MindSpore 自动微分
代码原地址:
https://www.mindspore.cn/tutorial/zh-CN/r1.2/autograd.html
MindSpore计算一阶导数方法 mindspore.ops.GradOperation (get_all=False, get_by_list=False, sens_param=False),其中get_all为False时,只会对第一个输入求导,为True时,会对所有输入求导;
get_by_list为False时,不会对权重求导,为True时,会对权重求导;
sens_param对网络的输出值做缩放以改变最终梯度。
get_all : 决定着是否根据输出对输入进行求导。
get_by_list : 决定着是否对神经网络内的参数权重求导。
sens_param : 对网络的输出进行乘积运算后再求导。(通过对网络的输出值进行缩放后再进行求导)
网络的前向传播:
import numpy as np
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Tensor
from mindspore import ParameterTuple, Parameter
from mindspore import dtype as mstype class Net(nn.Cell):
def __init__(self):
super(Net, self).__init__()
self.matmul = ops.MatMul()
self.z = Parameter(Tensor(np.array([1.0, 1.0, 1.0], np.float32)), name='z') def construct(self, x, y):
x = x * self.z
out = self.matmul(x, y)
return out model = Net() for m in model.parameters_and_names():
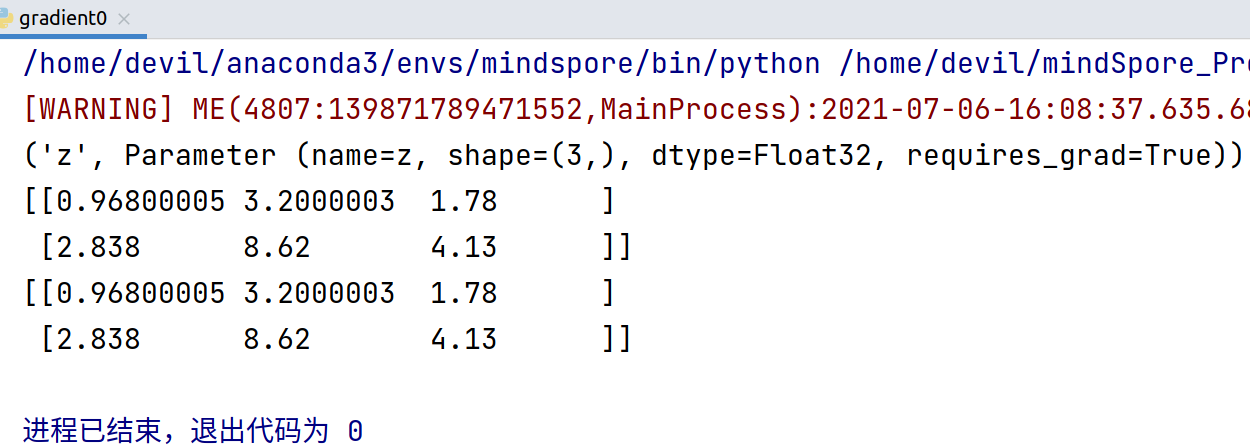
print(m) x = Tensor([[0.8, 0.6, 0.2], [1.8, 1.3, 1.1]], dtype=mstype.float32)
y = Tensor([[0.11, 3.3, 1.1], [1.1, 0.2, 1.4], [1.1, 2.2, 0.3]], dtype=mstype.float32)
result = model(x, y)
print(result) n_x = np.array([[0.8, 0.6, 0.2], [1.8, 1.3, 1.1]], dtype=np.float32)
n_y = np.array([[0.11, 3.3, 1.1], [1.1, 0.2, 1.4], [1.1, 2.2, 0.3]], dtype=np.float32)
result = model(x, y)
print(result)
=======================================================
反向传播:
import numpy as np
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Tensor
from mindspore import ParameterTuple, Parameter
from mindspore import dtype as mstype class Net(nn.Cell):
def __init__(self):
super(Net, self).__init__()
self.matmul = ops.MatMul()
self.z = Parameter(Tensor(np.array([1.0, 1.0, 1.0], np.float32)), name='z') def construct(self, x, y):
x = x * self.z
out = self.matmul(x, y)
return out class GradNetWrtX(nn.Cell):
def __init__(self, net):
super(GradNetWrtX, self).__init__()
self.net = net
self.grad_op = ops.GradOperation() def construct(self, x, y):
gradient_function = self.grad_op(self.net)
return gradient_function(x, y) x = Tensor([[0.8, 0.6, 0.2], [1.8, 1.3, 1.1]], dtype=mstype.float32)
y = Tensor([[0.11, 3.3, 1.1], [1.1, 0.2, 1.4], [1.1, 2.2, 0.3]], dtype=mstype.float32)
output = GradNetWrtX(Net())(x, y)
print(output)
因为, ops.GradOperation(),
mindspore.ops.GradOperation (get_all=False, get_by_list=False, sens_param=False)
get_all=False, 表示只对第一个输入向量求导,也就是对x 求梯度, 结果得到x的梯度:

如果想对所有的输入求梯度, ops.GradOperation(get_all=True)
代码:
import numpy as np
