【深度学习】批量归一化 BatchNormalization
一、背景
- 每层的参数需不断适应新的输入数据分布,降低学习速度,增大学习的难度(层数多)
- 输入可能趋向于变大或者变小(分布变广),导致激活值落入饱和区,阻碍学习
二、Batch Normalization
注:Batch Normalization 最开始的动机是缓解内部协变量偏移,但后来的研究者发现其主要优点是归一化会导致更平滑的优化地形。

if self.training:
mean = input.mean([0, 2, 3]) # 计算当前 batch 的均值
var = input.var([0, 2, 3], unbiased=False) # 计算当前 batch 的方差
n = input.numel() / input.size(1)
with torch.no_grad():
# 使用移动平均更新对数据集均值的估算
self.running_mean = exponential_average_factor * mean\
+ (1 - exponential_average_factor) * self.running_mean
# 使用移动平均更新对数据集方差的估算
self.running_var = exponential_average_factor * var * n / (n - 1)\
+ (1 - exponential_average_factor) * self.running_var
else:
mean = self.running_mean
var = self.running_var # 使用均值和方差将每个元素标准化
input = (input - mean[None, :, None, None]) / (torch.sqrt(var[None, :, None, None] + self.eps))
# 对标准化的结果进行缩放(可选)
if self.affine:
input = input * self.weight[None, :, None, None] + self.bias[None, :, None, None]
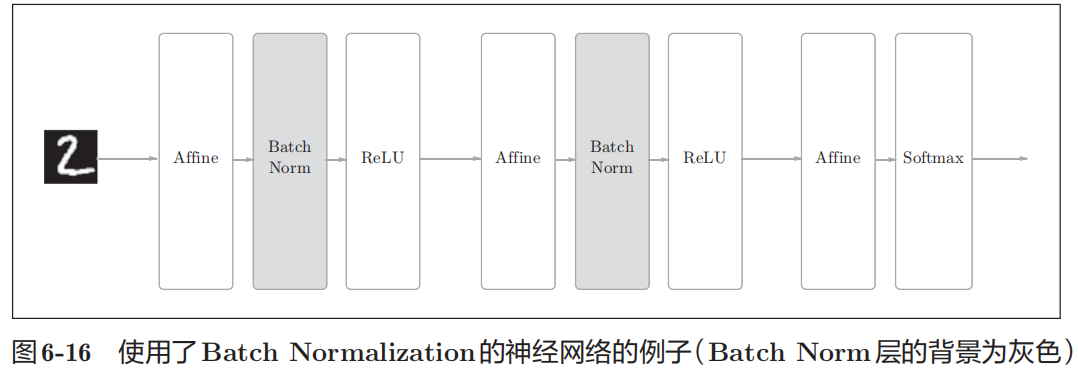
图解BatchNorm

m = nn.BatchNorm1d(100) # With Learnable Parameters
