SSE与AVX指令基础介绍与使用
SSE与AVX指令基础介绍与使用
SSE/AVX指令属于Intrinsics函数,由编译器在编译时直接在调用处插入代码,避免了函数调用的额外开销。但又与inline函数不同,Intrinsics函数的代码由编译器提供,能够更高效地使用机器指令进行优化调整。
在开始之前可以先在CPU-Z或者Intel产品规范查看自己CPU的指令集支持情况。
关于SSE和AVX内部函数的相关信息也都可以在Intel Intrinsics Guide查看。
1.头文件
SSE和AVX指令集有多个不同版本,其函数也包含在对应版本的头文件里。
若不关心具体版本则可以使用 <intrin.h> 包含所有版本的头文件内容。
#include <intrin.h>
以下是头文件对照表
File 描述 VS VisualStudio intrin.h All Architectures 8.0 2005 mmintrin.h MMX intrinsics 6.0 6.0 SP5+PP5 xmmintrin.h Streaming SIMD Extensions intrinsics 6.0 6.0 SP5+PP5 emmintrin.h Willamette New Instruction intrinsics (SSE2) 6.0 6.0 SP5+PP5 pmmintrin.h SSE3 intrinsics 9.0 2008 tmmintrin.h SSSE3 intrinsics 9.0 2008 smmintrin.h SSE4.1 intrinsics 9.0 2008 nmmintrin.h SSE4.2 intrinsics. 9.0 2008 wmmintrin.h AES and PCLMULQDQ intrinsics. 10.0 2010 immintrin.h Intel-specific intrinsics(AVX) 10.0 2010 SP1 ammintrin.h AMD-specific intrinsics (FMA4, LWP, XOP) 10.0 2010 SP1 mm3dnow.h AMD 3DNow! intrinsics 6.0 6.0 SP5+PP5
另外,在Intel Intrinsics Guide也可以查询到每个函数所属的指令集和对应的头文件信息。
2.编译选项
除了头文件以外,我们还需要添加额外的编译选项,才能保证代码被编译成功。
各版本的SSE和AVX都有单独的编译选项,比如-msseN, -mavxN(N表示版本编号)。
经过简单测试后发现,此类编译选项支持向下兼容,比如-msse4可以编译SSE2的函数,-mavx也可以兼容各版本的SSE。
本文中的内容最多涉及到AVX2主要是我的CPU最多支持到这(悲),所以只需要一个-mavx2就能正常运行文中的所有代码。
3.数据类型
Intel目前主要的SIMD指令集有MMX, SSE, AVX, AVX-512,其对处理的数据位宽分别是:
- 64位 MMX
- 128位 SSE
- 256位 AVX
- 512位 AVX-512
每种位宽对应一个数据类型,名称包括三个部分:
- 前缀 __m,两个下划线加m。
- 中间是数据位宽。
- 最后加上的字母表示数据类型,i为整数,d为双精度浮点数,不加字母则是单精度浮点数。
比如SSE指令集的 __m128, __m128i, __m128d
AVX则包括 __m256, __m256i, __m256d。
这里的位宽指的是SIMD寄存器的位宽,CPU需要先将数据加载进专门的寄存器之后再并行计算。
4.Intrinsic函数命名
同样,Intrinsic函数的命名通常也是由3个部分构成:
- 第一部分为前缀_mm,MMX和SSE都为_mm开头,AVX和AVX-512则会额外加上256和512的位宽标识。
- 第二部分表示执行的操作,比如_add,_mul,_load等,操作本身也会有一些修饰,比如_loadu表示以无需内存对齐的方式加载数据。
