基于Netty包中的Recycler实现的对象池技术详解
一、业务背景
当项目中涉及到频繁的对象的创建和回收的时候,就会出现频繁GC的情况,这时就出现了池化的技术来实现对象的循环使用从而避免对象的频繁回收,Netty包下的Recycler就实现了这一功能。当创建对象的时候直接从池中获取,但使用完毕进行回收的时候,
直接将对象回收到池中,这样可以大量减少对象的创建和回收,是对JVM优化的很好的手段
二、Recycler的使用案例
首先定义需要池化的对象User
public class User
{
/**
* 初始化对象池
* */
private static final Recycler<User> RECYCLER = new Recycler<User>() {
@Override
protected User newObject(Handle<User> handle) {
//如果对象池中没有对象,则调用此方法创建默认的对象实例
return new User(handle);
}
}; /**
* 获取对象实例,从对象池中获取
* */
public static User getInstance(){
return RECYCLER.get();
} /**
* handle是对象的封装类,可以看做一个handle就对应一个User
* */
private final Recycler.Handle<User> handle; /**
* 对象的构造方法,采用private,避免通过构造方法直接创建对象实例
* */
private User(Handle<User> handle){
System.out.println(Thread.currentThread().getName()+"创建对象:"+this.toString());
this.handle = handle;
} /**
* 回收对象
* */
public void recycle(){
//将当前对象进行回收到池中
System.out.println("回收对象:"+this.toString());
this.handle.recycle(this);
} /**
* 初始化对象的值,给从池中获取的对象进行初始化赋值
* */
public void init(Long userId, String userName){
this.userId = userId;
this.userName = userName;
} private Long userId; private String userName; public Long getUserId()
{
return userId;
} public void setUserId(Long userId)
{
this.userId = userId;
} public String getUserName()
{
return userName;
} public void setUserName(String userName)
{
this.userName = userName;
}
}
测试案例的Main方法如下:
public class RecyclerMain
{ public static void main(String[] args) throws InterruptedException
{
Thread t1 = new Thread(new Runnable()
{ @Override
public void run()
{
//1.从对象池中获取对象,由于对象池中没有空对象,所以新建
User user1 = User.getInstance();
System.out.println(user1.toString());
//2.从对象池中获取对象,由于对象池中没有空对象,所以新建
User user2 = User.getInstance();
System.out.println(user2.toString());
//3.将对象user2回收
user2.recycle();
//从对象池中获取对象,由于对象池中有回收的user2,所以直接返回user2对象
User user3 = User.getInstance();
System.out.println(user3.toString());
//将对象进行回收
user1.recycle();
}
});
t1.start(); //睡眠1秒,确保线程t1将user1进行了回收
Thread.sleep(1000L); //1.从对象池中获取对象,虽然线程t1的对象池中已经回收了user1对象,但是所属的线程是t1的线程池
//而当前线程是Main线程,main线程的对象池中是没有对象的,所以会新建对象
User user1 = User.getInstance();
System.out.println(user1.toString());
//回收user1对象
user1.recycle();
//获取的对象是刚刚被回收的user1对象
User user2 = User.getInstance();
System.out.println(user2.toString());
}
}
执行结果如下:
Thread-0创建对象:com.mrhu.opin.recycle.User@59f45845
com.mrhu.opin.recycle.User@59f45845
Thread-0创建对象:com.mrhu.opin.recycle.User@8d37841
com.mrhu.opin.recycle.User@8d37841
回收对象:com.mrhu.opin.recycle.User@8d37841
com.mrhu.opin.recycle.User@8d37841
回收对象:com.mrhu.opin.recycle.User@59f45845
main创建对象:com.mrhu.opin.recycle.User@6d06d69c
com.mrhu.opin.recycle.User@6d06d69c
回收对象:com.mrhu.opin.recycle.User@6d06d69c
com.mrhu.opin.recycle.User@6d06d69c
