入门大数据---基于Zookeeper搭建Spark高可用集群
一、集群规划
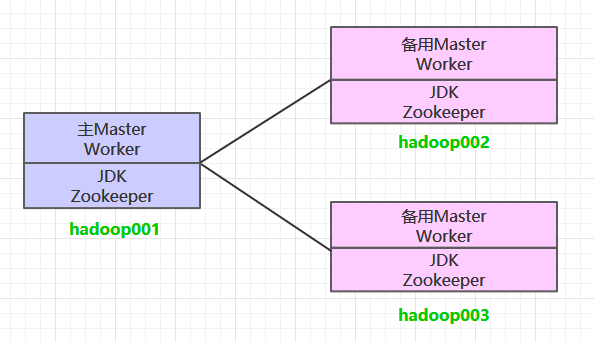
这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop002 和 hadoop003 上分别部署备用的 Master 服务,Master 服务由 Zookeeper 集群进行协调管理,如果主 Master 不可用,则备用 Master 会成为新的主 Master。
二、前置条件
搭建 Spark 集群前,需要保证 JDK 环境、Zookeeper 集群和 Hadoop 集群已经搭建,相关步骤可以参阅:
三、Spark集群搭建
3.1 下载解压
下载所需版本的 Spark,官网下载地址:http://spark.apache.org/downloads.html
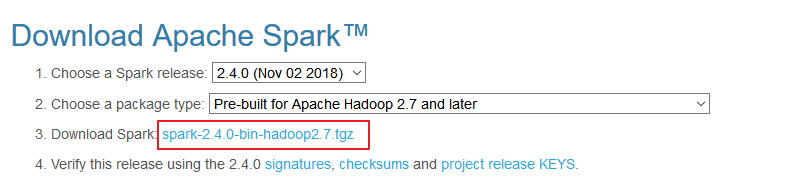
下载后进行解压:
# tar -zxvf spark-2.2.3-bin-hadoop2.6.tgz
3.2 配置环境变量
# vim /etc/profile
添加环境变量:
export SPARK_HOME=/usr/app/spark-2.2.3-bin-hadoop2.6
export PATH=${SPARK_HOME}/bin:$PATH
使得配置的环境变量立即生效:
# source /etc/profile
3.3 集群配置
进入 ${SPARK_HOME}/conf 目录,拷贝配置样本进行修改:
1. spark-env.sh
cp spark-env.sh.template spark-env.sh
# 配置JDK安装位置
JAVA_HOME=/usr/java/jdk1.8.0_201
# 配置hadoop配置文件的位置
HADOOP_CONF_DIR=/usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop
# 配置zookeeper地址
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop001:2181,hadoop002:2181,hadoop003:2181 -Dspark.deploy.zookeeper.dir=/spark"
2. slaves
cp slaves.template slaves
配置所有 Woker 节点的位置:
hadoop001
hadoop002
hadoop003
3.4 安装包分发
将 Spark 的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下 Spark 的环境变量。
scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop002:usr/app/
scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop003:usr/app/
四、启动集群
4.1 启动ZooKeeper集群
分别到三台服务器上启动 ZooKeeper 服务:
zkServer.sh start
4.2 启动Hadoop集群
# 启动dfs服务
start-dfs.sh
# 启动yarn服务
start-yarn.sh
4.3 启动Spark集群
进入 hadoop001 的 ${SPARK_HOME}/sbin 目录下,执行下面命令启动集群。执行命令后,会在 hadoop001 上启动 Maser 服务,会在 slaves 配置文件中配置的所有节点上启动 Worker 服务。
start-all.sh
分别在 hadoop002 和 hadoop003 上执行下面的命令,启动备用的 Master 服务:
# ${SPARK_HOME}/sbin 下执行
start-master.sh
4.4 查看服务
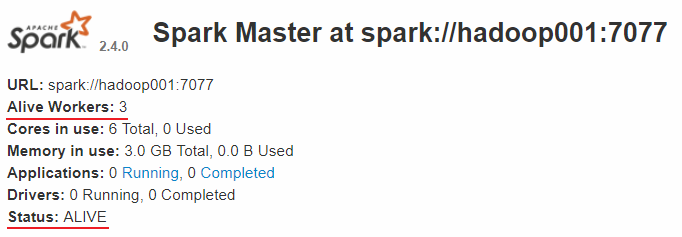
查看 Spark 的 Web-UI 页面,端口为 8080。此时可以看到 hadoop001 上的 Master 节点处于 ALIVE 状态,并有 3 个可用的 Worker 节点。
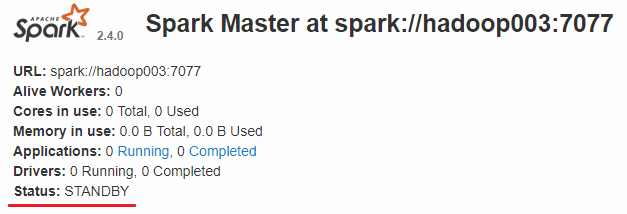
而 hadoop002 和 hadoop003 上的 Master 节点均处于 STANDBY 状态,没有可用的 Worker 节点。

五、验证集群高可用
此时可以使用 kill 命令杀死 hadoop001 上的 Master 进程,此时备用 Master 会中会有一个再次成为 主 Master,我这里是 hadoop002,可以看到 hadoop2 上的 Master 经过 RECOVERING 后成为了新的主 Master,并且获得了全部可以用的 Workers。

Hadoop002 上的 Master 成为主 Master,并获得了全部可以用的 Workers。
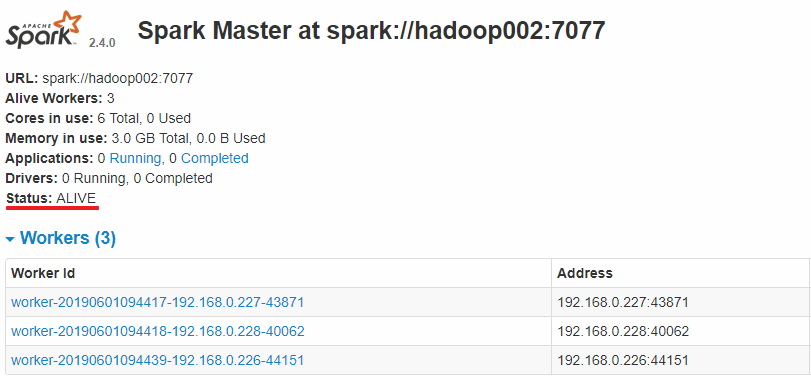
此时如果你再在 hadoop001 上使用 start-master.sh 启动 Master 服务,那么其会作为备用 Master 存在。
六、提交作业
