coco2017 Dataset EDA
Github仓库:gy-7/coco_EDA (github.com)
对coco数据集的分析,近期忙着写论文,空余时间很少能写博文了。
EDA的代码放在结尾了,Github仓库里也有。仓库里还有其他的一些EDA分析,不定时更新。
训练集所有类别的数量分布情况:
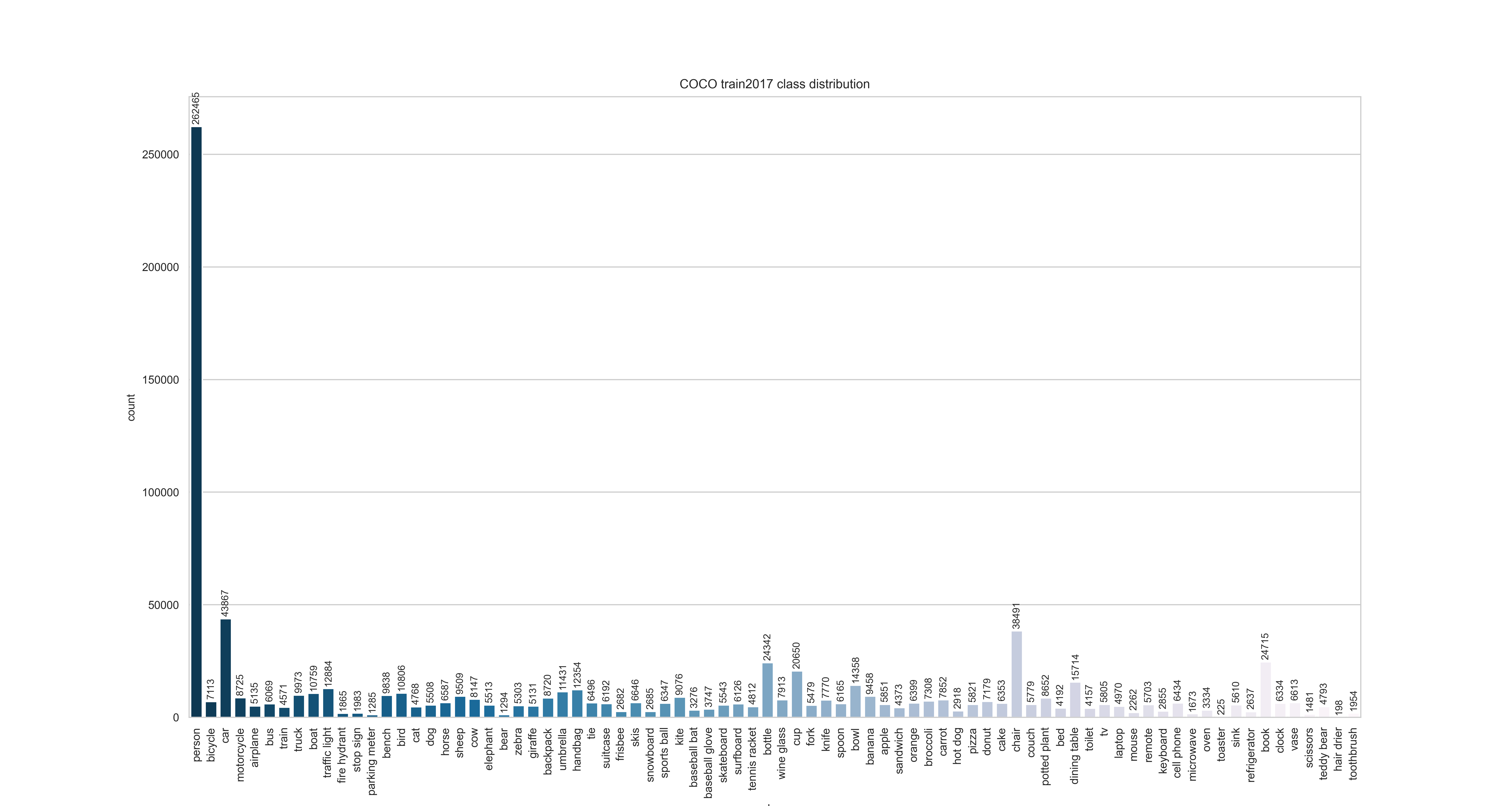
训练集所有类别的尺寸分布情况:

验证集所有类别的数量分布情况:
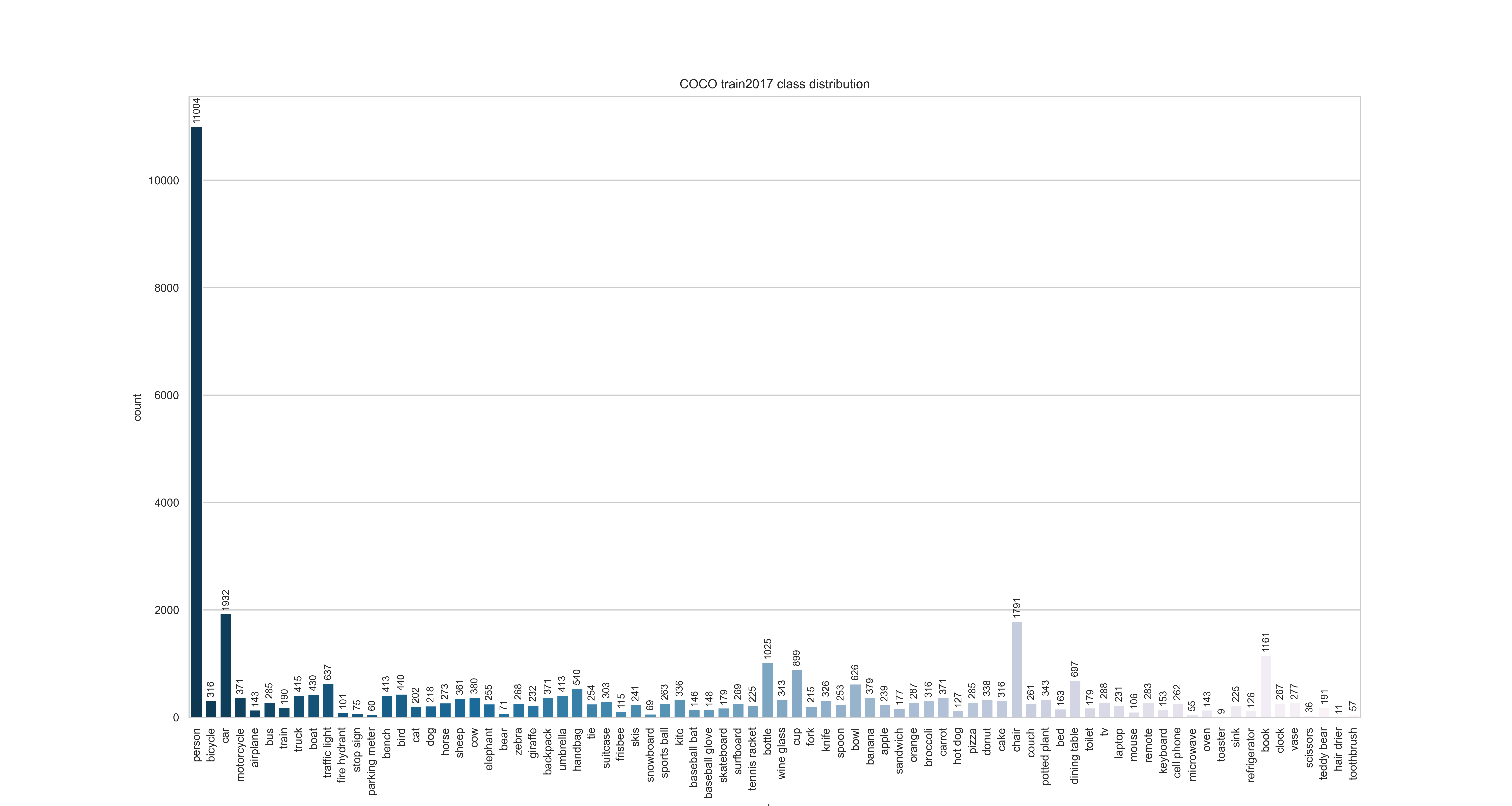
验证集所有类别的尺寸分布情况:

EDA代码:
import os
import seaborn as sns
import pycocotools.coco
import matplotlib.pyplot as plt
root_dir = os.getcwd()
train_ann_fp = os.path.join(root_dir, 'annotations', 'instances_train2017.json')
val_ann_fp = os.path.join(root_dir, 'annotations', 'instances_val2017.json')
class COCO_EDA:
def __init__(self, json_file, type='train'):
self.COCO_SMALL_SCALE = 32
self.COCO_MEDIUM_SCALE = 96
self.json_file = json_file
coco = pycocotools.coco.COCO(json_file)
self.type = type
self.imgs = coco.dataset['images']
self.anns = coco.dataset['annotations']
self.cats = coco.dataset['categories']
self.img_ids = coco.getImgIds()
self.ann_ids = coco.getAnnIds()
self.cat_ids = coco.getCatIds()
self.cat2imgs = coco.catToImgs
self.img2anns = coco.imgToAnns
self.imgs_num = len(self.imgs)
self.objs_num = len(self.anns)
# data to be collected
self.small_objs_num = 0
self.medium_objss_num = 0
self.large_objss_num = 0
self.small_objs = []
self.medium_objs = []
self.large_objs = []
self.cat2objs = {}
self.small_cat2objs = {} # small objects classes distribution
self.medium_cat2objs = {} # medium objects classes distribution
self.large_cat2objs = {} # large objects classes distribution
self.cat2objs_num = {} # objects classes distribution
self.small_cat2objs_num = {} # small objects classes distribution
self.medium_cat2objs_num = {} # medium objects classes distribution
self.large_cat2objs_num = {} # large objects classes distribution
# plot use data
self.catid2name = {} # 用于绘图中显示类别名字