- 第三部分为操作选择的数据范围和数据类型,比如_ps的p(packed)表示所有数据,s(single)表示单精度浮点。_ss则表示s(single)第一个,s(single)单精度浮点。_epixx(xx为位宽)操作所有的xx位的有符号整数,_epuxx则是操作所有的xx位的无符号整数。
例如_mm256_load_ps表示将浮点数加载进整个256位寄存器中。
绝大部分Intrinsic函数都是按照这样的格式构成,每个函数也都能在Intel Intrinsics Guide找到更为完整的描述。
5.SSE基础应用
进入正题,现在我们有一个程序需要对A、B数组求和,并将结果写入数组C。
#include <stdio.h>
#define SIZE 100000
int main()
{
float A[SIZE], B[SIZE], C[SIZE];
for(int i = 0; i < SIZE; i++)
C[i] = A[i] + B[i];
}
现在我们来一步步地使用SSE修改这个程序,进行数据并行优化。
导入头文件。
#include <intrin.h>
创建3个__m128寄存器分别存储三个数组的float值
__m128 ra, rb, rc;
到了循环体内,我们需要把A、B的值写入寄存器之中,这就需要用到_mm_loadu_ps函数,他会把从指针位置开始的后128位的数据写入寄存器。
至于为什么用loadu而不是load,这个稍后会进行解释。
ra = _mm_loadu_ps(A + i);
rb = _mm_loadu_ps(B + i);
括号里的A+i等价于&A[i]。
之后就是用_mm_add_ps函数计算ra、rb相加,然后把结果返回到rc之中。
rc = _mm_add_ps(ra, rb);
当然还没结束,rc的值还得写回到C数组,这就要用到_mm_storeu_ps函数。
依旧是u结尾的storeu而不是store。
_mm_storeu_ps(C + i, rc);
因为128位寄存器一次可以写入4个(128/32)float值,等于一次循环计算4个float的加法,循环的跨度也应该由1变为4,这样循环次数就只需要原来的1/4。
for (int i = 0; i < SIZE; i += 4)
这样就基本的雏形就完成了,不过在运行之前,别忘了加上编译选项。
#include <stdio.h>
#include <intrin.h>
#define SIZE 100000
int main()
{
float A[SIZE], B[SIZE], C[SIZE];
for (int i = 0; i < SIZE; i += 4) // 一次计算4个数据,所以要改成+4
{
__m128 ra = _mm_loadu_ps(A + i); // ra = {A[i], A[i+1], A[i+2], A[i+3]}
__m128 rb = _mm_loadu_ps(B + i); // rb = {B[i], B[i+1], B[i+2], B[i+3]}
__m128 rc = _mm_add_ps(ra, rb); // rc = ra + rb
_mm_storeu_ps(C + i, rc); // C[i~i+3] <= rc
}
}
现在对比一下加速的效果:
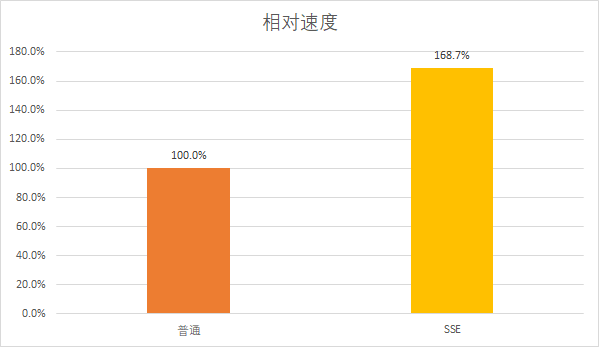
看到这个结果你可能还是有些失望,明明只循环了原来的1/4次,速度却只有1.7倍。
但还没完,前面为了清晰地展示逻辑,导致代码中用了非常多不必要的中间变量(ra、rb、rc都是),作为一个压行选手自然不能容忍这种事情发生,再进行简化一下:
#include <stdio.h>
#include <intrin.h>
#define SIZE 100000
int main()
{
float A[SIZE], B[SIZE], C[SIZE];
for (int i = 0; i < SIZE; i += 4)
{
_mm_storeu_ps(C + i, _mm_add_ps(_mm_loadu_ps(A + i), _mm_loadu_ps(B + i))); // 压行好耶!
