sklearn机器学习算法--K近邻
K近邻
构建模型只需要保存训练数据集即可。想要对新数据点做出预测,算法会在训练数据集中找到最近的数据点,也就是它的“最近邻”。
1、K近邻分类
#第三步导入K近邻模型并实例化KN对象
from sklearn.neighbors import KNeighborsClassifier
#其中n_neighbors为近邻数量
clf = KNeighborsClassifier(n_neighbors=3)
#第四步对训练集进行训练
clf.fit(X_train,y_train)
#查看训练集和测试集的精确度
clf.score(X_train,y_train)
#建立一个有一行三列组成的图组,每个图的大小是10×3
fig, axes = plt.subplots(1,3,figsize=(10,3))
for n_neighbors,ax in zip([1,3,9],axes):
#实例化模型对象并对数据进行训练
clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X,y)
mglearn.plots.plot_2d_separator(clf, X, fill=True, eps=0.5, ax=ax, alpha=.4)
mglearn.discrete_scatter(X[:,0],X[:,1],y,ax=ax)
ax.set_title("{} neighbor(s)".format(n_neighbors))
ax.set_xlabel("feature 0")
ax.set_ylabel("feature 1")
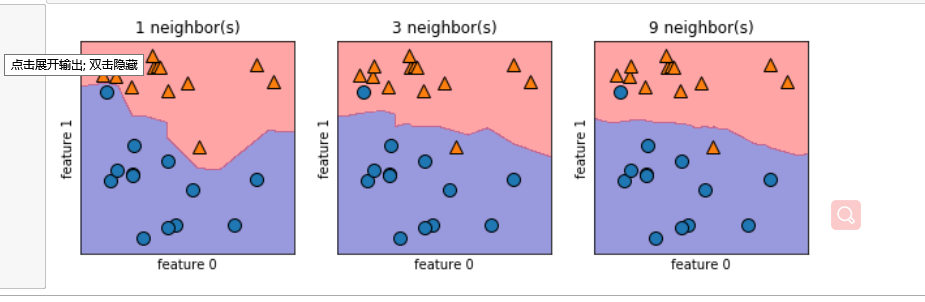
针对乳腺癌数据进行不同近邻的精确度分析
#加载乳腺癌数据
from sklearn.datasets import load_breast_cancer
#提取数据
cancer = load_breast_cancer()
#第一步将数据分为训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(cancer.data,cancer.target,random_state = 0)
#实例化不同近邻的KN对象
neighbors_settings = range(1,11)
training_accuracy = []
test_accuracy = []
for n_neighbors in neighbors_settings:
clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X_train,y_train)
training_accuracy.append(clf.score(X_train,y_train))
test_accuracy.append(clf.score(X_test,y_test))
plt.plot(neighbors_settings,training_accuracy,label='training accuracy')
plt.plot(neighbors_settings,test_accuracy,label='test accuracy')
plt.legend()
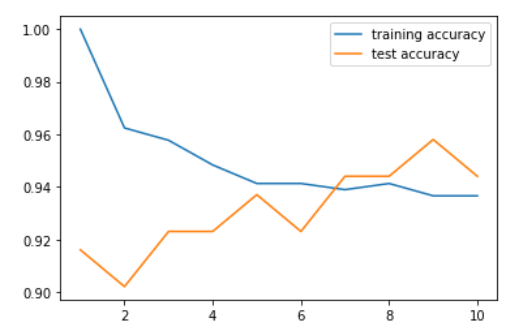
2、K近邻回归
针对wave数据进行K近邻回归演示
#导入wave数据
X,y = mglearn.datasets.make_wave()
#将数据分为训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y, random_state = 0)
#导入KN模型
from sklearn.neighbors import KNeighborsRegressor
#实例化KN模型
reg = KNeighborsRegressor(n_neighbors=3)
#对训练集进行训练
reg.fit(X_train,y_train)
#查看模型的精度
reg.score(X_test,y_test)
#创建一个有一行三列组成的图组,每个图的大小为15×4
fig, axes = plt.subplots(1,3,figsize=(15,4))
#创建1000个数据点,分布在-3和3之间
lines=np.linspace(-3,3,1000).reshape(-1,1)
for n_neighbors, ax in zip([1,3,9],axes):
reg = KNeighborsRegressor(n_neighbors=n_neighbors).fit(X_train,y_train)
ax.plot(lines,reg.predict(lines))
ax.plot(X_train,y_train,'^',c=mglearn.cm2(0),markersize=8)
ax.plot(X_test,y_test,'o',c=mglearn.cm2(1),markersize=8)
ax.set_title('{} neighbor\n train score:{:.2f} test score:{:.2f}'.format(n_neighbors,reg.score(X_train,y_train),