self.cats_plot = [] # coco 所有尺寸目标的类别分布
self.small_cats_plot = [] # 小目标中每个类的分布情况
self.medium_cats_plot = [] # 中目标中每个类的分布情况
self.large_cats_plot = [] # 大目标中每个类的分布情况
# 每个类的小,中,大目标的数量
self.size_distribution = {}
def collect_data(coco):
# collect small, medium, large objects
for ann in coco.anns:
if ann['area'] < coco.COCO_SMALL_SCALE ** 2:
coco.small_objs_num += 1
coco.small_objs.append(ann)
elif ann['area'] < coco.COCO_MEDIUM_SCALE ** 2:
coco.medium_objs.append(ann)
coco.medium_objss_num += 1
else:
coco.large_objs.append(ann)
coco.large_objss_num += 1
for i in coco.cat_ids:
coco.cat2objs[i] = []
coco.small_cat2objs[i] = []
coco.medium_cat2objs[i] = []
coco.large_cat2objs[i] = []
coco.cat2objs_num[i] = 0
coco.small_cat2objs_num[i] = 0
coco.medium_cat2objs_num[i] = 0
coco.large_cat2objs_num[i] = 0
coco.size_distribution[i] = []
for i in coco.cats:
coco.catid2name[i['id']] = i['name']
# collect small, medium, large class distribution
for i in coco.anns:
coco.cat2objs[i['category_id']].append(i)
coco.cat2objs_num[i['category_id']] += 1
coco.cats_plot.append(coco.catid2name[i['category_id']])
if i['area'] < coco.COCO_SMALL_SCALE ** 2:
coco.small_cat2objs[i['category_id']].append(i)
coco.small_cat2objs_num[i['category_id']] += 1
coco.small_cats_plot.append(coco.catid2name[i['category_id']])
coco.size_distribution[i['category_id']].append('s')
elif i['area'] < coco.COCO_MEDIUM_SCALE ** 2:
coco.medium_cat2objs[i['category_id']].append(i)
coco.medium_cat2objs_num[i['category_id']] += 1
coco.medium_cats_plot.append(coco.catid2name[i['category_id']])
coco.size_distribution[i['category_id']].append('m')
else:
coco.large_cat2objs[i['category_id']].append(i)
coco.large_cat2objs_num[i['category_id']] += 1
coco.large_cats_plot.append(coco.catid2name[i['category_id']])
coco.size_distribution[i['category_id']].append('l')