m = nn.BatchNorm1d(100, affine=False) # Without Learnable Parameters
input = torch.randn(20, 100)
output = m(input)
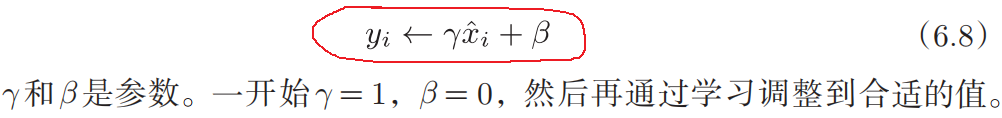
- 使用Batch Norm后,可以使学习快速进行,(学习得更快了)。(可以增大学习率)。
- 不那么依赖参数初始值。
- 抑制过拟合(降低Dropout等的必要性)
效果展示
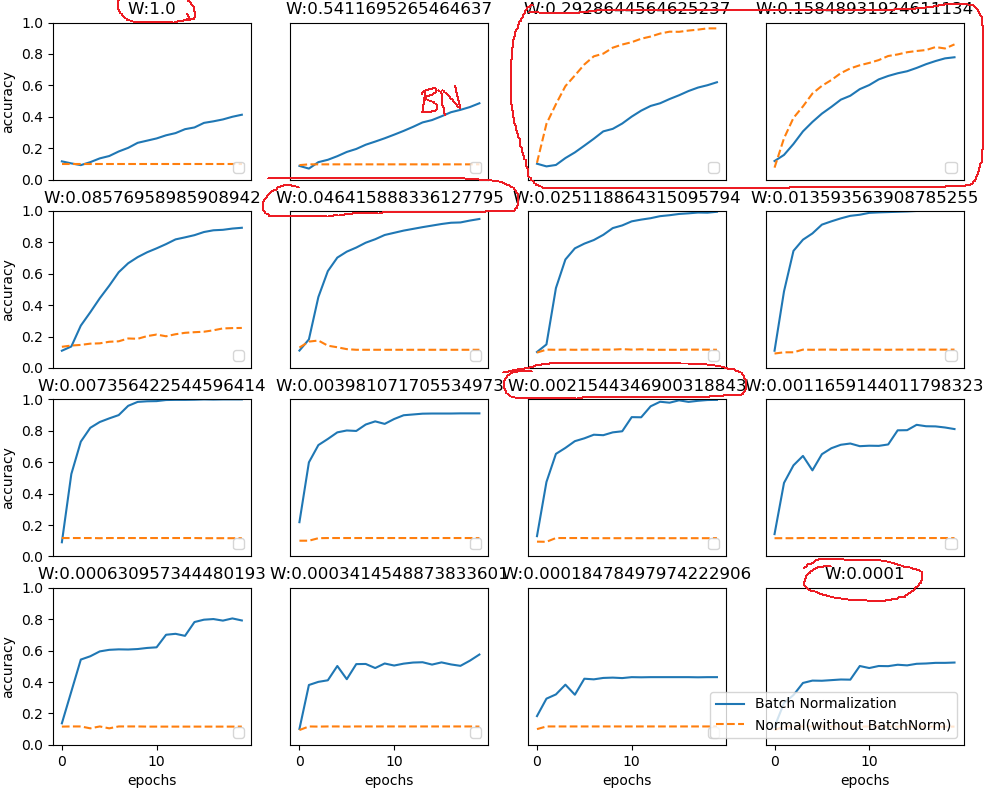
解释: 由于在选取批次时具有随机性,因此使得神经网络不会“过拟合”到某个特定样本,从而提高网络的泛化能力。
参考内容
1、深度学习入门
2、李宏毅机器学习
【深度学习】批量归一化 BatchNormalization的更多相关文章
- 深度学习面试题21:批量归一化(Batch Normalization,BN)
目录 BN的由来 BN的作用 BN的操作阶段 BN的操作流程 BN可以防止梯度消失吗 为什么归一化后还要放缩和平移 BN在GoogLeNet中的应用 参考资料 BN的由来 BN是由Google于201 ...
- GIS地理处理脚本案例教程——批量栅格分割-批量栅格裁剪-批量栅格掩膜-深度学习样本批量提取
GIS地理处理脚本案例教程--批量栅格分割-批量栅格裁剪-批量栅格掩膜-深度学习样本批量提取 商务合作,科技咨询,版权转让:向日葵,135-4855_4328,xiexiaokui#qq.com 关键 ...
- 如何理解归一化(Normalization)对于神经网络(深度学习)的帮助?
如何理解归一化(Normalization)对于神经网络(深度学习)的帮助? 作者:知乎用户链接:https://www.zhihu.com/question/326034346/answer/730 ...
- Pytorch1.0深度学习:损失函数、优化器、常见激活函数、批归一化详解
不用相当的独立功夫,不论在哪个严重的问题上都不能找出真理:谁怕用功夫,谁就无法找到真理. —— 列宁 本文主要介绍损失函数.优化器.反向传播.链式求导法则.激活函数.批归一化. 1 经典损失函数 1. ...
- 深度学习归一化:BN、GN与FRN
在深度学习中,使用归一化层成为了很多网络的标配.最近,研究了不同的归一化层,如BN,GN和FRN.接下来,介绍一下这三种归一化算法. BN层 BN层是由谷歌提出的,其相关论文为<Batch No ...