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Tensor
from mindspore import ParameterTuple, Parameter
from mindspore import dtype as mstype class Net(nn.Cell):
def __init__(self):
super(Net, self).__init__()
self.matmul = ops.MatMul()
self.z = Parameter(Tensor(np.array([1.0, 1.0, 1.0], np.float32)), name='z') def construct(self, x, y):
x = x * self.z
out = self.matmul(x, y)
return out class GradNetWrtX(nn.Cell):
def __init__(self, net):
super(GradNetWrtX, self).__init__()
self.net = net
self.grad_op = ops.GradOperation(get_all=True) def construct(self, x, y):
gradient_function = self.grad_op(self.net)
return gradient_function(x, y) x = Tensor([[0.8, 0.6, 0.2], [1.8, 1.3, 1.1]], dtype=mstype.float32)
y = Tensor([[0.11, 3.3, 1.1], [1.1, 0.2, 1.4], [1.1, 2.2, 0.3]], dtype=mstype.float32)
output = GradNetWrtX(Net())(x, y)
print(len(output))
print('='*30)
print(output[0])
print('='*30)
print(output[1])
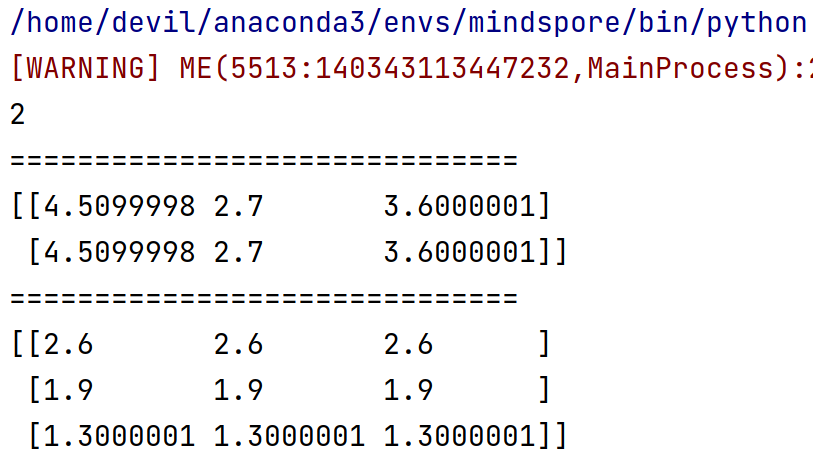
对网络的所有输入求导,即,对 x ,y 求梯度。
对权重求一阶导
对权重求一阶导数其实与前面相比有两个地方要更改:
1. 求导函数要写明对权重求导,即传入参数 get_by_list=True
即,
self.grad_op = ops.GradOperation(get_by_list=True)
2. 具体求导时要传入具体待求导的参数(即,权重):
self.params = ParameterTuple(net.trainable_params())
gradient_function = self.grad_op(self.net, self.params)
细节:


需要知道的一点是如果我们设置了对权重求梯度,则默认不会再对输入求梯度:
代码:
import numpy as np
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Tensor
from mindspore import ParameterTuple, Parameter
from mindspore import dtype as mstype class Net(nn.Cell):
def __init__(self):
super(Net, self).__init__()
self.matmul = ops.MatMul()
self.z = Parameter(Tensor(np.array([1.0, 1.0, 1.0], np.float32)), name='z') def construct(self, x, y):
x = x * self.z
out = self.matmul(x, y)
return out class GradNetWrtX(nn.Cell):
def __init__(self, net):
super(GradNetWrtX, self).__init__()
self.net = net
self.params = ParameterTuple(net.trainable_params())
self.grad_op = ops.GradOperation(get_by_list=True) def construct(self, x, y):
gradient_function = self.grad_op(self.net, self.params)
return gradient_function(x, y) model = Net() x = Tensor([[0.8, 0.6, 0.2], [1.8, 1.3, 1.1]], dtype=mstype.float32)
y = Tensor([[0.11, 3.3, 1.1], [1.1, 0.2, 1.4], [1.1, 2.2, 0.3]], dtype=mstype.float32)
output = GradNetWrtX(model)(x, y)
print(len(output))
print('='*30)
print(output[0])
print('='*30)

如果对网络内部权重求梯度同时也想对输入求梯度,只能显示的设置 get_all=True,
即,
self.grad_op = ops.GradOperation(get_all=True, get_by_list=True)
此时输出的梯度为 元组 , tuple(所有输入的梯度, 内部权重梯度)