有一点需要注意:对象池的生命周期是和线程绑定的,也就是说不同的线程会有不同的线程池,所以如果线程1将对象回收了,线程2从对象池中获取对象是获取不到线程1回收的对象的。
但是存在一种情况,创建对象的时候是通过线程1创建的,但是回收的时候是通过线程2回收的,这样的场景会出现什么的结果呢?案例如下:
public class RecyclerMain
{
static User user = null; public static void main(String[] args) throws InterruptedException
{
//从Main线程的对象池中获取对象
user = User.getInstance();
System.out.println(user); Thread t1 = new Thread(new Runnable()
{
@Override
public void run()
{
//回收Main线程创建的user对象
user.recycle();
}
});
t1.start(); //睡眠1秒,确保线程t1将对象user回收了
Thread.sleep(1000); //从main线程的对象池中获取对象,虽然main线程没有回收对象,但是线程t1已结将对象user进行了回收
//所以user2将会从对象池中获取对象
User user2 = User.getInstance();
//user2的toString和user的toString相等
System.out.println(user2.toString());
}
}
结果如下:
main创建对象:com.mrhu.opin.recycle.User@8807e25
com.mrhu.opin.recycle.User@8807e25
线程Thread-1回收对象:com.mrhu.opin.recycle.User@8807e25
com.mrhu.opin.recycle.User@8807e25
可以得出结论:对象是和线程绑定的,也就是说对象是哪个线程创建的,那么不管这个对象是通过哪个线程回收的,最终都会回收到创建这个对象的线程池中去。
三、Recycler的实现原理
目前已经了解了对象池的大致用法,那么现在再了解下Recycler的实现原理是如何的。目前知道的情况是Recycler是和线程绑定的,那么很容易就想到了一个工具-----ThreadLocal
另外对象池存储对象地方需要提供两个方法,一个是将对象放回池,一个是从池中获取对象,Java中很多集合都可以实现这样的功能,而Recycler采用的是栈这样的数据结构,实现是Recycler的一个内部类Stack。
由于一个线程对应一个对象池,所以每个线程也对应一个Stack对象
Stack源码如下:
Stack的属性
final Recycler<T> parent;//所属的Recycler对象
final WeakReference<Thread> threadRef;//绑定的线程引用,是个弱引用
final AtomicInteger availableSharedCapacity;//stack的容量
final int maxDelayedQueues; //最大延迟队列的长度
private final int maxCapacity;//最大容量
private final int ratioMask;
private DefaultHandle<?>[] elements;//存储对象的数组,每个对象被封装成DefaultHandle对象
private int size;//当前stack的大小
private int handleRecycleCount = -1; // Start with -1 so the first one will be recycled.
private WeakOrderQueue cursor, prev;//执行当前和上一个WeakOrderQueue
private volatile WeakOrderQueue head;//执行头WeakOrderQueue
Stack(Recycler<T> parent, Thread thread, int maxCapacity, int maxSharedCapacityFactor,
int ratioMask, int maxDelayedQueues) {
this.parent = parent;
threadRef = new WeakReference<Thread>(thread);
this.maxCapacity = maxCapacity;
availableSharedCapacity = new AtomicInteger(max(maxCapacity / maxSharedCapacityFactor, LINK_CAPACITY));
elements = new DefaultHandle[min(INITIAL_CAPACITY, maxCapacity)];
this.ratioMask = ratioMask;
this.maxDelayedQueues = maxDelayedQueues;
}
对象池中的对象被封装成了Handle对象,Handle的默认实现类是DefaultHandler,源码如下:
public interface Handle<T> {
void recycle(T object);
}
static final class DefaultHandle<T> implements Handle<T> {
private int lastRecycledId;
private int recycleId;
boolean hasBeenRecycled;
private Stack<?> stack;
private Object value;
DefaultHandle(Stack<?> stack) {
this.stack = stack;
}
@Override
public void recycle(Object object) {
if (object != value) {
throw new IllegalArgumentException("object does not belong to handle");