assert len(coco.small_objs) == coco.small_objs_num == sum(coco.small_cat2objs_num.values())
assert len(coco.medium_objs) == coco.medium_objss_num == sum(coco.medium_cat2objs_num.values())
assert len(coco.large_objs) == coco.large_objss_num == sum(coco.large_cat2objs_num.values())
assert len(coco.anns) == coco.objs_num == sum(coco.cat2objs_num.values())
def plot_coco_class_distribution(plot_data, plot_order, save_fp, plot_title, plot_y_heigh,
plot_y_heigh_residual=[1800, 100]):
# 绘制coco数据集的类别分布
sns.set_style("whitegrid")
plt.figure(figsize=(15, 8)) # 图片的宽和高,单位为inch
plt.title(plot_title, fontsize=9) # 标题
plt.xlabel('class', fontsize=8) # x轴名称
plt.ylabel('counts', fontsize=8) # y轴名称
plt.xticks(rotation=90, fontsize=8) # x轴标签竖着显示
plt.yticks(fontsize=8)
for x, y in enumerate(plot_y_heigh):
if 'train' in save_fp:
plt.text(x, y + plot_y_heigh_residual[0], '%s' % y, ha='center', fontsize=7, rotation=90)
else:
plt.text(x, y + plot_y_heigh_residual[1], '%s' % y, ha='center', fontsize=7, rotation=90)
ax = sns.countplot(x=plot_data, palette="PuBu_r", order=plot_order) # 绘制直方图,palette调色板,蓝色由浅到深渐变。
# palette样式:https://blog.csdn.net/panlb1990/article/details/103851983
plt.savefig(os.path.join(save_fp), dpi=500)
plt.show()
def plot_size_distribution(plot_data, save_fp, plot_title, plot_order=['s', 'm', 'l']):
sns.set_style("whitegrid")
plt.figure(figsize=(21, 35)) # 图片的宽和高,单位为inch
plt.subplots_adjust(left=0.1, bottom=0.1, right=0.9, top=0.9, wspace=1, hspace=1.5) # 调整子图间距
for idx, size_data in enumerate(plot_data.values()):
plt.subplot(10, 8, idx + 1)
plt.xticks(rotation=0, fontsize=18) # x轴标签竖着显示
plt.yticks(fontsize=18)
plt.xlabel('size', fontsize=20) # x轴名称
plt.ylabel('count', fontsize=20) # y轴名称
plt.title(plot_title[idx], fontsize=24) # 标题