也就是说这种情况返回的是一个两个元素的元组,元组中第一个元素是所有输入的梯度,第二个是所有内部权重的梯度。
代码:
import numpy as np
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Tensor
from mindspore import ParameterTuple, Parameter
from mindspore import dtype as mstype class Net(nn.Cell):
def __init__(self):
super(Net, self).__init__()
self.matmul = ops.MatMul()
self.z = Parameter(Tensor(np.array([1.0, 1.0, 1.0], np.float32)), name='z') def construct(self, x, y):
x = x * self.z
out = self.matmul(x, y)
return out class GradNetWrtX(nn.Cell):
def __init__(self, net):
super(GradNetWrtX, self).__init__()
self.net = net
self.params = ParameterTuple(net.trainable_params())
self.grad_op = ops.GradOperation(get_all=True, get_by_list=True) def construct(self, x, y):
gradient_function = self.grad_op(self.net, self.params)
return gradient_function(x, y) model = Net() x = Tensor([[0.8, 0.6, 0.2], [1.8, 1.3, 1.1]], dtype=mstype.float32)
y = Tensor([[0.11, 3.3, 1.1], [1.1, 0.2, 1.4], [1.1, 2.2, 0.3]], dtype=mstype.float32)
output = GradNetWrtX(model)(x, y)
print(len(output))
print('='*30)
print(output[0])
print('='*30)
print(output[1])
运行结果:
[WARNING] ME(6838:140435163703104,MainProcess):2021-07-06-16:56:49.250.395 [mindspore/_check_version.py:109] Cuda version file version.txt is not found, please confirm that the correct cuda version has been installed, you can refer to the installation guidelines: https://www.mindspore.cn/install
2
==============================
(Tensor(shape=[2, 3], dtype=Float32, value=
[[ 4.50999975e+00, 2.70000005e+00, 3.60000014e+00],
[ 4.50999975e+00, 2.70000005e+00, 3.60000014e+00]]), Tensor(shape=[3, 3], dtype=Float32, value=
[[ 2.59999990e+00, 2.59999990e+00, 2.59999990e+00],
[ 1.89999998e+00, 1.89999998e+00, 1.89999998e+00],
[ 1.30000007e+00, 1.30000007e+00, 1.30000007e+00]]))
==============================
(Tensor(shape=[3], dtype=Float32, value= [ 1.17259989e+01, 5.13000011e+00, 4.68000031e+00]),)
进程已结束,退出代码为 0
MindSpore 自动微分的更多相关文章
- MindSpore:自动微分
MindSpore:自动微分 作为一款「全场景 AI 框架」,MindSpore 是人工智能解决方案的重要组成部分,与 TensorFlow.PyTorch.PaddlePaddle 等流行深度学习框 ...
- MindSpore多元自动微分
技术背景 当前主流的深度学习框架,除了能够便捷高效的搭建机器学习的模型之外,其自动并行和自动微分等功能还为其他领域的科学计算带来了模式的变革.本文我们将探索如何用MindSpore去实现一个多维的自动 ...
- 附录D——自动微分(Autodiff)
本文介绍了五种微分方式,最后两种才是自动微分. 前两种方法求出了原函数对应的导函数,后三种方法只是求出了某一点的导数. 假设原函数是$f(x,y) = x^2y + y +2$,需要求其偏导数$\fr ...
- pytorch学习-AUTOGRAD: AUTOMATIC DIFFERENTIATION自动微分
参考:https://pytorch.org/tutorials/beginner/blitz/autograd_tutorial.html#sphx-glr-beginner-blitz-autog ...
