一分钟了解 ChatGPT 语音对话
一、背景
近期 ChatGPT 推出新的语音和图像功能,可以与用户进行语音对话或基于用户上传的图像进行分析和对话,提供了一种新的、更直观的交互体验。用户可以更轻松地表达自己的需求、提出问题,并获得 ChatGPT 的回答和建议。而且,语音合成的真实度让用户感觉像是在与真实的对话伙伴进行交流,提供了更加沉浸式和互动性强的体验。
在接下来的部分,我将对 ChatGPT mobile App 语音对话功能背后的原理进行分析和探讨。通过一个实际的案例 Demo 来进行演示。我将展示一个完整的 ChatGPT 语音对话场景,以帮助您更好地了解其工作方式。
二、语音对话的原理
目前我从事是音视频产品,刚好对音频采集和播放有一定的了解。然后经常关注 OpenAI 的最新动态,每一次新的功能发布,都会上手体验。所以使用 ChatGPT mobile App 语音对话功能时,脑海中立刻浮现出下面这个调用链图。
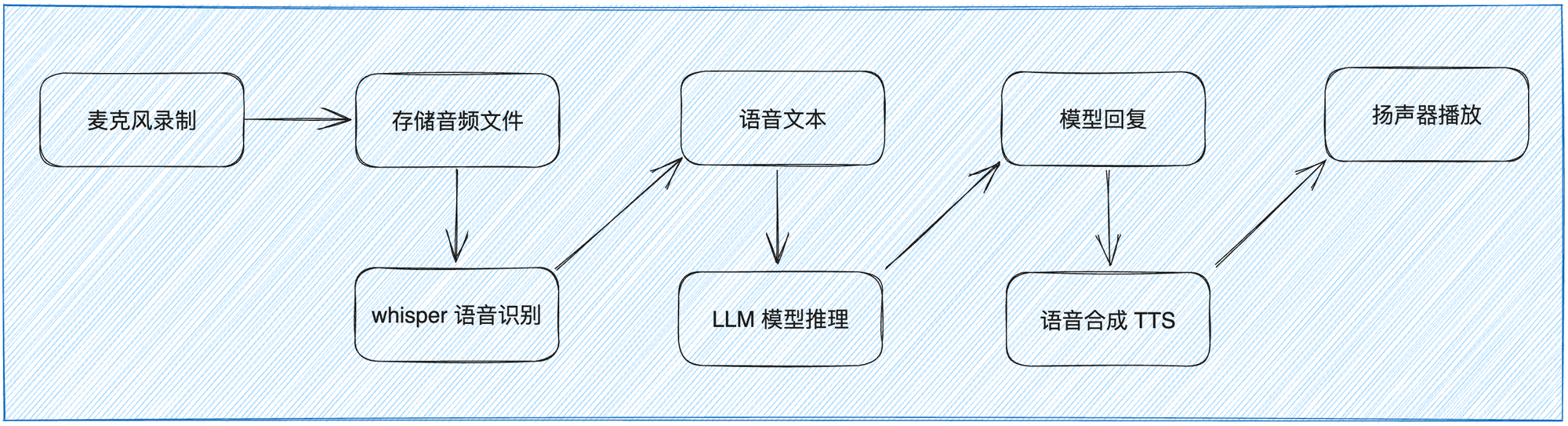
智能语音对话的关键步骤:
- 第一步:设备采集语音输入,然后通过语音识别(ASR)模型(如 Whisper)将语音转换为文本。
- 第二步:然后,将识别的文本将被提交给大型语言模型(如 LLM)进行推理和处理。LLM 模型会根据上下文、语义和用户意图等信息生成回复文本。
- 第三步:最后,生成的文本结果会经过语音合成(TTS)技术转换为语音,并通过设备的扬声器进行播放。
这样,用户就能通过语音与系统进行交互,并听到自然流畅的语音回复。整个过程结合了语音处理、文本处理和语音合成等关键技术,以实现语音对话的交互体验。
三、语音转文字 + 模型推理 + 语音合成
恕我直言,只有极少的天才能够写模型算法,极少数的公司有财力训练模型。市面产品都是套壳,所以各位都别折腾了,直接调用云厂商的 API 吧。
3.1 语音识别
OpenAI 语音转文字 API 是基于开源大型 v2 Whisper 模型。可以用于将音频转录为与音频所在语言相同的语言以及将音频翻译并转录成英文。文件上传目前限制为 25 MB,支持以下输入文件类型:mp3、mp4、mpeg、mpga、m4a、wav 和 webm。
curl --location 'https://api.openai.com/v1/audio/transcriptions' \
--header 'Authorization: Bearer sk-xxxx' \
--form 'model="whisper-1"' \
--form 'file=@"/Users/xxx/output.wav"'
3.2 模型推理
大模型是做什么就不介绍了,这里使用 GPT-3.5-turbo 模型是以一系列消息作为输入,并将模型生成的消息作为输出。
curl --location 'https://api.openai.com/v1/chat/completions' \
--header 'Authorization: Bearer sk-xxx' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"max_tokens": 20,
"messages": [
{
"role": "user",
"content": "Lorem ipsum"
}
]
}'
其中,OpenAI 的 API 服务不对中国大陆开放,可以使用 Cloudflare worker 解决了用户没有 VPN 的痛点。
3.3 语音合成
语音合成(Text-to-Speech,TTS)技术是指将文本转换为语音输出的过程。实现可以使用 AVSpeechSynthesizer 在 iOS 上实现类似于 say 命令的能力,另外一种方式使用 Azure 文本转语音服务,使您的应用程序、工具或设备能够将文本转换为类似人声的合成语音。