sns.countplot(x=size_data, palette="PuBu_r", order=plot_order) # 绘制直方图,palette调色板,蓝色由浅到深渐变。
plt.savefig(save_fp, dpi=500, pad_inches=0)
plt.show()
def run_plot_coco_class_distribution(coco, save_dir):
# # 绘制coco数据集的类别分布
plot_order = [i for i in coco.catid2name.values()]
plot_heigh = [i for i in coco.cat2objs_num.values()]
save_fp = os.path.join(save_dir, f'coco_{coco.type}_class_distribution.png')
plot_coco_class_distribution(coco.cats_plot, plot_order, save_fp, 'COCO train2017 class distribution', plot_heigh,
plot_y_heigh_residual=[1800, 100])
plot_heigh = [i for i in coco.small_cat2objs_num.values()]
save_fp = os.path.join(save_dir, f'coco_{coco.type}_small_class_distribution.png')
plot_coco_class_distribution(coco.small_cats_plot, plot_order, save_fp, 'COCO train2017 small class distribution',
plot_heigh,
plot_y_heigh_residual=[900, 50])
plot_heigh = [i for i in coco.medium_cat2objs_num.values()]
save_fp = os.path.join(save_dir, f'coco_{coco.type}_medium_class_distribution.png')
plot_coco_class_distribution(coco.medium_cats_plot, plot_order, save_fp, 'COCO train2017 medium class distribution',
plot_heigh, plot_y_heigh_residual=[900, 50])
plot_heigh = [i for i in coco.large_cat2objs_num.values()]
save_fp = os.path.join(save_dir, f'coco_{coco.type}_large_class_distribution.png')
plot_coco_class_distribution(coco.large_cats_plot, plot_order, save_fp, 'COCO train2017 large class distribution',
plot_heigh,
plot_y_heigh_residual=[900, 50])
def run_plot_coco_size_distribution(coco, save_dir):
# 绘制coco数据集各类别的尺寸分布
plot_order = [i for i in coco.catid2name.values()]
save_fp = os.path.join(save_dir, f'coco_{coco.type}_size_distribution.png')
plot_size_distribution(coco.size_distribution, save_fp, plot_order)
if __name__ == '__main__':
print("analyze coco train dataset...")