- 自动微分(AD)学习笔记
1.自动微分(AD) 作者:李济深链接:https://www.zhihu.com/question/48356514/answer/125175491来源:知乎著作权归作者所有.商业转载请联系作者获 ...
- <转>如何用C++实现自动微分
作者:李瞬生转摘链接:https://www.zhihu.com/question/48356514/answer/123290631来源:知乎著作权归作者所有. 实现 AD 有两种方式,函数重载与代 ...
- (转)自动微分(Automatic Differentiation)简介——tensorflow核心原理
现代深度学习系统中(比如MXNet, TensorFlow等)都用到了一种技术——自动微分.在此之前,机器学习社区中很少发挥这个利器,一般都是用Backpropagation进行梯度求解,然后进行SG ...
- PyTorch自动微分基本原理
序言:在训练一个神经网络时,梯度的计算是一个关键的步骤,它为神经网络的优化提供了关键数据.但是在面临复杂神经网络的时候导数的计算就成为一个难题,要求人们解出复杂.高维的方程是不现实的.这就是自动微分出 ...
- 【tensorflow2.0】自动微分机制
神经网络通常依赖反向传播求梯度来更新网络参数,求梯度过程通常是一件非常复杂而容易出错的事情. 而深度学习框架可以帮助我们自动地完成这种求梯度运算. Tensorflow一般使用梯度磁带tf.Gradi ...
- PyTorch 自动微分示例
PyTorch 自动微分示例 autograd 包是 PyTorch 中所有神经网络的核心.首先简要地介绍,然后训练第一个神经网络.autograd 软件包为 Tensors 上的所有算子提供自动微分 ...
随机推荐
- C#.NET WINFORM 缓存 System.Runtime.Caching MemoryCache
C#.NET WINFORM 缓存 System.Runtime.Caching MemoryCache 工具类: using System; using System.Runtime.Caching ...
- MySQL Docker搭建挂载并启用远程连接
1.拉取镜像 后面可以指定版本号,这里使用8.0 docker pull docker.io/mysql:8.0 2.查看mysql镜像 docker images 3.启动docker并挂载 doc ...
- Vue聊天框自动滚动底部
原理:通过监听数据更新,将滚动的最大高度赋值给滚动条的最大高度,并等待页面更新完成后再将页面滚动到底部. 容器代码 watch监听 scrollTop: 距离最顶部高度 scrollHeight:滚动 ...
- CLR via C# 笔记 -- 委托(17)
1. 委托是方法的包装器,使方法能通过包装器来间接回调.在一个类型中通过委托来调用另一个类型的私有成员,只要委托对象是具有足够安全性/可访问性的代码创建,便没有问题. 2. 协变性:方法能返回从委托的 ...
- map端join和reduce端join的区别
MapReduce Join MapJoin和ReduceJoin区别及优化 maptask处理后写到本地,如果再到reduce,又涉及到网络的拷贝. map端join最大优势,可以提前过滤不需要的数 ...
- Go 如何对多个网络命令空间中的端口进行监听
Go 如何对多个网络命令空间中的端口进行监听 需求为 对多个命名空间内的端口进行监听和代理. 刚开始对 netns 的理解不够深刻,以为必须存在一个新的线程然后调用 setns(2) 切换过去,如果有 ...
- ChiFAN 的进程表
ChiFAN 的进程表 tip 有些题写了题解,思路做法都在里面,就只丢一个传送门了. 2023.1.9 生日蛋糕 传送门 IDA* 经过一番推式子可得,若还剩下 \(K\) 的体积,表面积为 \(2 ...
- HIVE从入门到精通------(1)hive的基本操作
1.开启hive 1.首先在master的/usr/local/soft/下启动hadoop: master : start-all.sh start-all.sh 2.在另一个master(2)上监 ...
- redis出现错误提示MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk. Commands that may modify the data set are disabled. Please check Redis logs for......
某天,redis出现了这样一个错误提示: MISCONF Redis is configured to save RDB snapshots, but is currently not able to ...
- 算法金 | 最难的来了:超参数网格搜索、贝叶斯优化、遗传算法、模型特异化、Hyperopt、Optuna、多目标优化、异步并行优化
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」 今日 215/10000 为模型找到最好的超参数是机器学习实践中最困难的部分之一 ...