}
stack.push(this);
}
}
可以看出每个对象的封装类DefaultHandler内部是有一个Stack的引用,所以说每个对象创建之后就会绑定一个stack,而stack绑定了一个线程,所以可以说每一个对象是和一个线程绑定的,从哪个线程创建就会从哪个线程回收。
了解了对象的存储结构之后,再看下对象是如何获取的。对象的获取是通过对象池的get()方法进行获取对象,源码如下:
public final T get() {
if (maxCapacityPerThread == 0) {
return newObject((Handle<T>) NOOP_HANDLE);
}
//从threadLocal对象中获取本线程的Stack对象
Stack<T> stack = threadLocal.get();
//调用stack的pop方法获取一个对象
DefaultHandle<T> handle = stack.pop();
if (handle == null) {
//如果从stack中没有获取到对象,就创建一个新对象
handle = stack.newHandle();
handle.value = newObject(handle);
}
return (T) handle.value;
}
首先是从ThreadLocal对象中获取本线程的Stack对象,然后从Stack中获取对象,如果没有获取到对象,就创建新对象。这里的逻辑比较简单,再看下Stack的pop方法是如何实现的。
DefaultHandle<T> pop() {
int size = this.size;//获取当前stack的大小
if (size == 0) {
if (!scavenge()) {//如果stack没有存储对象,那么就从WeakOrderQueue中回收对象
return null;
}
size = this.size;//重新获取当前stack的大小
}
//获取之后size自减
size --;
//获取数组的最后一个元素,stack的结构就是先进后出,后进先出
DefaultHandle ret = elements[size];
elements[size] = null;
if (ret.lastRecycledId != ret.recycleId) {
throw new IllegalStateException("recycled multiple times");
}
ret.recycleId = 0;
ret.lastRecycledId = 0;
this.size = size;
return ret;
}
逻辑也不复杂,就是从Stack内部的数组中返回最后一个元素返回,这里有一个方法scavenge(),这个方法比较关键,是当stack中没有元素时,就先尝试执行scavenge方法从WeakOrderQueue中先回收对象到Stack中,后面再详解
了解了获取对象的方法实现之后,再看下回收对象的实现逻辑
对象的回收方法是调用了DefaultHandle的recycle方法,源码如下:
@Override
public void recycle(Object object) {
if (object != value) {
throw new IllegalArgumentException("object does not belong to handle");
}
//直接将当前对象push到stack中
stack.push(this);
}
代码不多,逻辑就是将当前的对象重新push到当前线程的Stack中去,Stack的push方法如下:
void push(DefaultHandle<?> item) {
Thread currentThread = Thread.currentThread();
//判断stack绑定的线程是否的当前的线程
if (threadRef.get() == currentThread) {
//stack绑定的线程就是当前线程,也就是创建对象和回收对象是同一个线程的情况
pushNow(item);
} else {
//stack绑定的线程不是当前线程,也就是创建对象和回收对象不是同一个线程的情况
pushLater(item, currentThread);
}
}
这里的push方法分成了两种情况,一种是回收的线程和创建对象的线程是同一个线程,一种是回收的线程和创建对象的线程不是同一个线程的情况。那就先看同一个线程的情况
private void pushNow(DefaultHandle<?> item) {
//判断当前对象是否已经回收
if ((item.recycleId | item.lastRecycledId) != 0) {
throw new IllegalStateException("recycled already");
}
//设置当前回收ID
item.recycleId = item.lastRecycledId = OWN_THREAD_ID;
//判断当前stack的大小是否已经超过了最大容量
int size = this.size;
if (size >= maxCapacity || dropHandle(item)) {
// Hit the maximum capacity or should drop - drop the possibly youngest object.
return;
}
//如果当前stack的大小等于数组的大小,那么就需要扩容,默认是扩容两倍
if (size == elements.length) {
elements = Arrays.copyOf(elements, min(size << 1, maxCapacity));
}
//设置数组的最后一位为回收的对象
elements[size] = item;
this.size = size + 1;
}
整体逻辑也不复杂,就是将回收的对象存入内部数组的最后一位,之前如果数组满了就进行扩容,默认是扩容两倍
目前为止,单线程使用的情况下的获取和回收基本上流程已经很清楚了,但是在多线程的情况下,其他线程回收了创建对象的线程的对象的时候,需要怎么进行回收呢?创建对象的线程又是怎么将其他线程回收的对象回收到本线程呢?