print("-" * 50)
coco_train = COCO_EDA(train_ann_fp, type='train')
collect_data(coco_train)
print("coco train images num:", coco_train.imgs_num)
print("coco train objects num:", coco_train.objs_num)
print("coco small objects num:", coco_train.small_objs_num)
print("coco medium objects num:", coco_train.medium_objss_num)
print("coco large objects num:", coco_train.large_objss_num)
print("coco small objects percent:", coco_train.small_objs_num / coco_train.objs_num)
print("coco medium objects percent:", coco_train.medium_objss_num / coco_train.objs_num)
print("coco large objects percent:", coco_train.large_objss_num / coco_train.objs_num)
run_plot_coco_class_distribution(coco_train, ".\\EDA")
run_plot_coco_size_distribution(coco_train, ".\\EDA")
print("-" * 50)
print()
print("analyze coco val dataset...")
print("-" * 50)
coco_val = COCO_EDA(val_ann_fp, type='val')
collect_data(coco_val)
print("coco val images num:", coco_val.imgs_num)
print("coco val objects num:", coco_val.objs_num)
print("coco small objects num:", coco_val.small_objs_num)
print("coco medium objects num:", coco_val.medium_objss_num)
print("coco large objects num:", coco_val.large_objss_num)
print("coco small objects percent:", coco_val.small_objs_num / coco_val.objs_num)
print("coco medium objects percent:", coco_val.medium_objss_num / coco_val.objs_num)
print("coco large objects percent:", coco_val.large_objss_num / coco_val.objs_num)
run_plot_coco_class_distribution(coco_val, ".\\EDA")
run_plot_coco_size_distribution(coco_val, ".\\EDA")
print("-" * 50)
coco2017 Dataset EDA的更多相关文章
- 斯坦福【概率与统计】课程笔记(二):从EDA开始
探索性数据分析(Exploratory Data Analysis) 本节课程先从统计分析四步骤中的第二步:EDA开始. 课程定义了若干个术语,如果学习过机器学习的同学,应该很容易类比理解: popu ...
- 【机器学习入门与实践】数据挖掘-二手车价格交易预测(含EDA探索、特征工程、特征优化、模型融合等)
[机器学习入门与实践]数据挖掘-二手车价格交易预测(含EDA探索.特征工程.特征优化.模型融合等) note:项目链接以及码源见文末 1.赛题简介 了解赛题 赛题概况 数据概况 预测指标 分析赛题 数 ...
- HTML5 数据集属性dataset
有时候在HTML元素上绑定一些额外信息,特别是JS选取操作这些元素时特别有帮助.通常我们会使用getAttribute()和setAttribute()来读和写非标题属性的值.但为此付出的代价是文档将 ...
- C#读取Excel,或者多个excel表,返回dataset
把excel 表作为一个数据源进行读取 /// <summary> /// 读取Excel单个Sheet /// </summary> /// <param name=& ...
