Python基础 | pandas中dataframe的整合与形变(merge & reshape)
本文示例数据下载,密码:vwy3
import pandas as pd# 数据是之前在cnblog上抓取的部分文章信息df = pd.read_csv('./data/SQL测试用数据_20200325.csv',encoding='utf-8')# 为了后续演示,抽样生成两个数据集df1 = df.sample(n=500,random_state=123)df2 = df.sample(n=600,random_state=234)# 保证有较多的交集# 比例抽样是有顺序的,不加random_state,那么两个数据集是一样的
行的union
pd.concat
pd.concat主要参数说明:
- 要合并的dataframe,可以用
[]进行包裹,e.g.[df1,df2,df3]; - axis=0,axis是拼接的方向,0代表行,1代表列,不过很少用pd.concat来做列的join
- join='outer'
- ignore_index: bool = False,看是否需要重置index
如果要达到union all的效果,那么要拼接的多个dataframe,必须:
- 列名名称及顺序都需要保持一致
- 每列的数据类型要对应
如果列名不一致就会产生新的列
如果数据类型不一致,不一定报错,要看具体的兼容场景
df2.columns
输出:
Index(['href', 'title', 'create_time', 'read_cnt', 'blog_name', 'date', 'weekday', 'hour'], dtype='object')
# 这里故意修改下第2列的名称df2.columns = ['href', 'title_2', 'create_time', 'read_cnt', 'blog_name', 'date','weekday', 'hour']print(df1.shape,df2.shape)# inner方法将无法配对的列删除# 拼接的方向,默认是就行(axis=0)df_m = pd.concat([df1,df2],axis=0,join='inner')print(df_m.shape)
输出:
(500, 8) (600, 8)
(1100, 7)
# 查看去重后的数据集大小df_m.drop_duplicates(subset='href').shape
输出:
(849, 7)
df.append
和pd.concat方法的区别:
- append只能做行的union
- append方法是outer join
相同点:
- append可以支持多个dataframe的union
- append大致等同于
pd.concat([df1,df2],axis=0,join='outer')
df1.append(df2).shape
输出:
(1100, 9)
df1.append([df2,df2]).shape
输出:
(1700, 9)
列的join
pd.concat
pd.concat也可以做join,不过关联的字段不是列的值,而是index
也因为是基于index的关联,所以pd.concat可以对超过2个以上的dataframe做join操作
# 按列拼接,设置axis=1# inner joinprint(df1.shape,df2.shape)df_m_c = pd.concat([df1,df2], axis=1, join='inner')print(df_m_c.shape)
输出:
(500, 8) (600, 8)
(251, 16)
这里是251行,可以取两个dataframe的index然后求交集看下
set1 = set(df1.index)set2 = set(df2.index)set_join = set1.intersection(set2)print(len(set1), len(set2), len(set_join))
输出:
500 600 251
pd.merge
pd.merge主要参数说明:
- left, join操作左侧的那一个dataframe
- right, join操作左侧的那一个dataframe, merge方法只能对2个dataframe做join
- how: join方式,默认是inner,str = 'inner'
- on=None 关联的字段,如果两个dataframe关联字段一样时,设置on就行,不用管left_on,right_on
- left_on=None 左表的关联字段