- 【深度学习】线性回归(Linear Regression)——原理、均方损失、小批量随机梯度下降
1. 线性回归 回归(regression)问题指一类为一个或多个自变量与因变量之间关系建模的方法,通常用来表示输入和输出之间的关系. 机器学习领域中多数问题都与预测相关,当我们想预测一个数值时,就会 ...
- 深度学习中 --- 解决过拟合问题(dropout, batchnormalization)
过拟合,在Tom M.Mitchell的<Machine Learning>中是如何定义的:给定一个假设空间H,一个假设h属于H,如果存在其他的假设h’属于H,使得在训练样例上h的错误率比 ...
- L18 批量归一化和残差网络
批量归一化(BatchNormalization) 对输入的标准化(浅层模型) 处理后的任意一个特征在数据集中所有样本上的均值为0.标准差为1. 标准化处理输入数据使各个特征的分布相近 批量归一化(深 ...
- 深度学习系列 Part(3)
这是<GPU学习深度学习>系列文章的第三篇,主要是接着上一讲提到的如何自己构建深度神经网络框架中的功能模块,进一步详细介绍 Tensorflow 中 Keras 工具包提供的几种深度神经网 ...
- [DeeplearningAI笔记]神经网络与深度学习人工智能行业大师访谈
觉得有用的话,欢迎一起讨论相互学习~Follow Me 吴恩达采访Geoffrey Hinton NG:前几十年,你就已经发明了这么多神经网络和深度学习相关的概念,我其实很好奇,在这么多你发明的东西中 ...
随机推荐
- 整个小东西,在IDEA中自动生成PO、DAO、Mapper
作者:小傅哥 博客:https://bugstack.cn 源码:https://github.com/fuzhengwei/CodeGuide/wiki 沉淀.分享.成长,让自己和他人都能有所收获! ...
- svg图片引入方式
第一种直接引入: <svg t="1684280784467" class="icon" viewBox="0 0 1024 1024" ...
- centos7.9重启网卡提示Failed to start LSB: Bring up/down networking.
前几天给一台机器状态centos7.9系统,设备有2个网口,今天重启网卡一直失败, 查看network状态,怀疑是eth0网卡有问题 查看eth0的网卡配置,发现是eth0网卡的BOOTPROTO=d ...
- PicGo + Gitee 实现 Markdown 图床
最近再研究图床,注册的阿里云域名备案还在审批,所以七牛云图床暂时没用,所以试下用PicGo+ Gitee PicGo - 基于 electron-vue 开发的图床工具 PicGo目前支持了微博图床, ...
- 使用DoraCloud构建远程办公桌面云
公司总部在上海.员工分布在各地.部分员工需要远程办公.为了实现远程办公,有几种备选方案. 方案1.在员工的PC上安装向日葵.ToDesk之类的远程工具. 方案2.公司总部提供VPN,员工通过VPN拨号 ...
- 教你用JavaScript实现鼠标特效
案例介绍 欢迎来的我的小院,我是霍大侠,恭喜你今天又要进步一点点了!我们来用JavaScript编程实战案例,做一个鼠标爱心特效.鼠标在页面移动时会出现彩色爱心特效.通过实战我们将学会createEl ...
- Redis有哪些潜在的慢操作?
Redis作为内存数据库,访问速度快是最大的特点,那么,什么情况下,Redis也会变慢呢? Redis底层数据结构 Redis有5种基本数据类型:String,List,Hash,Set,ZSet 有 ...
- AES算法:数据传输的安全保障
在当今数字化时代,数据安全成为了一个非常重要的问题.随着互联网的普及和信息技术的发展,我们需要一种可靠的加密算法来保护我们的敏感数据.Advanced Encryption Standard(AES) ...
- NOI 2021 补全记录
来补题了昂. D1T1 轻重边 对于原树进行重链剖分,使用一颗线段树维护每一条重边是否时"重边",然后对于轻边,在父亲出维护最后一次通过 \(1\) 操作清空"重边&qu ...
- 利用LiveReload插件实现vscode和谷歌浏览器实时刷新
说明 最近在研究CSS希望可以提升一个层次.在写DEMO练习的时候老是需要去谷歌浏览器手动刷新页面才能看到更改后的效果次数多了 我也受不了,这不我又请来了个帮手: LiveReload,名如其人,这家 ...