Binance 如何使用 Quickwit 构建 100PB 日志服务(Quickwit 博客)

三年前,我们开源了 Quickwit,一个面向大规模数据集的分布式搜索引擎。我们的目标很宏大:创建一种全新的全文搜索引擎,其成本效率比 Elasticsearch 高十倍,配置和管理显著更简单,并且能够扩展到 PB 级别的数据。
虽然我们知道 Quickwit 的潜力,但我们通常测试的数据量不超过 100TB,索引吞吐量不超过 1GB/s。我们缺乏现实世界中的数据集和计算资源来测试 Quickwit 在多 PB 规模下的表现。
直到六个月前,情况发生了变化。币安(全球领先的加密货币交易所)的两位工程师发现了 Quickwit 并开始尝试使用它。仅仅几个月内,他们实现了我们梦寐以求的目标:成功地将多个 PB 级别的 Elasticsearch 集群迁移到 Quickwit,取得了显著的成绩,包括:
- 将索引扩展到了每天 1.6 PB。
- 运行了一个处理100 PB 日志的搜索集群。
- 每年节省数百万美元,通过降低 80% 的计算成本和减少 20 倍的存储成本(对于相同的保留期)。
在这篇博客文章中,我将与大家分享币安是如何构建 PB 级别的日志服务以及如何克服将 Quickwit 扩展到多 PB 规模时遇到的挑战。
币安面临的挑战
作为全球领先的加密货币交易所,币安处理着巨大的交易量,每笔交易都会产生对安全、合规性和运营洞察至关重要的日志。这导致了大约每秒处理 2100万条日志记录,相当于每秒 18.5GB,或每天 1.6PB 的日志量。
为了管理如此庞大的数据量,币安之前依赖于 20 个 Elasticsearch 集群。大约 600 个 Vector Pod 从不同的 Kafka 主题拉取日志并进行处理,然后再推送到 Elasticsearch 中。
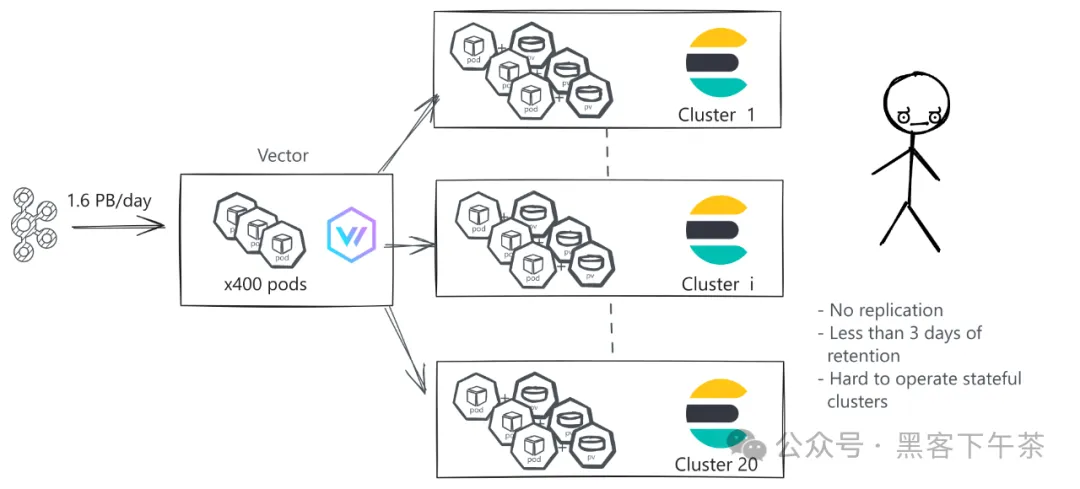
然而,这种设置在几个关键领域未能满足币安的需求:
- 运维复杂性:管理众多 Elasticsearch 集群变得越来越具有挑战性和耗时。
- 有限的保留期限:币安仅保留大部分日志几天的时间。他们的目标是将此期限延长至数月,这意味着需要存储和管理
100PB的日志,这对于他们的 Elasticsearch 设置来说成本高昂且复杂。 - 有限的可靠性:为了限制基础设施成本,高吞吐量的 Elasticsearch 集群被配置为没有复制,这损害了持久性和可用性。
团队知道他们需要彻底改变才能满足日益增长的日志管理、保留和分析需求。
为什么 Quickwit 几乎是完美的选择
当币安的工程师们发现 Quickwit 时,他们很快意识到它相比现有的设置提供了几个关键优势:
- 原生 Kafka 集成:它允许直接从 Kafka 中摄入日志,具备恰好一次(exactly-once)语义,提供了巨大的运维好处。具体而言,您可以拆除集群,在一分钟内重新创建,不会丢失任何数据,准备好以每天
1.6PB的速度摄入或搜索 PB 级别的数据,并且可以根据临时峰值上下调整规模。 - 对象存储作为主要存储:所有索引的数据都保留在对象存储上,消除了在集群侧配置和管理存储的需求。
- 更好的数据压缩:Quickwit 通常比 Elasticsearch 实现好两倍的数据压缩,进一步减少了索引的存储占用。
然而,没有任何用户将 Quickwit 扩展到多 PB 级别,任何工程师都知道将系统扩展 10 倍或 100 倍可能会暴露出意想不到的问题。但这并没有阻止他们,他们准备迎接这一挑战!

