(row, col) = 255;
}
}
masks.push_back(mask);
}
}
int main(){
...
UNetInit(onnxPath);//加载模型
vector<Mat> small_images,small_masks;
... //读图
preProcess(small_images);//预处理
Mat blob = dnn::blobFromImages(small_images);
net.setInput(blob);
Mat preds = net.forward();//推理
Segmentation(preds, small_masks);
...
}
参考文献
1.【语义分割】轻量级人像分割PP-HumanSeg NCNN C++ windows部署
2. OpenCV4.5.x DNN + YOLOv5 C++推理
【深度学习】c++部署onnx模型(Yolov5、PP-HumanSeg、GoogLeNet、UNet)的更多相关文章
- zz深度学习中的注意力模型
中间表示: C -> C1.C2.C3 i:target -> IT j: source -> JS sim(Query, Key) -> Value Key:h_j,类似某种 ...
- 时间序列深度学习:状态 LSTM 模型预测太阳黑子
目录 时间序列深度学习:状态 LSTM 模型预测太阳黑子 教程概览 商业应用 长短期记忆(LSTM)模型 太阳黑子数据集 构建 LSTM 模型预测太阳黑子 1 若干相关包 2 数据 3 探索性数据分析 ...
- 深度学习中的序列模型演变及学习笔记(含RNN/LSTM/GRU/Seq2Seq/Attention机制)
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![认真看图][认真看图] [补充说明]深度学习中的序列模型已经广泛应用于自然语言处理(例如机器翻 ...
- 深度学习教程 | Seq2Seq序列模型和注意力机制
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/35 本文地址:http://www.showmeai.tech/article-det ...
- 由微软打造的深度学习开放联盟ONNX成立
导读 如今的微软已经一跃成为全球市值最高的高科技公司之一.2018年11月底,微软公司市值曾两次超越了苹果,成为全球市值最高的公司,之后也一直处于与苹果胶着的状态.市场惊叹微软是一家有能力改造自己并取 ...
- 时间序列深度学习:状态 LSTM 模型预測太阳黑子(一)
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/kMD8d5R/article/details/82111558 作者:徐瑞龙,量化分析师,R语言中文 ...
- 深度学习中的Normalization模型
Batch Normalization(简称 BN)自从提出之后,因为效果特别好,很快被作为深度学习的标准工具应用在了各种场合.BN 大法虽然好,但是也存在一些局限和问题,诸如当 BatchSize ...
- [优化]深度学习中的 Normalization 模型
来源:https://www.chainnews.com/articles/504060702149.htm 机器之心专栏 作者:张俊林 Batch Normalization (简称 BN)自从提出 ...
- [深度学习] 使用Darknet YOLO 模型破解中文验证码点击识别
内容 背景 准备 实践 结果 总结 引用 背景 老规矩,先上代码吧 代码所在: https://github.com/BruceDone/darknet_demo 最近在做深度学习相关的项目的时候,了 ...
- 构建基于深度学习神经网络协同过滤模型(NCF)的视频推荐系统(Python3.10/Tensorflow2.11)
毋庸讳言,和传统架构(BS开发/CS开发)相比,人工智能技术确实有一定的基础门槛,它注定不是大众化,普适化的东西.但也不能否认,人工智能技术也具备像传统架构一样"套路化"的流程,也 ...
随机推荐
- 调用App Store Connect Api
对iOS的证书.描述文件.账号.设备等管理,之前都去苹果开发者中心操作,官网上操作也比较繁杂,想搞一些自动化之类的,更是麻烦,有时候官网都打不开-- 其实苹果还提供里一套API接口,创建证书.创建账号 ...
- 利用navicat实现excel转json
1.需要工具,Navicat Premium,网上有破解及安装教程 2.新建sqlite连接,选择新建sqlite3,如下图 3.接着点确定,如图 4. 5.
- 【笔记】Linux基础指令
Linux基础指令 cd 跳转文件夹 cd 到根目录 cd usr 到根目录下的usr目录 cd .. 到上一级目录 cd ~ 到home目录 cd - 到上次访问的目录 sh 执行sh命令 ls 查 ...
- 力扣38(java)-外观数列(中等)
题目: 给定一个正整数 n ,输出外观数列的第 n 项. 「外观数列」是一个整数序列,从数字 1 开始,序列中的每一项都是对前一项的描述. 你可以将其视作是由递归公式定义的数字字符串序列: count ...
- AHPA:开启 Kubernetes 弹性预测之门
简介:阿里巴巴云原生团队和阿里达摩院决策智能时序团队合作开发 AHPA 弹性预测产品,该产品主要出发点是基于检测到的周期做"定时规划",通过规划实现提前扩容的目的,在保证业务稳定 ...
- 最佳实践丨构建云上私有池(虚拟IDC)的5种方案详解
简介:云上私有池系列终篇终于来了,本文将重点介绍构建云上的私有池(虚拟IDC)的多种方案和各自的优缺点,并给出相关的性价比优化建议. 本文作者:阿里云技术专家李雨前 摘要 围绕私有池(虚拟IDC)的 ...
- RocketMQ 千锤百炼--哈啰在分布式消息治理和微服务治理中的实践
简介: 随着公司业务的不断发展,流量也在不断增长.我们发现生产中的一些重大事故,往往是被突发的流量冲跨的,对流量的治理和防护,保障系统高可用就尤为重要. 作者|梁勇 背景 哈啰已进化为包括两轮出 ...
- 复杂推理模型从服务器移植到Web浏览器的理论和实战
简介: 随着机器学习的应用面越来越广,能在浏览器中跑模型推理的Javascript框架引擎也越来越多了.在项目中,前端同学可能会找到一些跑在服务端的python算法模型,很想将其直接集成到自己的代码 ...
- WPF 编写一个测试 WM_TOUCH 触摸消息延迟的应用
我听说在 Win10 到 Win11 的系统版本左右,微软加上了一大波触摸性能优化,准确来说是 HID 性能优化.我想测试一下在这些系统下,采用从 Windows 消息接收到 WM_TOUCH 触摸消 ...
- 在FPGA中何时用组合逻辑或时序逻辑
在设计FPGA时,大多数采用Verilog HDL或者VHDL语言进行设计(本文重点以verilog来做介绍).设计的电路都是利用FPGA内部的LUT和触发器等效出来的电路. 数字逻辑电路分为组合逻辑 ...