和单机环境下的提交到 Yarn 上的命令完全一致,这里以 Spark 内置的计算 Pi 的样例程序为例,提交命令如下:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--executor-memory 1G \
--num-executors 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100
入门大数据---基于Zookeeper搭建Spark高可用集群的更多相关文章
- 入门大数据---基于Zookeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 基于 ZooKeeper 搭建 Spark 高可用集群
一.集群规划 二.前置条件 三.Spark集群搭建 3.1 下载解压 3.2 配置环境变量 3.3 集群配置 3.4 安装包分发 四.启 ...
- Spark学习之路(七)—— 基于ZooKeeper搭建Spark高可用集群
一.集群规划 这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop00 ...
- Spark 系列(七)—— 基于 ZooKeeper 搭建 Spark 高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 二.集群规划 三.前置条件 四.集群配置 五.启动集群 六.查看集群 七.集群的二次启动 一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS ...
- Hadoop 学习之路(八)—— 基于ZooKeeper搭建Hadoop高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Hadoop 系列(八)—— 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Kafka —— 基于 ZooKeeper 搭建 Kafka 高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本Zookeep ...
- Kafka 学习之路(二)—— 基于ZooKeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本Zookeep ...
随机推荐
- Spring Boot笔记(六) springboot 集成 timer 定时任务
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 1.创建具体要执行的任务类: package com.example.poiutis.timer; im ...
- link和@import引入css的区别
@import是在CSS2.1提出的,低版本的浏览器不支持.link支持良好: link引用CSS时,在页面载入时同时加载: @import需要页面网页完全载入以后加载.如果页面内容过多,会产生不好的 ...
- Java实现 LeetCode 732 我的日程安排表 III(暴力 || 二叉树)
732. 我的日程安排表 III 实现一个 MyCalendar 类来存放你的日程安排,你可以一直添加新的日程安排. MyCalendar 有一个 book(int start, int end)方法 ...
- Java实现 LeetCode 713 乘积小于K的子数组(子集数量+双指针)
713. 乘积小于K的子数组 给定一个正整数数组 nums. 找出该数组内乘积小于 k 的连续的子数组的个数. 示例 1: 输入: nums = [10,5,2,6], k = 100 输出: 8 解 ...
- Java实现 蓝桥杯VIP 算法提高 大数加法
算法提高 大数加法 时间限制:1.0s 内存限制:256.0MB 问题描述 输入两个正整数a,b,输出a+b的值. 输入格式 两行,第一行a,第二行b.a和b的长度均小于1000位. 输出格式 一行, ...
- java关键字final用法详解
final关键字在java中也是属于比较常用的一种,因此也算得上是一个比较重要的关键字,有必要对它进行深入的学习. 一.定义:用来说明最终属性,表明一个类不能派生出子类,或者成员方法不能被覆盖,或者成 ...
- postman接口超时设置,用于debug等断点调试
Settings->General->Request Timeout in ms(0 for infinity):设置请求超时的时间,默认为0
- MySQL 8.0 yum安装和配置
MySQL 8.0 centos7.5 x86_64 一.yum安装 1.先卸载机器和mysql有关的东西,有的安装了mariab-lib,会对安装有干扰,卸载了它. [root@localhost ...
- 如何优雅地停止 Spring Boot 应用?
首先来介绍下什么是优雅地停止,简而言之,就是对应用进程发送停止指令之后,能保证正在执行的业务操作不受影响,可以继续完成已有请求的处理,但是停止接受新请求. 在 Spring Boot 2.3 中增加了 ...
- 新Mac电脑pycharm爬虫环境安装与配置
*需要安装的软件:Pycharm.Squel pro.mysql.redis等. 1.下载安装pycharm. 2.下载安装item2. 3.安装brew:'ruby -e "$(curl ...