Scikit-learn之特征抽取
一.安装包
pip install Scikit-learn
二.字典特征抽取
1.字典特征抽取
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#author tom from sklearn.feature_extraction import DictVectorizer l=[
{'city':'北京','temparatue':20},
{'city':'深圳','temparatue':40},
{'city':'广州','temparatue':60},
] def dictvec():
"""
字典数据抽取
:return:
"""
#实例化对象
dic=DictVectorizer()
#调用feature,参数是字典,或者把字典放置于可迭代对象中,比如说列表
data=dic.fit_transform(l)
print(dic.get_feature_names())
print(data) if __name__ == '__main__':
dictvec()
结果:(sparse矩阵,这样边读边处理,有助于节约内存)
['city=北京', 'city=广州', 'city=深圳', 'temparatue']
(0, 0) 1.0
(0, 3) 20.0
(1, 2) 1.0
(1, 3) 40.0
(2, 1) 1.0
(2, 3) 60.0
改变一下实话对象的参数(sparse默认为True,我们把他改为False)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#author tom from sklearn.feature_extraction import DictVectorizer l=[
{'city':'北京','temparatue':20},
{'city':'深圳','temparatue':40},
{'city':'广州','temparatue':60},
] def dictvec():
"""
字典数据抽取
:return:
"""
#实例化对象
dic=DictVectorizer(sparse=False)
#调用feature,参数是字典,或者把字典放置于可迭代对象中,比如说列表
data=dic.fit_transform(l)
print(dic.get_feature_names())
print(data) if __name__ == '__main__':
dictvec()
结果:(ndaarray或者数组) 这个我们成为one-hot编码
['city=北京', 'city=广州', 'city=深圳', 'temparatue']
[[ 1. 0. 0. 20.]
[ 0. 0. 1. 40.]
[ 0. 1. 0. 60.]]
2.关于字典特征抽取总结
DictVectorizer.fit_transform(x)
- x:字典或者包含字典的迭代器
- 返回值:sparse矩阵
- DictVectorizer.inverse_transform(X)
- X:array数组或者sparse矩阵
返回值:转换之前的数据格式
- DictVectorizer.get_feature_names()
- 返回类别特征
- DictVectorizer.transform(X)
- 按照原先的标准转换
- 按照原先的标准转换
3.作用
把关于分类的特征值进行特征化以区分
三.文本特征抽取
1.文本特征抽取
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#author tom from sklearn.feature_extraction.text import CountVectorizer
l=['life is short ,i like python','life is long,i dislike python'] def countvec():
"""
对文本数据进行特征值化
:return:
"""
count=CountVectorizer()
data=count.fit_transform(l)
print(count.get_feature_names())
print(data)
print('-----分割线-----------')
#文本没有sparse参数,只能调用toarray()方法转换成array
print(data.toarray()) if __name__ == '__main__':
countvec()
结果:
['dislike', 'is', 'life', 'like', 'long', 'python', 'short']
(0, 2) 1
(0, 1) 1
(0, 6) 1
(0, 3) 1
(0, 5) 1
(1, 2) 1
(1, 1) 1
(1, 5) 1
(1, 4) 1
(1, 0) 1
-----分割线-----------
[[0 1 1 1 0 1 1]
[1 1 1 0 1 1 0]]

再来看一下中文的特征抽取
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#author tom from sklearn.feature_extraction.text import CountVectorizer
l=['life is short ,i like python','life is long,i dislike python']
l1=['人生苦短,我喜欢python','人生漫长,我不用python']
def countvec():
"""
对文本数据进行特征值化
:return:
"""
count=CountVectorizer()