每天 1.6PB 的索引扩展
借助 Kafka 数据源,币安迅速扩大了索引规模。在 Quickwit 概念验证的一个月后,他们已经达到了每秒几 GB 的索引速度。
这种快速进展很大程度上归功于 Quickwit 与 Kafka 的工作方式:Quickwit 利用 Kafka 的消费者组将工作负载分布在多个Pod 之间。每个 Pod 索引 Kafka 分区的一个子集,并使用最新的偏移量更新元存储,确保恰好一次(exactly-once)语义。这种设置使得 Quickwit 的索引器无状态:您可以拆除整个集群并重新启动,索引器会像什么都没有发生一样从中断的地方继续运行。
然而,币安的规模揭示了两个主要问题:
- 集群稳定性问题:几个月前,Quickwit 的 gossip 协议(称为 Chitchat)在数百个 Pod 的情况下遇到了困难:一些索引器会离开集群然后重新加入,导致索引吞吐量不稳定。
- 不均衡的工作负载分配:币安为其日志使用了多个 Quickwit 索引,索引吞吐量各不相同。有些索引的吞吐量高达每秒几 GB,而其他索引只有每秒几 MB。Quickwit 的放置算法无法均匀分布工作负载。这是一个已知的问题 issue,我们将在今年晚些时候解决这个问题。
为了解决这些限制,币安为每个高吞吐量的 topic 部署了单独的索引集群,并为较小的主题保留了一个集群。由于索引器无状态,隔离每个高吞吐量集群并未带来运维负担。此外,所有 Vector Pod 都被移除,因为币安直接在 Quickwit 中使用了 Vector 转换。

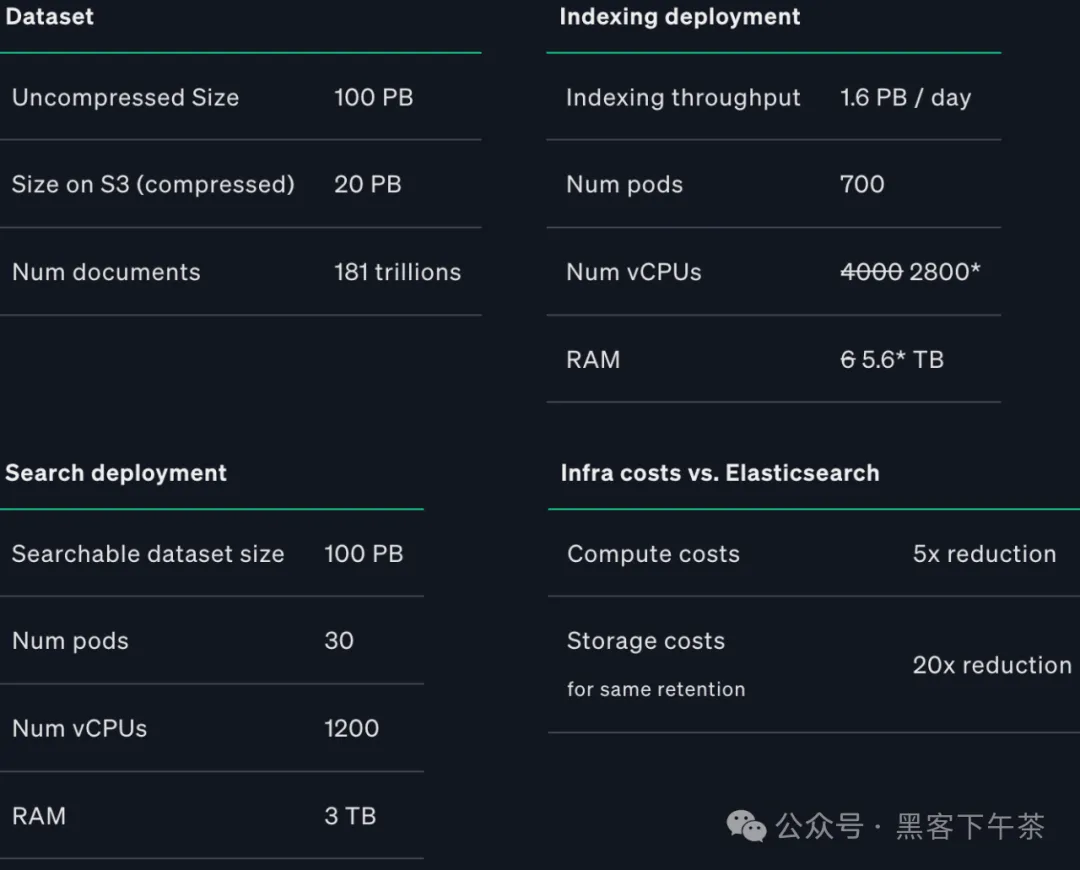
经过几个月的迁移和优化后,币安最终实现了 1.6 PB 的索引吞吐量,使用了 10 个 Quickwit 索引集群,共 700 个 Pod 请求大约 2800 个 vCPU 和 6 TB 内存,平均每个 vCPU 达到 6.6 MB/s。在一个特定的高吞吐量 Kafka topic 上,这个数字上升到了每个 vCPU 11 MB/s。
接下来的挑战是:扩展搜索!
用于 100PB 日志的单一搜索集群
现在 Quickwit 已经能够高效地每天索引 1.6PB 的数据,挑战转向了搜索 PB 级别的日志。如果有 10 个集群,币安通常需要为每个集群部署搜索 Pod,这削弱了 Quickwit 的一个优势:汇聚搜索资源以访问所有索引共享的对象存储。