curl --location 'https://{xxx}.tts.speech.microsoft.com/cognitiveservices/v1' \
--header 'Ocp-Apim-Subscription-Key: {xxx}' \
--header 'Content-Type: application/ssml+xml' \
--header 'X-Microsoft-OutputFormat: audio-16khz-128kbitrate-mono-mp3' \
--data '<speak version="1.0" xml:lang="en-US">
<voice xml:lang="en-US" xml:gender="Female" name="en-US-JennyNeural">
my voice is my passport verify me
</voice>
</speak>'
其中,Azure 的 API 服务对中国大陆开放,实测网络质量还可以。
四、语音对话 Demo
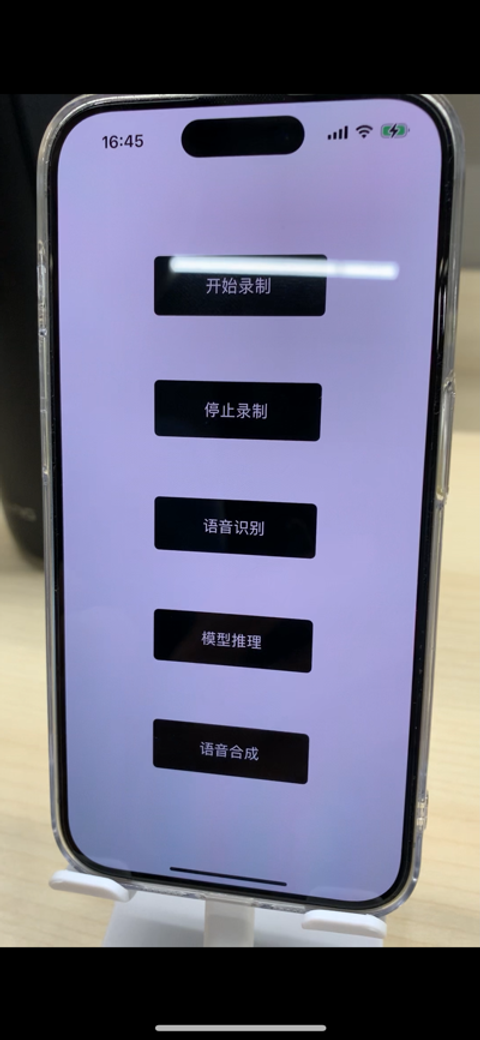
到现在我们完成全部的调研工作,剩下的需要将这一切串联起来,就可以实现一个类似于 ChatGPT mobile App 的语音对话的产品功能。Now, let’s move!
语音采集是在 iOS 上完成的,使用 AVAudioRecorder 原生支持 M4A(MPEG-4 Audio)文件格式。M4A 文件通常包含使用 AAC(Advanced Audio Coding)编码的音频。要使用 AVAudioRecorder 录制 M4A 格式的音频,需要将音频格式设置为 kAudioFormatMPEG4AAC。
NSDictionary *recordSettings = @{
AVFormatIDKey: @(kAudioFormatMPEG4AAC),
AVSampleRateKey: @44100.0,
AVNumberOfChannelsKey: @(channelCount),
AVEncoderAudioQualityKey: @(AVAudioQualityHigh)
};
然后增加一个 APP 操作界面,方便观察每个步骤的进行状态。演示视频前往 B 站: https://www.bilibili.com/video/BV1z94y1t7V6
五、参考资料
- ChatGPT 的语音对话功能 https://twitter.com/onenewbite/status/1706511064660369542
- OpenAI 新发布的语音生成技术 https://openai.com/blog/chatgpt-can-now-see-hear-and-speak
- OpenCat 接入 Azure TTS https://twitter.com/waylybaye/status/1641369899267416064
- LLaMA voice chat + Siri TTS https://twitter.com/ggerganov/status/1640416314773700608
- OpenAI speech-to-text API https://platform.openai.com/docs/guides/speech-to-text
- Azure Text to speech API 文档 https://learn.microsoft.com/en-us/azure/ai-services/speech-service
一分钟了解 ChatGPT 语音对话的更多相关文章
- AI 语音对话技术
机器学习以及自然语言处理技术的进步,开启了人与人工智能进行语音交互的可能,人们透过对话的方式获取信息.与机器进行交互,将不再只是存在科幻情结当中.语音交互是未来的方向,而智能音箱则是语音交互落地的第一 ...