}
}
现在再来看看加速情况:
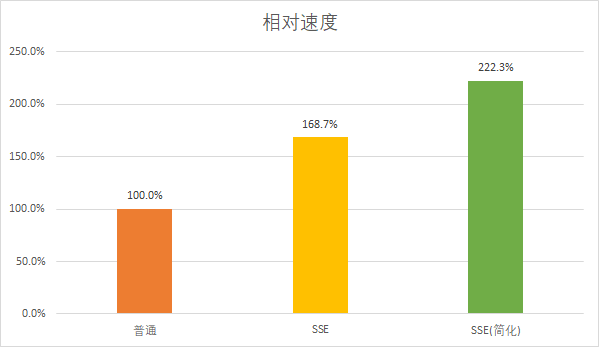
简化后达到了2.2倍的速度,相较简化前已经有了大幅度的提升,但即使如此,距离理论上的4倍也还有很大的优化空间,让我们接着看还有什么优化的方法。
6.内存对齐
6.1为什么用loadu
我们刚刚用load和store进行加载和存储的时候,在二者后面加了个‘u’作为修饰,这个u就表示着无需内存对齐。
二者的区别体现在于Intel Intrinsics Guide中的这一句话。
_mm_store_ps : mem_addr must be aligned on a 16-byte boundary or a general-protection exception may be generated.
_mm_storeu_ps : mem_addr does not need to be aligned on any particular boundary.
也就是说不加u的版本需要原数据有16字节内存对齐,否则在读取的时候就会触发边界保护产生异常。
xx字节对齐的意思是要求数据的地址是xx字节的整数倍,128位宽的SSE要求16字节内存对齐,而256位宽的AVX函数则是要求32字节内存对齐。
可以明显地看出,内存对齐要求的字节数就是指令需要处理的字节数,而要求内存对齐也是为了能够一次访问就完整地读到数据,从而提升效率。
6.2如何进行内存对齐
既然内存对齐后能达到更好的性能,那么我们应该怎么做呢?
创建变量时设置N字节对齐可以用:
- __declspec(align(N)),MSVC专用关键字
- __attribute__((__aligned__(N))),GCC专用关键字
- alignas(N),C++11关键字,不过我这里测试只能指定到16,否则就会warning并且无法生效。
只需要在创建变量时在类型名前加上这几个关键字,就像下面这样:
alignas(16) float A[SIZE]; // C++11
__declspec(align(16)) float B[SIZE]; // MSVC
__attribute__((__aligned__(16))) float C[SIZE]; // GCC
对于new或malloc这种申请的内存也有相应的设置方法:
- _aligned_malloc(size, N),包含在<stdlib.h>头文件中,与malloc相比多了一个参数N用于指定内存对齐。注意!用此方法申请的内存需要用 _aligned_free() 进行释放。
- new((std::align_val_t) N),C++17新特性,需要在GCC7及以上版本使用 -std=c++17 编译选项开启。
具体使用方式如下:
float *A = new ((std::align_val_t)32) float[SIZE]; // C++17
float *B = (float *)_aligned_malloc(sizeof(float) * SIZE, 32); // <stdlib.h>
_aligned_free(B); // 用于释放_aligned_malloc申请的内存
使用关键字把数组进行16字节内存对齐后,就可以放心地把loadu和storeu替换成load和store。
#include <stdio.h>
#include <intrin.h>
#define SIZE 100000
int main()
{
__attribute__((__aligned__(16))) float A[SIZE], B[SIZE], C[SIZE]; // GCC的内存对齐
for (int i = 0; i < SIZE; i += 4)
{
_mm_store_ps(C + i, _mm_add_ps(_mm_load_ps(A + i), _mm_load_ps(B + i))); // 用store和load替换storeu和loadu
}
}