为了避免这个陷阱,币安的工程师们设计了一个巧妙的解决方案:他们通过将每个索引集群元存储中的所有元数据复制到一个PostgreSQL 数据库中,创建了一个统一的元存储。这个统一的元存储使得部署一个独特的集中式搜索集群成为可能,该集群能够搜索所有索引!

目前,币安管理着一个适度规模的搜索集群,包含 30 个搜索 Pod,每个 Pod 请求 40 个 vCPU 和 100GB 内存。举个例子,您只需要 5 个搜索器(8 个 vCPU,6GB 内存请求)就能在 400TB 的日志中找到所需的信息。币安运行这类查询针对的是PB级别的数据,同时还运行聚合查询,因此需要更高的资源请求。
总结
总体而言,币安迁移到 Quickwit 是一次巨大的成功,并带来了几个实质性的益处:
- 与 Elasticsearch 相比,计算资源减少了
80%。 - 对于相同的保留期限,存储成本降低了
20倍。 - 在基础设施成本和维护操作方面都是经济可行的大规模日志管理解决方案。
- 配置微调最少,一旦确定了正确的 Pod 数量和资源,就能够高效工作。
- 根据日志类型,将日志保留期限增加到一个月或几个月,提高了内部故障排查的能力。
总之,币安从 Elasticsearch 迁移到 Quickwit 是币安和 Quickwit 工程师之间激动人心的 6 个月合作经历,我们为此感到非常自豪。我们已经计划了数据压缩、多集群支持以及更好地与 Kafka 数据源分配工作负载等方面的改进。
更多
Binance 如何使用 Quickwit 构建 100PB 日志服务(Quickwit 博客)的更多相关文章
- 全栈前端入门必看 koa2+mysql+vue+vant 构建简单版移动端博客
koa2+mysql+vue+vant 构建简单版移动端博客 具体内容展示 开始正文 github地址 <br/> 觉得对你有帮助的话,可以star一下^_^必须安装:<br/> ...
- centos安装服务参考博客,亲测可用
centos 安装nginx参考 日志log报错 nginx -c /etc/nginx/nginx.conf https://blog.csdn.net/weixin_41004350/articl ...
- 分享 koa + mysql 的开发流程,构建 node server端,一次搭建个人博客
前言 由于一直在用 vue 写业务,为了熟悉下 react 开发模式,所以选择了 react.数据库一开始用的是 mongodb,后来换成 mysql 了,一套下来感觉 mysql 也挺好上手的.re ...