- right_on=None 右表的关联字段,如果两个dataframe关联字段名称不一样的时候就设置左右字段
- suffixes=('_x', '_y'), join后给左右表字段加的前缀,除关联字段外
print(df1.shape,df2.shape)df_m = pd.merge(left=df1, right=df2\,how='inner'\,on=['href','blog_name'])print(df_m.shape)
输出:
(500, 8) (600, 8)
(251, 14)
print(df1.shape,df2.shape)df_m = pd.merge(left=df1, right=df2\,how='inner'\,left_on = 'href',right_on='href')print(df_m.shape)
输出:
(500, 8) (600, 8)
(251, 15)
# 对比下不同join模式的区别print(df1.shape,df2.shape)# inner joindf_inner = pd.merge(left=df1, right=df2\,how='inner'\,on=['href','blog_name'])# full outer joindf_full_outer = pd.merge(left=df1, right=df2\,how='outer'\,on=['href','blog_name'])# left outer joindf_left_outer = pd.merge(left=df1, right=df2\,how='left'\,on=['href','blog_name'])# right outer joindf_right_outer = pd.merge(left=df1, right=df2\,how='right'\,on=['href','blog_name'])print('inner join 左表∩右表:' + str(df_inner.shape))print('full outer join 左表∪右表:' + str(df_full_outer.shape))print('left outer join 左表包含右表:' + str(df_left_outer.shape))print('right outer join 右表包含左表:' + str(df_right_outer.shape))
输出:
(500, 8) (600, 8)
inner join 左表∩右表:(251, 14)
full outer join 左表∪右表:(849, 14)
left outer join 左表包含右表:(500, 14)
right outer join 右表包含左表:(600, 14)
df.join
df.join主要参数说明:
- other 右表
- on 关联字段,这个和pd.concat做列join一样,是关联index的
- how='left'
- lsuffix='' 左表后缀
- rsuffix='' 右表后缀
print(df1.shape,df2.shape)df_m = df1.join(df2, how='inner',lsuffix='1',rsuffix='2')df_m.shape
输出:
(500, 8) (600, 8)
(251, 16)
行列转置
# 数据准备import mathdf['time_mark'] = df['hour'].apply(lambda x:math.ceil(int(x)/8))df_stat_raw = df.pivot_table(values= ['read_cnt','href']\,index=['weekday','time_mark']\,aggfunc={'read_cnt':'sum','href':'count'})df_stat = df_stat_raw.reset_index()
df_stat.head(3)
如上所示,df_stat是两个维度weekday,time_mark
以及两个计量指标 href, read_cnt
pivot
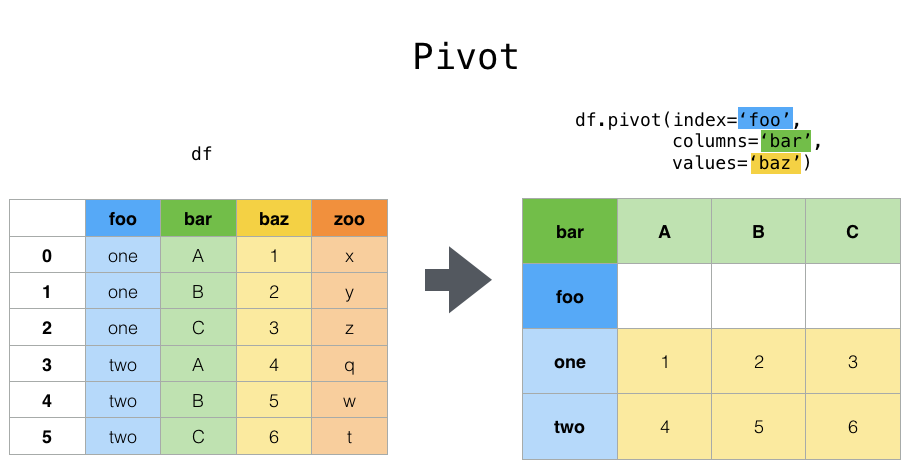
# pivot操作中,index和columns都是维度res = df_stat.pivot(index='weekday',columns='time_mark',values='href').reset_index(drop=True)res
stack & unstack
- stack则是将层级最低(默认)的column转化为index
- unstack默认是将排位最靠后的index转成column(column放到下面)