这里就是涉及到了另一个数据结构,WeakOrderQueue,看名字就能猜到是一个弱引用的有序队列。
static final WeakOrderQueue DUMMY = new WeakOrderQueue();
@SuppressWarnings("serial")
//内部类Link对象,是一个链表存储对象,链表的节点是一个对象数组
private static final class Link extends AtomicInteger {
private final DefaultHandle<?>[] elements = new DefaultHandle[LINK_CAPACITY];
private int readIndex;
private Link next;
}
//指向头Link节点和尾Link节点
private Link head, tail;
//指向同一个stack的下一个WeakOrderQueue
private WeakOrderQueue next;
//当前线程的引用
private final WeakReference<Thread> owner;
//自增的ID
private final int id = ID_GENERATOR.getAndIncrement();
private final AtomicInteger availableSharedCapacity;
WeakOrderQueue的结构如下图示,内部是一个Link的链表,每个Link是一个对象的数组,每个WeakOrderQueue又指向下一个WeakOrderQueue,而这WeakOrderQueue组成的链表是属于同一个Stack的。
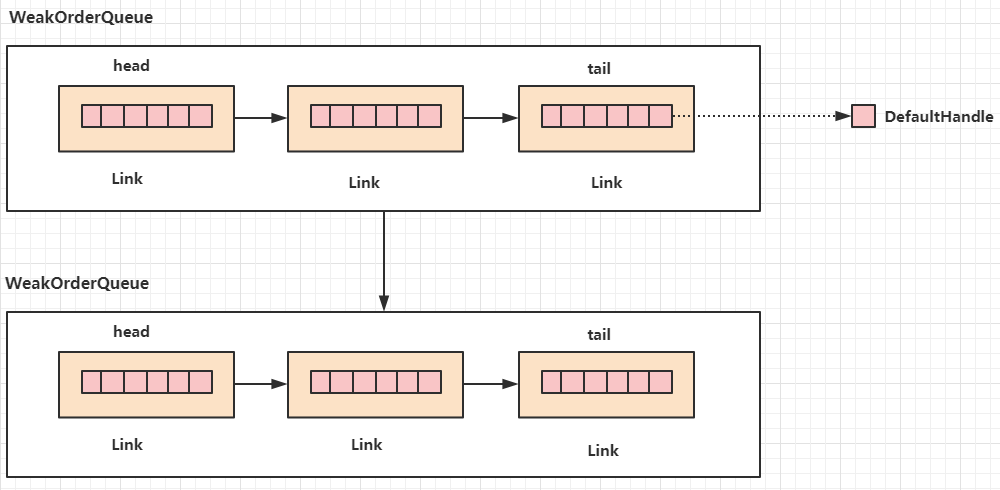
简单点说,如果线程A创建了对象,那么从线程B回收的对象,不是直接回收到线程A的Stack中,而是创建一个WeakOrderQueue,并且将回收的对象放入WeakOrderQueue中,并且将Stack对象的head指向这个WeakOrderQueue,
此时如果线程C先回收线程A的对象,也和线程B一样创建一个WeakOrderQueue,并且将Stack的head执行这个WeakOrderQueue,并且将这个head的next执行原先为head的WeakOrderQueue。所以一个线程的对象池中存储的对象包含
了线程绑定的Stack,还包含了这个Stack指向的WeakOrderQueue链表,这些WeakOrderQueue就是其他线程回收这个线程的对象存储的地方。那么Stack如何使用这些WeakOrderQueue中的对象呢? 答案就是在获取对象的时候执行了scavenge方法,源码如下:
boolean scavenge() {
// continue an existing scavenge, if any
if (scavengeSome()) {
return true;
}
// reset our scavenge cursor
prev = null;
cursor = head;
return false;
}
boolean scavengeSome() {
//上一个WeakOrderQueue引用
WeakOrderQueue prev;
//当前的WeakOrderQueue引用
WeakOrderQueue cursor = this.cursor;
if (cursor == null) {
prev = null;
cursor = head;
if (cursor == null) {
return false;
}
} else {
prev = this.prev;
}
boolean success = false;
do {
//调用WeakOrderQueue的transfer方法转化
if (cursor.transfer(this)) {
success = true;
break;
}
WeakOrderQueue next = cursor.next;
if (cursor.owner.get() == null) {
// If the thread associated with the queue is gone, unlink it, after
// performing a volatile read to confirm there is no data left to collect.