data=count.fit_transform(l1)
print(count.get_feature_names())
# print(data)
print('-----分割线-----------')
#文本没有sparse参数,只能调用toarray()方法转换成array
print(data.toarray()) if __name__ == '__main__':
countvec()
结果:
['人生漫长', '人生苦短', '我不用python', '我喜欢python']
-----分割线-----------
[[0 1 0 1]
[1 0 1 0]]
并没有太大的实际意义,所以我们手动对中文分词看看
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#author tom from sklearn.feature_extraction.text import CountVectorizer
l=['life is short ,i like python','life is long,i dislike python']
l1=['人生 苦短,我 喜欢 python','人生 漫长,我 不用 python']
def countvec():
"""
对文本数据进行特征值化
:return:
"""
count=CountVectorizer()
data=count.fit_transform(l1)
print(count.get_feature_names())
# print(data)
print('-----分割线-----------')
#文本没有sparse参数,只能调用toarray()方法转换成array
print(data.toarray()) if __name__ == '__main__':
countvec()
结果:
['python', '不用', '人生', '喜欢', '漫长', '苦短']
-----分割线-----------
[[1 0 1 1 0 1]
[1 1 1 0 1 0]]
所以,我们需要借助分词工具,这边推荐结巴
pip install jieba
实例:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#author tom
import jieba
from sklearn.feature_extraction.text import CountVectorizer def cutWord():
"""
利用结巴分词
:return: 分词后的字符串
"""
#切词
con1=jieba.cut('拥有万卷书的穷书生,并不想去和百万富翁交换钻石或股票。满足于田园生活的人也并不艳羡任何学者的荣誉头衔,或高官厚禄。')
con2=jieba.cut('苦乐全凭自已判断,这和客观环境并不一定有直接关系,正如一个不爱珠宝的女人,即使置身在极其重视虚荣的环境,也无伤她的自尊。')
con3=jieba.cut('人的一生常处于抉择之中,如:念哪一间大学?选哪一种职业?娶哪一种女子?……等等伤脑筋的事情。一个人抉择力的有无,可以显示其人格成熟与否。')
print(con1)
print(con2)
print(con3)
#转换成列表
content1=list(con1)
content2=list(con2)
content3=list(con3)
print(content1)
print(content2)
print(content3)
#把列表拼接成字符串(分词后的)
c1=' '.join(content1)
c2=' '.join(content2)
c3=' '.join(content3)
print(c1)
print(c2)
print(c3)
return c1,c2,c3 def chines_vec():
c1,c2,c3=cutWord()
count=CountVectorizer()
data=count.fit_transform([c1,c2,c3])
print(count.get_feature_names())
print(data.toarray())
if __name__ == '__main__':
chines_vec()
结果:
['一个', '一生', '一种', '一间', '万卷书', '不想', '不爱', '与否', '之中', '事情', '交换', '人格', '任何', '伤脑筋', '关系', '判断', '即使', '可以', '处于', '大学', '头衔', '女人', '女子', '学者', '客观', '并不一定', '成熟', '抉择', '拥有', '无伤', '显示', '有无', '极其', '正如', '满足', '环境', '珠宝', '田园生活', '百万富翁', '直接', '穷书生', '等等', '置身', '职业', '股票', '自尊', '自已', '艳羡', '苦乐', '荣誉', '虚荣', '重视', '钻石', '高官厚禄']
[[0 0 0 0 1 1 0 0 0 0 1 0 1 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 1 0 0 0 0 0 1 0
0 1 1 0 1 0 0 0 1 0 0 1 0 1 0 0 1 1]
[1 0 0 0 0 0 1 0 0 0 0 0 0 0 1 1 1 0 0 0 0 1 0 0 1 1 0 0 0 1 0 0 1 1 0 2
1 0 0 1 0 0 1 0 0 1 1 0 1 0 1 1 0 0]
[1 1 2 1 0 0 0 1 1 1 0 1 0 1 0 0 0 1 1 1 0 0 1 0 0 0 1 2 0 0 1 1 0 0 0 0