在我的测试平台,编译器会自动对数组和申请的内存空间进行16字节对齐,所以这次修改对SSE指令其实影响不大,但到后面使用要求32字节对齐的AVX指令就很有必要了。
不过我们可以手动将其修改为8字节对齐,来对比一下与16字节之间的性能差距:
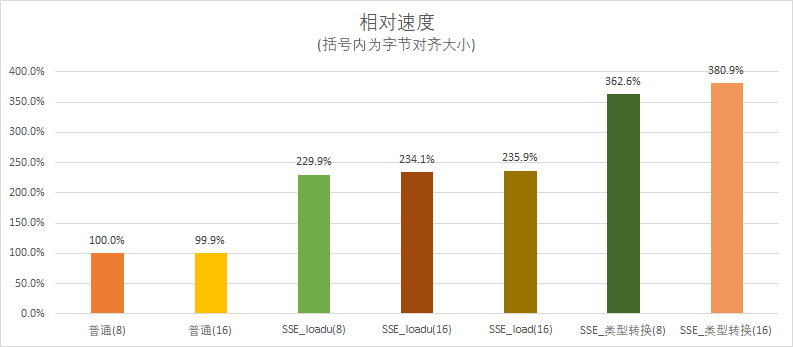
可以看到对于load和loadu,内存对齐之后速度只有略微的提升。
但你肯定也注意到了,这个所谓的“类型转换”居然直接霸榜了,内存对齐之后更是从3.6提升到了3.8倍,这已经非常接近理论上的4倍提升了。
那么接下来我们就来了解一下这个“类型转换”究竟是什么。
7.类型转换
对代码进行单步调试,观察一下几个函数在头文件中的实现方式。
在程序运行到_mm_load_ps时点击单步进入,到达函数内部。
/* Load four SPFP values from P. The address must be 16-byte aligned. */
extern __inline __m128 __attribute__((__gnu_inline__, __always_inline__, __artificial__))
_mm_load_ps (float const *__P)
{
return *(__m128 *)__P;
}
_mm_loadu_ps对应的类型是*(__m128_u *)__P
忽视上面的几个声明,可以发现这个函数只是对传入的指针进行了一次类型转换,这个转换看着可能有点绕,但拆分后其实很简单,将*(__m128 *)__P分成两个部分:
- (__m128 *)__P:将__P从float *类型转换为__m128 *
- *:访问__m128 *指针指向的__m128对象
而_mm_store_ps也是类似的操作:
/* Store four SPFP values. The address must be 16-byte aligned. */
extern __inline void __attribute__((__gnu_inline__, __always_inline__, __artificial__))
_mm_store_ps (float *__P, __m128 __A)
{
*(__m128 *)__P = __A;
}
既然这么简单,那我们完全可以自己手动来实现这一步:
#include <stdio.h>
#include <intrin.h>
#define SIZE 100000
int main()
{
__attribute__((__aligned__(16))) float A[SIZE], B[SIZE], C[SIZE];
for (int i = 0; i < SIZE; i += 4)
{
*(__m128 *)(C + i) = _mm_add_ps(*(__m128 *)(A + i), *(__m128 *)(B + i)); // 使用类型转换
}
}
转换成__m128*同样是有内存对齐要求的,若是低于16字节对齐就会在访问指针时出错,非对齐的情况应该使用__m128_u*指针。
8.AVX
AVX的用法与SSE相同,只需要根据命名规律修改一下数据类型和函数的名称就可以了。
AVX的数据处理位宽为256位,是SSE的两倍,因此内存对齐要求也提升到了 32字节。
#include <stdio.h>
#include <intrin.h>
#define SIZE 100000
int main()
{
__attribute__((__aligned__(32))) float A[SIZE], B[SIZE], C[SIZE]; // 32字节对齐
for (int i = 0; i < SIZE; i += 8) // 循环跨度修改为8
{
*(__m256 *)(C + i) = _mm256_add_ps(*(__m256 *)(A + i), *(__m256 *)(B + i)); // 使用256位宽的数据与函数
}
}
来测试一下速度提升:
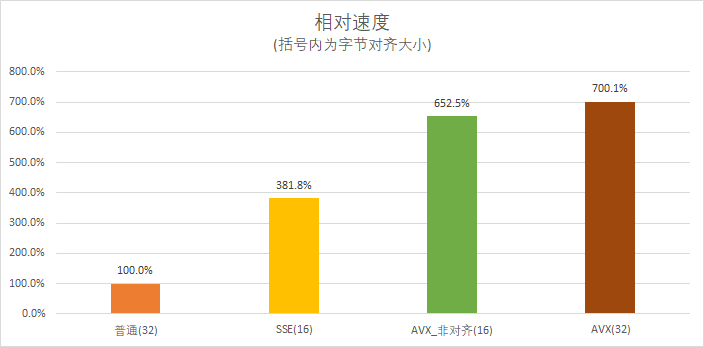