// We never unlink the first queue, as we don't want to synchronize on updating the head.
if (cursor.hasFinalData()) {
for (;;) {
if (cursor.transfer(this)) {
success = true;
} else {
break;
}
}
}
if (prev != null) {
prev.setNext(next);
}
} else {
prev = cursor;
}
cursor = next;
} while (cursor != null && !success);
this.prev = prev;
this.cursor = cursor;
return success;
}
实际就是从head指针开始遍历WeakOrderQueue,调用WeakOrderQueue的transfer方法,源码如下:
boolean transfer(Stack<?> dst) {
Link head = this.head;
if (head == null) {
return false;
}
if (head.readIndex == LINK_CAPACITY) {
if (head.next == null) {
return false;
}
this.head = head = head.next;
}
final int srcStart = head.readIndex;
int srcEnd = head.get();
final int srcSize = srcEnd - srcStart;
if (srcSize == 0) {
return false;
}
final int dstSize = dst.size;
final int expectedCapacity = dstSize + srcSize;
if (expectedCapacity > dst.elements.length) {
final int actualCapacity = dst.increaseCapacity(expectedCapacity);
srcEnd = min(srcStart + actualCapacity - dstSize, srcEnd);
}
if (srcStart != srcEnd) {
final DefaultHandle[] srcElems = head.elements;
final DefaultHandle[] dstElems = dst.elements;
int newDstSize = dstSize;
for (int i = srcStart; i < srcEnd; i++) {
DefaultHandle element = srcElems[i];
if (element.recycleId == 0) {
element.recycleId = element.lastRecycledId;
} else if (element.recycleId != element.lastRecycledId) {
throw new IllegalStateException("recycled already");
}
srcElems[i] = null;
if (dst.dropHandle(element)) {
// Drop the object.
continue;
}
element.stack = dst;
dstElems[newDstSize ++] = element;
}
if (srcEnd == LINK_CAPACITY && head.next != null) {
// Add capacity back as the Link is GCed.
reclaimSpace(LINK_CAPACITY);
this.head = head.next;
}
head.readIndex = srcEnd;
if (dst.size == newDstSize) {
return false;
}
dst.size = newDstSize;
return true;
} else {
// The destination stack is full already.
return false;
}
}
代码较长,大致逻辑就是将WeakOrderQueue的Link中的对象存入Stack的内部数组中,这里有个逻辑是 dropHandle方法
boolean dropHandle(DefaultHandle<?> handle) {
if (!handle.hasBeenRecycled) {
if ((++handleRecycleCount & ratioMask) != 0) {
// Drop the object.
return true;
}
handle.hasBeenRecycled = true;
}
return false;
}
这个方法逻辑是判断当前回收的对象是否回收超过了上限,默认的ratioMask的值为8,也就是如果一个对象回收了8次之后,就直接删除此对象,不对此对象进行回收。
除了Stack和WeakOrderQueue,Recycler内部还在多个地方使用了ThreadLocal的优化版本FastThreadLocal,主要有两个地方使用到了,
一个是FastThreadLocal<Stack>,用于存储每个线程的Stack,还有一个是FastThreadLocal<Map<Stack<?>, WeakOrderQueue>>,用于存储一个Map<Stack,WeakOrderQueue>,但异线程回收对象的时候,从ThreadLocal中获取这个Map,然后根据目标线程的Stack为key获取这个Stack
的WeakOrderQueue,然后将回收的对象存入这个WeakOrderQueue中。
基于Netty包中的Recycler实现的对象池技术详解的更多相关文章
- unix中的线程池技术详解
•线程池就是有一堆已经创建好了的线程,当有新的任务需要处理的时候,就从这个池子里面取一个空闲等待的线程来处理该任务,当处理完成了就再次把该线程放回池中,以供后面的任务使用,当池子里的线程全都处理忙碌状 ...
- Comet技术详解:基于HTTP长连接的Web端实时通信技术
前言 一般来说,Web端即时通讯技术因受限于浏览器的设计限制,一直以来实现起来并不容易,主流的Web端即时通讯方案大致有4种:传统Ajax短轮询.Comet技术.WebSocket技术.SSE(Ser ...
- P2P技术详解(二):P2P中的NAT穿越(打洞)方案详解
1.内容概述 P2P即点对点通信,或称为对等联网,与传统的服务器客户端模式(如下图"P2P结构模型"所示)有着明显的区别,在即时通讯方案中应用广泛(比如IM应用中的实时音视频通信. ...