0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0]]
2.文本特征抽取的另一种方法TfidfVectorizer
把上面的列子改一下
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#author tom
import jieba
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer def cutWord():
"""
利用结巴分词
:return: 分词后的字符串
"""
#切词
con1=jieba.cut('拥有万卷书的穷书生,并不想去和百万富翁交换钻石或股票。满足于田园生活的人也并不艳羡任何学者的荣誉头衔,或高官厚禄。')
con2=jieba.cut('苦乐全凭自已判断,这和客观环境并不一定有直接关系,正如一个不爱珠宝的女人,即使置身在极其重视虚荣的环境,也无伤她的自尊。')
con3=jieba.cut('人的一生常处于抉择之中,如:念哪一间大学?选哪一种职业?娶哪一种女子?……等等伤脑筋的事情。一个人抉择力的有无,可以显示其人格成熟与否。')
print(con1)
print(con2)
print(con3)
#转换成列表
content1=list(con1)
content2=list(con2)
content3=list(con3)
print(content1)
print(content2)
print(content3)
#把列表拼接成字符串(分词后的)
c1=' '.join(content1)
c2=' '.join(content2)
c3=' '.join(content3)
print(c1)
print(c2)
print(c3)
return c1,c2,c3 def chines_vec():
c1,c2,c3=cutWord()
# count=CountVectorizer()
tf=TfidfVectorizer()
data=tf.fit_transform([c1,c2,c3])
print(tf.get_feature_names())
print(data.toarray())
if __name__ == '__main__':
chines_vec()
结果:(值越高越重要,可以作为分类的依据)
['一个', '一生', '一种', '一间', '万卷书', '不想', '不爱', '与否', '之中', '事情', '交换', '人格', '任何', '伤脑筋', '关系', '判断', '即使', '可以', '处于', '大学', '头衔', '女人', '女子', '学者', '客观', '并不一定', '成熟', '抉择', '拥有', '无伤', '显示', '有无', '极其', '正如', '满足', '环境', '珠宝', '田园生活', '百万富翁', '直接', '穷书生', '等等', '置身', '职业', '股票', '自尊', '自已', '艳羡', '苦乐', '荣誉', '虚荣', '重视', '钻石', '高官厚禄']
[[0. 0. 0. 0. 0.25 0.25
0. 0. 0. 0. 0.25 0.
0.25 0. 0. 0. 0. 0.
0. 0. 0.25 0. 0. 0.25
0. 0. 0. 0. 0.25 0.
0. 0. 0. 0. 0.25 0.
0. 0.25 0.25 0. 0.25 0.
0. 0. 0.25 0. 0. 0.25
0. 0.25 0. 0. 0.25 0.25 ]
[0.16005431 0. 0. 0. 0. 0.
0.21045218 0. 0. 0. 0. 0.
0. 0. 0.21045218 0.21045218 0.21045218 0.
0. 0. 0. 0.21045218 0. 0.
0.21045218 0.21045218 0. 0. 0. 0.21045218
0. 0. 0.21045218 0.21045218 0. 0.42090436
0.21045218 0. 0. 0.21045218 0. 0.
0.21045218 0. 0. 0.21045218 0.21045218 0.
0.21045218 0. 0.21045218 0.21045218 0. 0. ]
[0.15340416 0.20170804 0.40341607 0.20170804 0. 0.
0. 0.20170804 0.20170804 0.20170804 0. 0.20170804
0. 0.20170804 0. 0. 0. 0.20170804
0.20170804 0.20170804 0. 0. 0.20170804 0.
0. 0. 0.20170804 0.40341607 0. 0.
0.20170804 0.20170804 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.20170804
0. 0.20170804 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. ]]
解读:TfidfVectorizer

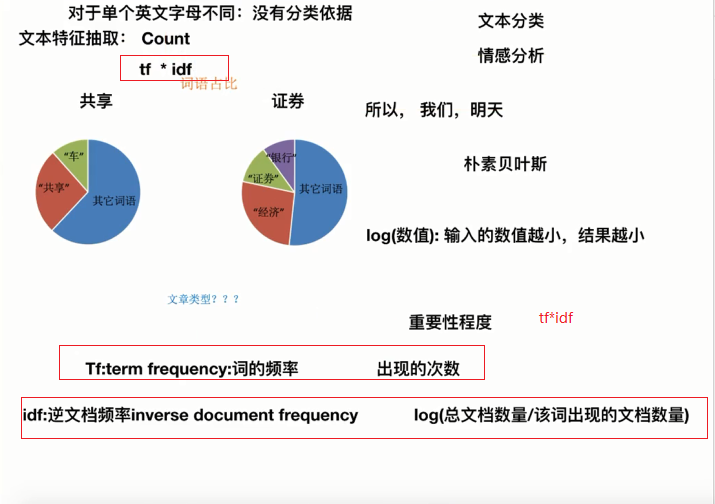
3.文本特征的作用
- 文本分类
- 情感分析
- 单个英文字母,单个汉字不纳入统计,没有意义
Scikit-learn之特征抽取的更多相关文章
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- Scikit Learn
Scikit Learn Scikit-Learn简称sklearn,基于 Python 语言的,简单高效的数据挖掘和数据分析工具,建立在 NumPy,SciPy 和 matplotlib 上.