可以看到内存对齐方式对AVX的性能也是有一定影响的,在内存对齐之后AVX也能达到7倍的提升。
9.整数操作
最后是对SSE/AVX整数操作的一些简单补充,文章开头介绍时提到过,整数计算使用的数据类型是__m128i/__m256i,二者都是以i结尾。
还有基本的算数函数,比如SSE的加法add,epi表示整数,后面的数字就是单个整数的数据位宽。比如epi8就是1字节char加法,4字节int加法就是epi32。
__m128i _mm_add_epi8 (__m128i a, __m128i b)
__m128i _mm_add_epi16 (__m128i a, __m128i b)
__m128i _mm_add_epi32 (__m128i a, __m128i b)
__m128i _mm_add_epi64 (__m128i a, __m128i b)
最坑的一个就是整数乘法,还是以SSE为例:
// mul
__m128i _mm_mul_epi32 (__m128i a, __m128i b)
__m128i _mm_mul_epu32 (__m128i a, __m128i b)
// mullo
__m128i _mm_mullo_epi16 (__m128i a, __m128i b)
__m128i _mm_mullo_epi32 (__m128i a, __m128i b)
__m128i _mm_mullo_epi64 (__m128i a, __m128i b)
// mulhi
__m128i _mm_mulhi_epi16 (__m128i a, __m128i b)
__m128i _mm_mulhi_epu16 (__m128i a, __m128i b)
可以看到有三种不同功能的乘法,如果没有事先了解过的话很极其容易用错版本,强烈建议使用之前到Intel Intrinsics Guide查看一下功能描述。
参考文献
在C/C++代码中使用SSE等指令集的指令(3)SSE指令集基础
本文发布于2022年12月7日
最后修改于2022年12月7日
SSE与AVX指令基础介绍与使用的更多相关文章
- SIMD指令集——一条指令操作多个数,SSE,AVX都是,例如:乘累加,Shuffle等
SIMD指令集 from:https://zhuanlan.zhihu.com/p/31271788 SIMD,即Single Instruction, Multiple Data,一条指令操作多个数 ...
- [转]SIMD、MMX、SSE、AVX、3D Now!、NEON
转载来源<[整理]SIMD.MMX.SSE.AVX.3D Now!.neon> 本文摘取部分内容,详细请看原文. SIMD NEON是通用的SIMD(单指令多数据)引擎. 对于SISD,每 ...
- php数据结构课程---1、数据结构基础介绍(程序是什么)
php数据结构课程---1.数据结构基础介绍(程序是什么) 一.总结 一句话总结: 程序=数据结构+算法 设计好数据结构,程序就等于成功了一半. 数据结构是程序设计的基石. 1.数据的逻辑结构和物理结 ...
- DeepFaceLab: SSE,AVX, OpenCL 等版本说明!
Deep Fake Lab早期只有两个版本,一个是专门正对NVIDIA显卡的CUDA9的版本,另一个是支持CPU的版本. 三月初该项目作者对tenserFlow,Cuda的版本进行了升级,预编译的软件 ...
- XML基础介绍【一】
XML基础介绍[一] 1.XML简介(Extensible Markup Language)[可扩展标记语言] XML全称为Extensible Markup Language, 意思是可扩展的标记语 ...
- Web3D编程入门总结——WebGL与Three.js基础介绍
/*在这里对这段时间学习的3D编程知识做个总结,以备再次出发.计划分成“webgl与three.js基础介绍”.“面向对象的基础3D场景框架编写”.“模型导入与简单3D游戏编写”三个部分,其他零散知识 ...