reg.score(X_test,y_test)))
axes[0].legend(['model predictions','training data/target','test data/target'])
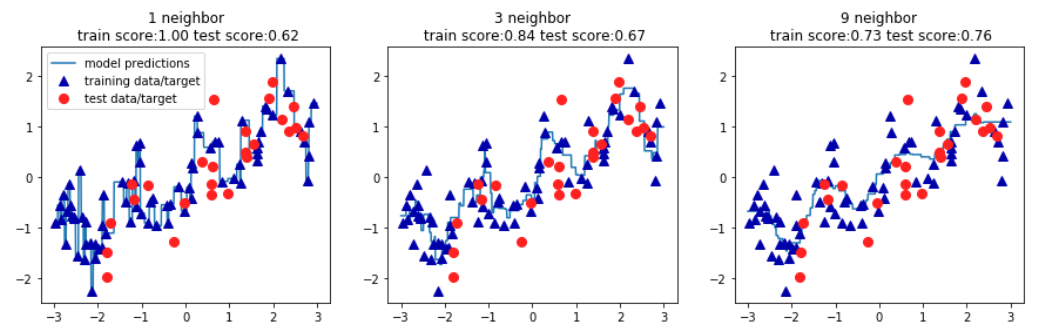
sklearn机器学习算法--K近邻的更多相关文章
- 每日一个机器学习算法——k近邻分类
K近邻很简单. 简而言之,对于未知类的样本,按照某种计算距离找出它在训练集中的k个最近邻,如果k个近邻中多数样本属于哪个类别,就将它判决为那一个类别. 由于采用k投票机制,所以能够减小噪声的影响. 由 ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- 第4章 最基础的分类算法-k近邻算法
思想极度简单 应用数学知识少 效果好(缺点?) 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 distances = [] for x_train in X_train ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 机器学习之K近邻算法
K 近邻 (K-nearest neighbor, KNN) 算法直接作用于带标记的样本,属于有监督的算法.它的核心思想基本上就是 近朱者赤,近墨者黑. 它与其他分类算法最大的不同是,它是一种&quo ...
- 第四十六篇 入门机器学习——kNN - k近邻算法(k-Nearest Neighbors)
No.1. k-近邻算法的特点 No.2. 准备工作,导入类库,准备测试数据 No.3. 构建训练集 No.4. 简单查看一下训练数据集大概是什么样子,借助散点图 No.5. kNN算法的目的是,假如 ...
- python 机器学习(二)分类算法-k近邻算法
一.什么是K近邻算法? 定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. 来源: KNN算法最早是由Cover和Hart提 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
随机推荐
- 04 . Mysql主从复制和读写分离
Mysql AB复制 AB复制又称之为主从复制,用于实现数据同步,实现Mysql的AB复制时,数据库的版本尽量保持一致,如果不能保持一致,最起码从服务器的版本要高于主服务器,但是就无法实现双向复制 ...
- 面试题: hashset如何保证值不会被重复的
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 众所周知,HashSet 的值是不可能被重复的,在业务上经常被用来做数据去重的操作,那么,其内部究竟是怎 ...
- Java实现 LeetCode 342 4的幂
342. 4的幂 给定一个整数 (32 位有符号整数),请编写一个函数来判断它是否是 4 的幂次方. 示例 1: 输入: 16 输出: true 示例 2: 输入: 5 输出: false 进阶: 你 ...
- Java实现 LeetCode70 爬楼梯
70. 爬楼梯 假设你正在爬楼梯.需要 n 阶你才能到达楼顶. 每次你可以爬 1 或 2 个台阶.你有多少种不同的方法可以爬到楼顶呢? 注意:给定 n 是一个正整数. 示例 1: 输入: 2 输出: ...
- java实现串的反转
串的反转 反转串 我们把"cba"称为"abc"的反转串. 求一个串的反转串的方法很多.下面就是其中的一种方法,代码十分简洁(甚至有些神秘),请聪明的你通过给出 ...
- Java实现第八届蓝桥杯字母组串
字母组串 由 A,B,C 这3个字母就可以组成许多串. 比如:"A","AB","ABC","ABA","AA ...
- ubuntu18启动zabbix-agent失败/故障记录
故障现象 ubuntu 16 升级18 之后 安装了zabbix agent 今天突然agent掉了 上去的时候发现 报错: 后来打算-c 启动然后发现 /usr/sbin/zabbix_agentd ...
- android在service中stopself遇到的问题
在service的oncreate中直接调用stopservice停止自己,依然会执行onstartcommand方法后,最后才调用ondestory方法
- 源码分析 | 手写mybait-spring核心功能(干货好文一次学会工厂bean、类代理、bean注册的使用)
作者:小傅哥 博客:https://bugstack.cn - 汇总系列原创专题文章 沉淀.分享.成长,让自己和他人都能有所收获! 一.前言介绍 一个知识点的学习过程基本分为:运行helloworld ...
- Copy-on-write + Proxy = ?
一.简介 Immer (German for: always) is a tiny package that allows you to work with immutable state in a ...