- Linear Regression with Scikit Learn
Before you read This is a demo or practice about how to use Simple-Linear-Regression in scikit-lear ...
- 如何使用scikit—learn处理文本数据
答案在这里:http://www.tuicool.com/articles/U3uiiu http://scikit-learn.org/stable/modules/feature_extracti ...
- Query意图分析:记一次完整的机器学习过程(scikit learn library学习笔记)
所谓学习问题,是指观察由n个样本组成的集合,并根据这些数据来预测未知数据的性质. 学习任务(一个二分类问题): 区分一个普通的互联网检索Query是否具有某个垂直领域的意图.假设现在有一个O2O领域的 ...
- 机器学习框架Scikit Learn的学习
一 安装 安装pip 代码如下:# wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=83 ...
- Python第三方库(模块)"scikit learn"以及其他库的安装
scikit-learn是一个用于机器学习的 Python 模块. 其主页:http://scikit-learn.org/stable/. GitHub地址: https://github.com/ ...
随机推荐
- mysql 索引和视图
第五节:创建索引5.1 创建表的时候创建索引 CREATE TABLE 表名(属性名数据类型[完整性约束条件], 属性名数据类型[完整性约束条件], .... 属性名数据类型 [UNIQUE | FU ...
- [转]cookie 和 session
原文:https://github.com/alsotang/node-lessons/tree/master/lesson16 读别人源码教程的时候,看到了这个,觉得写的很透彻,转. 众所周知,HT ...
- Service层在MVC框架中的意义和职责
https://blog.csdn.net/u012562943/article/details/53462157 mvc框架由model,view,controller组成,执行流程一般是:在con ...
- 吴裕雄--python学习笔记:通过sqlite3 进行文字界面学生管理
import sqlite3 conn = sqlite3.connect('E:\\student.db') print("Opened database successfully&quo ...
- Java 内部类(成员内部类、局部内部类、静态内部类,匿名内部类)
一.什么是内部类? 内部类是指在一个外部类的内部再定义一个类.内部类作为外部类的一个成员,并且依附于外部类而存在的.内部类可为静态,可用protected和private修饰(而外部类只能使用publ ...
- idea如何使用git
1.安装好git(我下载的2.23.0版本百度网盘分享) 提取码 7ie1 2.配置git环境变量 Path 路径是你安装的git 目录下的bin目录 安装好后窗口命令输入git 可以测 ...
- xshell 常用命令1
date命令 date命令是显示或设置系统时间与日期. 很多shell脚本里面需要打印不同格式的时间或日期,以及要根据时间和日期执行操作.延时通常用于脚本执行过程中提供一段等待的时间.日期可以以多种格 ...
- MyBatis连接MySQL8配置
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</a ...
- 本地开启https服务
### ##自签名证书 ##配置Apache服务器SSL ##自己作为CA签发证书 ###这里是OpenSSL和HTTPS的介绍 OpenSSL HTTPS 开启HTTPS配置前提是已在Mac上搭建A ...
- 编写高质量 Objective-C 代码
第一章 熟悉 Objective-C 第一条:了解 Objective-C 起源 Objective-C 是 C 语言动态性扩充.使用"消息结构"而非"函数调用" ...