- 国内博客(blog)搬家工具(服务)大全
如今网络上的博客搬家 服务,博客搬家工具 越来越多,博客联盟 大概收集了下,希望对那些想搬家的博客有所帮助. 一.和讯博客的“搬家公司”提供博客搬家 服务 搬家服务地址:点这里 目标对象:新浪博客 . ...
- github page+jekyll构建博客的解决方案
想在github page上构建自己的博客,前几个星期就动手搞了起来,但由于自己对于前端这些东西不是很熟,所以断断续续的,直到今天才把所有东西都搞懂,而且构建出自己的github博客了. 最终效果,大 ...
- 消费阿里云日志服务SLS
此文档只关心消费接入,不关心日志接入,只关心消费如何接入,可直接跳转到[sdk消费接入] SLS简介 日志服务: 日志服务(Log Service,简称 LOG)是针对日志类数据的一站式服务,在阿里巴 ...
- 日志服务Python消费组实战(三):实时跨域监测多日志库数据
解决问题 使用日志服务进行数据处理与传递的过程中,你是否遇到如下监测场景不能很好的解决: 特定数据上传到日志服务中需要检查数据内的异常情况,而没有现成监控工具? 需要检索数据里面的关键字,但数据没有建 ...
- ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台(elk5.2+filebeat2.11)
ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台 参考:http://www.tuicool.com/articles/R77fieA 我在做ELK日志平台开始之初选择为 ...
- Spring Cloud与微服务构建:微服务简介
Spring Cloud与微服务构建:微服务简介 单体架构及其不足 1.单体架构简介 在软件设计中,经常提及和使用经典的3曾模型,即表示层.业务逻辑层和数据访问层. 表示层:用于直接和用户交互,也成为 ...
- logserver 日志服务项目发布
logserver是使用logback.light-4j.commons-exec等构建的简单日志服务,参考项目logbackserver和light4j,支持跟踪日志.分页查看.搜索定位.下载文件等 ...
随机推荐
- scrapy爬取知名问答网站
scrapy爬取知名问答网站 分析及数据表设计 itemloader方式提取question spider爬虫逻辑的实现以及answer的提取 保存数据到mysql中
- 将强化学习重新引入 RLHF
我们很高兴在 TRL 中介绍 RLOO (REINFORCE Leave One-Out) 训练器.作为一种替代 PPO 的方法,RLOO 是一种新的在线 RLHF 训练算法,旨在使其更易于访问和实施 ...
- HarmonyOS SDK助力鸿蒙原生应用“易感知、易理解、易操作”
6月21-23日,华为开发者大会(HDC 2024)盛大开幕.6月23日上午,<HarmonyOS开放能力,使能应用原生易用体验>分论坛成功举办,大会邀请了多位华为技术专家深度解读如何通过 ...
- Python 引用不确定的函数
在Python中,引用不确定的函数通常意味着我们可能在运行时才知道要调用哪个函数,或者我们可能想根据某些条件动态地选择不同的函数来执行.这种灵活性在处理多种不同逻辑或根据不同输入参数执行不同操作的场景 ...
- 【Redis】BigKey问题
面试题 海量数据里查询某一固定前缀的key 生产上如何限制 keys * / flushdb / flushall 等危险命令以防止误删误用? MEMORY USAGE 命令用过吗? BigKey问题 ...
- @ConfigurationProperties 还能这样用
在编写项目代码时,我们要求更灵活的配置,更好的模块化整合.在 Spring Boot 项目中,为满足以上要求,我们将大量的参数配置在 application.properties 或 applicat ...
- C# NPOI 读取Excel数据,附案例源码
项目结构 注意:需要引入NPOI类库 C#代码 Form1.cs using NPOI.HSSF.UserModel; using NPOI.SS.UserModel; using System; u ...
- Microsoft Compatibility telemetry占cpu资源高
1.在Windows10系统卡的时候,打开任务管理器,发现Microsoft Compatibility telemetry占用了大量的系统资源,特别是CPU占用率非常高. 位置:控制面板->管 ...
- jsbarcode 生成条形码,并将生成的条码保存至本地,附源码
导读 以前生成条码都是外网网站上生成,因生产环境在内网中,上不了外网,只能在项目中生成相应规则,故将此方法整理下来. html <!DOCTYPE html> <html> & ...
- mac 安装jdk1.8 附详细教程
详细步骤 下载 链接: https://pan.baidu.com/s/1xQr6_9_7lFNtSes7HsKveA 密码: edme 安装包 一直按继续 配置系统环境变量 上一步骤,实标上,我们只 ...