- C++ 迭代器 基础介绍
C++ 迭代器 基础介绍 迭代器提供对一个容器中的对象的访问方法,并且定义了容器中对象的范围.迭代器就如同一个指针.事实上,C++的指针也是一种迭代器.但是,迭代器不仅仅是指针,因此你不能认为他们一定 ...
- Node.js学习笔记(一)基础介绍
什么是Node.js 官网介绍: Node.js® is a JavaScript runtime built on Chrome's V8 JavaScript engine. Node.js us ...
- Node.js 基础介绍
什么是Node.js 官网介绍: Node.js® is a JavaScript runtime built on Chrome's V8 JavaScript engine. Node.js us ...
- AngularJS指令基础(一)
AngularJS指令基础(一) 1.什么是指令:粗暴的理解就是,自定义HTML标签.专业理解是指,angularJS扩展具有自定义功能的HTML元素的途径. 2.什么时候用到指令:需求是变化的.多样 ...
随机推荐
- 【libGDX】使用Mesh绘制立方体
1 前言 本文主要介绍使用 Mesh 绘制立方体,读者如果对 Mesh 不太熟悉,请回顾以下内容: 使用Mesh绘制三角形 使用Mesh绘制矩形 使用Mesh绘制圆形 在绘制立方体的过程中,主 ...
- Ansible Ad-hoc,命令执行模块
目录 Ad-hoc Ad-hoc简介 Ad-hoc命令说明 Ad-hoc示例 命令执行模块 1. command模块 2. shell模块 3. raw模块 4. script模块 Ad-hoc Ad ...
- 项目实战:Qt+OpenCV激光射击游(识别激光、识别圆)
若该文为原创文章,未经允许不得转载原博主博客地址:https://blog.csdn.net/qq21497936原博主博客导航:https://blog.csdn.net/qq21497936/ar ...
- 麒麟系统开发笔记(四):从Qt源码编译安装之编译安装QtCreator4.8.1,并配置编译测试Demo
前言 本篇紧接上一篇,上一篇已经从Qt源码编译了Qt,那么Qt开发的IDE为QtCreator,本篇从源码编译安装QtCreator,并配置好构建套件,运行Demo并测试. QtCreator ...
- 在矩池云上使用R和RStudio
租用机器 在矩池云租用机器的时候,系统环境里搜索:R,选择 R4.2 镜像,如果需要使用RStudio,还需要在高级选项中新增一个自定义端口:8787,然后点击租用即可. 使用 JupyterLab ...
- matrox的RAP4G4C12 CXP采集卡软件安装
Hello-FPGA info@hello-fpga.cOM matrox的RAP4G4C12 CXP采集卡软件安装 目录 matrox的RAP4G4C12 CXP采集卡软件安装 4 1 前言 4 2 ...
- 【Azure App Service】Web Job 报错 UNC paths are not supported. Defaulting to Windows directory.
问题描述 PHP的Web Job,通过artisan来配置路径启动PHP任务,相关启动脚本如下: artisan_path = "d:\\home\\site\\wwwroot"; ...
- 【Azure 应用服务】如何禁止chinacloudsites.cn 访问?
问题描述 Azure App Service创建后,默认会有一个 Azure App Service创建后,默认会有一个 https://xxxxxxxxxxxxx.chinacloudsites. ...
- 【Azure 事件中心】如何查看事件中心的消息中具体报文内容呢?
问题描述 如何查看事件中心的消息中具体报文内容呢? 问题解答 正常情况是通过 Event Hub 的消费端获取消息进行处理查看,但是没有客户端代码的情况下,也可以通过微软的默认客户端Service B ...
- 浅析图数据库 Nebula Graph 数据导入工具——Spark Writer
从 Hadoop 说起 近年来随着大数据的兴起,分布式计算引擎层出不穷.Hadoop 是 Apache 开源组织的一个分布式计算开源框架,在很多大型网站上都已经得到了应用.Hadoop 的设计核心思想 ...