- 百度ai和图灵123实现简单的语音对话
百度ai和图灵123实现简单的语音对话
- 一次因生产事故与chatGpt的对话
一次因生产事故与chatGpt的对话 前言:生产出现了一个内存溢出的事故,记录错误信息.错误日志如下 org.springframework.web.util.NestedServletExcepti ...
- [初识]使用百度AI接口,图灵机器人实现简单语音对话
一.准备 1.百度ai开放平台提供了优质的接口资源https://ai.baidu.com/ (基本免费) 2.在语音识别的接口中, 对中文来说, 讯飞的接口是很好的选择https://www.xf ...
- C# 10分钟完成百度语音技术(语音识别与合成)——入门篇
我们已经讲了人脸识别(入门+进阶).图片识别(入门).下面是链接: C# 10分钟完成百度人脸识别——入门篇 C# 30分钟完成百度人脸识别——进阶篇(文末附源码) C# 10分钟完成百度图片提取文字 ...
- web服务版智能语音对话
在前几篇的基础上,我们有了语音识别,语音合成,智能机器人,那么我们是不是可以创建一个可以实时对象的机器人了? 当然可以! 一,web版智能对话 前提:你得会flask和websocket 1 ,创建f ...
- 使用百度ai接口加图灵机器人完成简单web版语音对话
app文件 from flask import Flask, request, render_template, jsonify, send_file from uuid import uuid4 i ...
- 三分钟使用chatGPT
ChatGPT最近也是火爆出圈,网上已被刷屏. 今天我们说一下,使用ChatGPT的方法,很简单,只需要三步: 前期确保自己能访问google,IP地址为某些国家:否则检查会报错:Services a ...
- SLAM+语音机器人DIY系列:(三)感知与大脑——6.做一个能走路和对话的机器人
摘要 在我的想象中机器人首先应该能自由的走来走去,然后应该能流利的与主人对话.朝着这个理想,我准备设计一个能自由行走,并且可以与人语音对话的机器人.实现的关键是让机器人能通过传感器感知周围环境,并通过 ...
- ChatGPT的那些事 -1- 背景资料
ChatGPT的那些事 -1- 背景资料 多处搬运,学无止境 目 录 1 关键词 1 1.1. AIGC(百度百科) 1 1.2. AlphaGo(百度百科) 1 1.3. ChatG ...
随机推荐
- 手写call&apply&bind
在这里对call,apply,bind函数进行简单的封装 封装主要思想:给对象一个临时函数来调用,调用完毕后删除该临时函数对应的属性 call函数封装 function pliCall(fn, obj ...
- kubernetes(k8s):解决不在同一网段加入集群失败问题
执行下面命令,将内外网进行映射. iptables -t nat -A OUTPUT -d 10.140.128.121 -j DNAT --to-destination 10.170.129.153 ...
- locust与jmeter测试过程及结果对比
JMeter和Locust都是强大的性能测试工具,各自拥有自己的优势和专注领域.JMeter提供了全面的功能和基于GUI的界面,适用于复杂的场景和非技术人员.相比之下,Locust采用了以代码为中心的 ...
- 使用 Go 语言实现二叉搜索树
原文链接: 使用 Go 语言实现二叉搜索树 二叉树是一种常见并且非常重要的数据结构,在很多项目中都能看到二叉树的身影. 它有很多变种,比如红黑树,常被用作 std::map 和 std::set 的底 ...
- 无linux基础也能熟练掌握git的基本操作
git是一个用来管理项目的工具,它的远程仓库有github.gitee.gitlab代码托管中心,既可以用于个人共享代码,又可以用于团队进行项目的协作与发布,那么我们一起来了解一下git该如何使用~ ...
- 小议ml.NET机器学习与人机责任划分
最近,特斯拉宣布召回110万辆车,名义上是纠正单踏板不良习惯,背后原因可能是这些车辆的电子控制单元存在缺陷,可能导致刹车失灵(潮州等交通事故至今没有定论).这个事件引起了人们对于机器学习技术和人机责任 ...
- 【pandas小技巧】--DataFrame的显示参数
我们在jupyter notebook中使用pandas显示DataFrame的数据时,由于屏幕大小,或者数据量大小的原因,常常会觉得显示出来的表格不是特别符合预期. 这时,就需要调整pandas显示 ...
- 史上最强.NET数据分页方法
[前言] 本文讲述的.NET数据分页方法为[史上最强],已被多家大型科技公司实战采用 & 也被圈内多家知名IT培训机构转载收藏. [正文] 支持.Net Core(2.0及以上)与.Net F ...
- ChatGPT如何生成可视化图表-示例中国近几年出生人口
本教程收集于:AIGC从入门到精通教程汇总 ChatGPT本身不能直接生成可视化图表,但可以配合其他可视化工具或库 方法一:前端可视化开发库 Echarts(地址:Apache ECharts ) 方 ...
- What...MiniGPT-4居然开源了,提前感受 GPT-4 的图像对话能力!
说在前面的话: 一个月前,OpenAI向外界展示了GPT-4如何通过手绘草图直接生成网站,令当时的观众瞠目结舌. 在GPT-4发布会之后,相信大家对ChatGPT的对话能力已有所了解.圈内的朋友们应该 ...