signals function|KNN|SVM|average linkage|Complete linkage|single linkage
生物医疗大数据
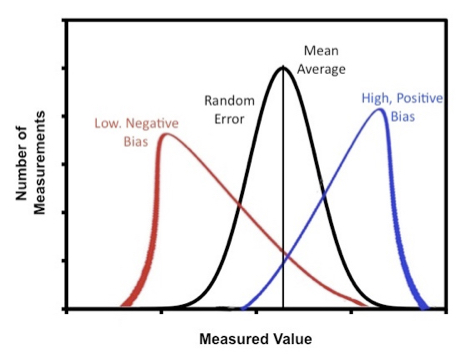
存在系统误差使得估计量有偏,如下图红色和蓝色图形,存在随机误差使得估计量并不是同一个值,如图中除去期望之外的曲线值,为了控制随机抽样造成的误差,可以使用p-value决定是否服从假设检验,判断两个变量之间相关性的有无。
相关系数:该系数广泛用于度量两个变量之间的线性相关程度。
建立模型:
技术种类:线性模型&机器学习模型
按输出数据分类:监督学习模型&非监督学习模型
Average linkage demo

第一个矩阵是原始数据,单未知数据结构,通过average linkage方法结倒推得到其数据结构,即把数据展开了。主要步骤是找到Smallest distance(因为此两者之间的关系最简单),将距离均值作为到中间未知的距离(因为average linkage中的average决定的),随后以此类推。
除去average linkage方法之外还有Max:Complete linkage&min:single linkage。
对于classify来说,有data-base的KNN:K取值重要决定学习规则的范围;和Model-oriented其最重要的是找到区分多类数据的曲线,该曲线的函数思路可有以下三种:
1.高次项SVM(升维)
2.用傅里叶变换用三角函数凑不平滑曲线
3.signals function源自泰勒展开,通过将signals function加权得到划分曲线,这也是神经网络模型的基础
signals function|KNN|SVM|average linkage|Complete linkage|single linkage的更多相关文章
- 各常用分类算法的优缺点总结:DT/ANN/KNN/SVM/GA/Bayes/Adaboosting/Rocchio
1决策树(Decision Trees)的优缺点 决策树的优点: 一. 决策树易于理解和解释.人们在通过解释后都有能力去理解决策树所表达的意义. 二. 对于决策树,数据的准备往往是简单或者是不必要的. ...
- KNN算法的实现(R语言)
一 . K-近邻算法(KNN)概述 最简单最初级的分类器是将全部的训练数据所对应的类别都记录下来,当测试对象的属性和某个训练对象的属性完全匹配时,便可以对其进行分类.但是怎么可能所有测试对象都会找到 ...
- Adding New Functions to MySQL(User-Defined Function Interface UDF、Native Function)
catalog . How to Add New Functions to MySQL . Features of the User-Defined Function Interface . User ...
- 加载状态为complete时移除loading效果
一.JS代码: //获取浏览器页面可见高度和宽度 var _PageHeight = document.documentElement.clientHeight, _PageWidth = docum ...
- Stanford机器学习---第八讲. 支持向量机SVM
原文: http://blog.csdn.net/abcjennifer/article/details/7849812 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回 ...
- Ajax之 beforeSend和complete longind制作
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 15.0px Consolas; min-height: 18.0px } p.p2 { margin: 0 ...
- [RxJS] Observables can complete
The Observer object has the functions next() and error(). In this lesson we will see the other (and ...
- window.onload,<body onload="function()">, document.onreadystatechange, httpRequest.onreadystatechang
部分内容参考:http://www.aspbc.com/tech/showtech.asp?id=1256 在开发的过程中,经常使用window.onload和body onload两种,很少使用do ...
- KNN算法[分类算法]
kNN(k-近邻)分类算法的实现 (1) 简介: (2)算法描述: (3) <?php /* *KNN K-近邻方法(分类算法的实现) */ /* *把.txt中的内容读到数组中保存,$file ...
随机推荐
- RedHat6.5升级内核
redhat6.5 升级内核 1.导入key rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org 2.安装elrepo的yum源 rp ...
- PHP实现快速排序算法相关案例
<?php /** * 快速排序 --主要运用递归, 先把一个数找准位置,然后再递归把左右两边的数都找准位置 */ function QSort($a= []){ $nCount = count ...
- ZJNU 1196 - 三阶魔方【模拟题】——高级
大模拟,空想很容易把面和面之间的关系搞混 所以这时候需要自己找一个正方体(实在不行长方体代替)跟着图把每个面正方向标出来 然后模拟6种操作分别会对哪些块进行操作 对于储存数据的想法是,对输入输出进行分 ...
- SMO算法--SVM(3)
SMO算法--SVM(3) 利用SMO算法解决这个问题: SMO算法的基本思路: SMO算法是一种启发式的算法(别管启发式这个术语, 感兴趣可了解), 如果所有变量的解都满足最优化的KKT条件, 那么 ...
- memcached安装使用相关-php
1.windows下面: 为什么memcache官方没有for windows的版本下载地址,现在怎么办? https://segmentfault.com/q/1010000002219198 32 ...
- 8.windows-oracle实战第八课 --管理权限和角色
权限: 如果要执行某种特定的数据库操作,就要赋予系统的权限: 如果要执行访问其他方案的对象,就要赋予对象的权限. 1.创建ken和tom用户 create user ken ide ...
- kaggle——NFL Big Data Bowl 2020 Official Starter Notebook
Introduction In this competition you will predict how many yards a team will gain on a rushing play ...
- StartDT AI Lab | 需求预测引擎如何助力线下零售业降本增效?
在当下经济明显进入存量博弈的阶段,大到各经济体,小到企业,粗放的增长模式已不适宜持续,以往高增长的时代已经成为过去,亟需通过变革发掘新的增长点.对于竞争激烈的线下零售行业而言,则更需如此. 零售行业一 ...
- D. New Year and Conference(区间交,线段树)
题:https://codeforces.com/contest/1284/problem/D 题意:给定n个1对的时间断,我是这么理解的,甲去参加a时间段的讲座,乙去参加b时间段的讲座,然后若这n对 ...
- 学习LCA( 最近公共祖先·二)
http://poj.org/problem?id=1986 离线找u,v之间的最小距离(理解推荐) #include<iostream> #include<cstring> ...