- 基于OpenCL的深度学习工具:AMD MLP及其使用详解
基于OpenCL的深度学习工具:AMD MLP及其使用详解 http://www.csdn.net/article/2015-08-05/2825390 发表于2015-08-05 16:33| 59 ...
- 转载~kxcfzyk:Linux C语言多线程库Pthread中条件变量的的正确用法逐步详解
Linux C语言多线程库Pthread中条件变量的的正确用法逐步详解 多线程c语言linuxsemaphore条件变量 (本文的读者定位是了解Pthread常用多线程API和Pthread互斥锁 ...
- Node.js中的不安全跳转如何防御详解
Node.js中的不安全跳转如何防御详解 导语: 早年在浏览器大战期间,有远见的Chrome认为要运行现代Web应用,浏览器必须有一个性能非常强劲的Java引擎,于是Google自己开发了一个高性能的 ...
- Python中第三方库Requests库的高级用法详解
Python中第三方库Requests库的高级用法详解 虽然Python的标准库中urllib2模块已经包含了平常我们使用的大多数功能,但是它的API使用起来让人实在感觉不好.它已经不适合现在的时代, ...
- python中日志logging模块的性能及多进程详解
python中日志logging模块的性能及多进程详解 使用Python来写后台任务时,时常需要使用输出日志来记录程序运行的状态,并在发生错误时将错误的详细信息保存下来,以别调试和分析.Python的 ...
- Android中Intent传值与Bundle传值的区别详解
Android中Intent传值与Bundle传值的区别详解 举个例子我现在要从A界面跳转到B界面或者C界面 这样的话 我就需要写2个Intent如果你还要涉及的传值的话 你的Intent就要写两 ...
随机推荐
- Docker 部署 halo 启动时,MySql 连接不上
原因 halo 是部署在 docker 容器内部的,而 MySql 是部署在"宿主机"上的,docker默认的网络模式是bridge,容器内127.0.0.1访问不到的,把网络模式 ...
- java 之 servlet简介
Servlet 是什么? Java Servlet 是运行在 Web 服务器或应用服务器上的程序,它是作为来自 Web 浏览器或其他 HTTP 客户端的请求和 HTTP 服务器上的数据库或应用程序之间 ...
- 标准库shutil
shutil模块是高级的 文件.文件夹.压缩包 处理模块. 下面是关于其中各种方法的使用介绍: 1.shutil.copyfileobj(fsrc, fdst[, length])将文件内容拷贝到另一 ...
- 算法竞赛进阶指南--在单调递增序列a中查找小于等于x的数中最大的一个(即x或x的前驱)
在单调递增序列a中查找<=x的数中最大的一个(即x或x的前驱) while (l < r) { int mid = (l + r + 1) / 2; if (a[mid] <= x) ...
- ACM及各类程序竞赛专业术语
AC (Accepted) 程序通过 WA (Wrong Answer) 错误的答案 PE (Presentation Error) 输出格式错误 RE (Runtime Error) 程序执行错误 ...
- 图论--拓扑排序--HDU-1285确定比赛名次
Problem Description 有N个比赛队(1<=N<=500),编号依次为1,2,3,....,N进行比赛,比赛结束后,裁判委员会要将所有参赛队伍从前往后依次排名,但现在裁判委 ...
- CodeForces - 1245 B - Restricted RPS(贪心)
Codeforces Round #597 (Div. 2) Let nn be a positive integer. Let a,b,ca,b,c be nonnegative integers ...
- HTML 页面跳转的五种方法
H方法TML 页面跳转的五种方法 下面列了五个例子来详细说明,这几个例子的主要功能是:在5秒后,自动跳转到同目录下的hello.html(根据自己需要自行修改)文件.1) html的实现 <he ...
- Python爬虫(二)爬百度贴吧楼主发言
爬取电影吧一个帖子里的所有楼主发言: # python2 # -*- coding: utf-8 -*- import urllib2 import string import re class Ba ...
- 迁移WPF项目到.NET CORE
综述 .NET CORE 3.0开始,桌面端支持WPF了.很多.NET FRAMEWORK的项目已经跑了一阵子了,不是很有必要支持.NET CORE,不过最近用一个程序,为了贯彻一些C# 8的特性,需 ...