- DataTable DataRow DataColumn DataSet
1.DataTable 数据表(内存) 2.DataRow DataTable 的行 3.DataColumn DataTable 的列 4.DataSet 内存中的缓存
- C# DataSet装换为泛型集合
1.DataSet装换为泛型集合(注意T实体的属性其字段类型与dataset字段类型一一对应) #region DataSet装换为泛型集合 /// <summary> /// 利用反射和 ...
- 读取Simulink中Dataset类型的数据
http://files.cnblogs.com/files/pursuiting/%E5%80%92%E7%AB%8B%E6%91%86%E6%8E%A7%E5%88%B6%E7%B3%BB%E7% ...
- RDD/Dataset/DataFrame互转
1.RDD -> Dataset val ds = rdd.toDS() 2.RDD -> DataFrame val df = spark.read.json(rdd) 3.Datase ...
- asp.net dataset 判断是否为空 ?
1,if(ds == null) 这是判断内存中的数据集是否为空,说明DATASET为空,行和列都不存在!! 2,if(ds.Tables.Count == 0) 这应该是在内存中存在一个DATASE ...
- C#遍历DataSet中数据的几种方法总结
//多表多行多列的情况foreach (DataTable dt in YourDataset.Tables) //遍历所有的datatable{foreach (DataRow dr in dt.R ...
随机推荐
- .net中最简单的http请求调用(比如调用chatgpt的openAI接口)
支持.Net Core(2.0及以上)/.Net Framework(4.5及以上),可以部署在Docker, Windows, Linux, Mac. http请求调用是开发中经常会用到的功能,因为 ...
- MySQL面经总结
MySQL日志 MySQL日志系统 MySQL查询 菜鸟教程SQL内连接 exist和in区别 sql语句优化 MySQL索引 覆盖索引 索引类型:主键索引,二级索引(辅助索引):唯一索引,普通索引, ...
- Rust GUI库 egui 的简单应用
目录 简介 简单示例 创建项目 界面设计 切换主题 自定义字体 自定义图标 经典布局 定义导航变量 实现导航界面 实现导航逻辑 实现主框架布局 调试运行 参考资料 简介 egui(发音为"e ...
- Navicat 15 最新破解版下载_永久激活注册码(附图文安装教程)
Navicat 15 最新破解版下载_永久激活注册码(附图文安装教程) 欢迎关注博主公众号「java大师」, 专注于分享Java领域干货文章, 关注回复「资源」, 免费领取全网最热的Java架构师学习 ...
- 推荐一款idea神级免费插件【Bito-ChatGPT】
今天推荐一款IDEA 插件神器:Bito-ChatGPT,在 IDEA 中安装直接可以使用 GPT,不需要使用魔法! 还有很重要的一点这个插件完全免费,且不限次数(目前是免费不限制次数). 环境要求: ...
- Java取当前时间的一分钟后,并格式化输出
1.Java1.8 以前 Calendar instance = Calendar.getInstance();//获取当前日期时间 instance.add(Calendar.MINUTE,1);/ ...
- AOSP编译成功后关闭终端emulator命令找不到
当我们编译好AOSP系统源码后,可以通过emulator命令打开模拟器,但是当我们关闭终端后,在次打开终端输入emulator命令,提示未找到命令: 此时我们需要重新执行下面语句 source bui ...
- AQS很难,面试不会?看我一篇文章吊打面试官
AQS很难,面试不会?看我一篇文章吊打面试官 大家好,我是小高先生.在这篇文章中,我将和大家深入探索Java并发包(JUC)中最为核心的概念之一 -- AbstractQueuedSynchroniz ...
- linux使用hostapd+dnsmasq管理多张网卡,搭建dns服务器,并发射wifi热点(支持360wifi等等)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文发布于 2015-03-03 18:37:39 ...
- Https详细分析
目录介绍 01.为何会有Https 02.解决方案分析 03.SSL是什么 04.RSA验证的隐患 05.CA证书身份验证 06.Https工作原理 07.Https代理作用 08.Https真安全吗 ...