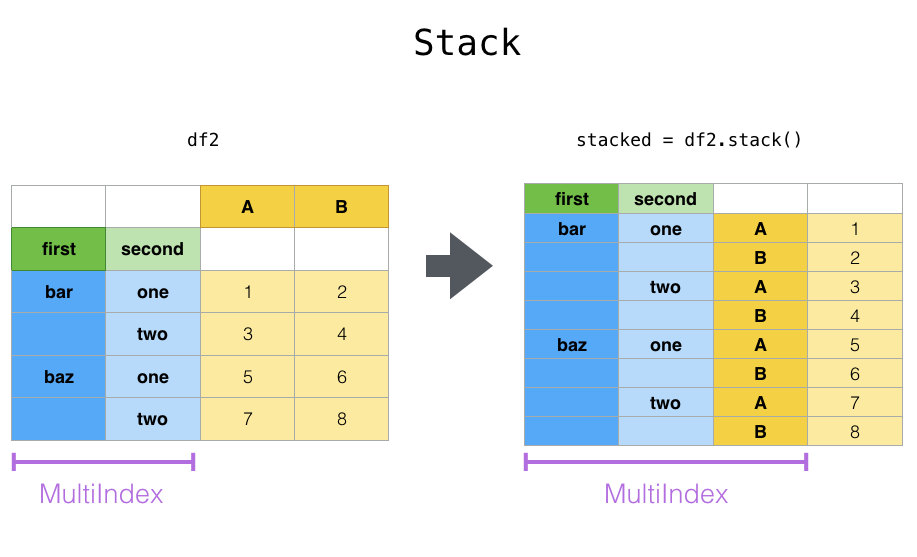
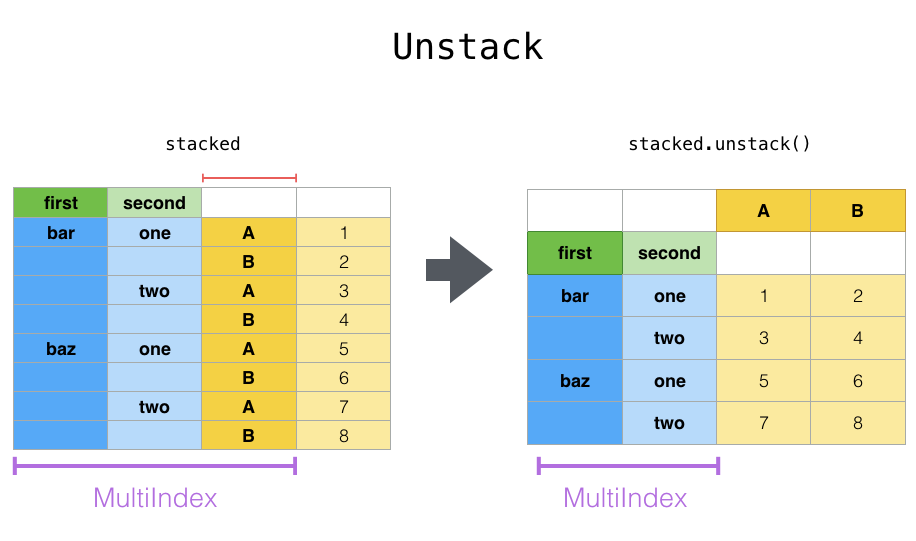

# pandas.pivot_table生成的结果如下df_stat_raw
# unstack默认是将排位最靠后的index转成column(column放到下面)df_stat_raw.unstack()# unstack也可以指定index,然后转成最底层的columndf_stat_raw.unstack('weekday')# 这个语句的效果是一样的,可以指定`index`的位置# stat_raw.unstack(0)
# stack则是将层级醉倒的column转化为indexdf_stat_raw.unstack().stack().head(5)
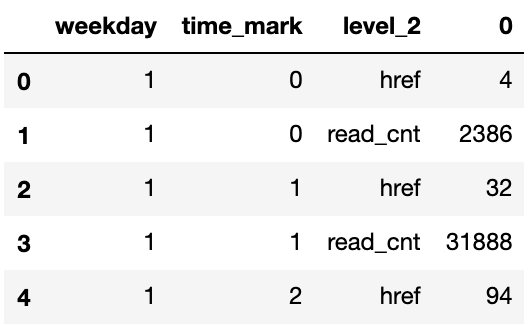
# 经过两次stack后就成为多维表了# 每次stack都会像洋葱一样将column放到左侧的index来(放到index序列最后)df_stat_raw.unstack().stack().stack().head(5)
输出:
weekday time_mark1 0 href 4read_cnt 23861 href 32read_cnt 318882 href 94dtype: int64
pd.DataFrame(df_stat_raw.unstack().stack().stack()).reset_index().head(5)
melt
melt方法中id_vals是指保留哪些作为维度(index),剩下的都看做是数值(value)
除此之外,会另外生成一个维度叫variable,列转行后记录被转的的变量名称

print(df_stat.head(5))df_stat.melt(id_vars=['weekday']).head(5)
df_stat.melt(id_vars=['weekday','time_mark']).head(5)
Python基础 | pandas中dataframe的整合与形变(merge & reshape)的更多相关文章
- Python之Pandas中Series、DataFrame
Python之Pandas中Series.DataFrame实践 1. pandas的数据结构Series 1.1 Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一 ...
- Python之Pandas中Series、DataFrame实践
Python之Pandas中Series.DataFrame实践 1. pandas的数据结构Series 1.1 Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一 ...
- Spark与Pandas中DataFrame对比
Pandas Spark 工作方式 单机single machine tool,没有并行机制parallelism不支持Hadoop,处理大量数据有瓶颈 分布式并行计算框架,内建并行机制paral ...
- Spark与Pandas中DataFrame对比(详细)
Pandas Spark 工作方式 单机single machine tool,没有并行机制parallelism不支持Hadoop,处理大量数据有瓶颈 分布式并行计算框架,内建并行机制paral ...
- Pandas中DataFrame修改列名
Pandas中DataFrame修改列名:使用 rename df = pd.read_csv('I:/Papers/consumer/codeandpaper/TmallData/result01- ...
- pandas中DataFrame的ix,loc,iloc索引方式的异同
pandas中DataFrame的ix,loc,iloc索引方式的异同 1.loc: 按照标签索引,范围包括start和end 2.iloc: 在位置上进行索引,不包括end 3.ix: 先在inde ...
- python – 基于pandas中的列中的值从DataFrame中选择行
如何从基于pandas中某些列的值的DataFrame中选择行?在SQL中我将使用: select * from table where colume_name = some_value. 我试图看看 ...
- python数据分析pandas中的DataFrame数据清洗
pandas中的DataFrame中的空数据处理方法: 方法一:直接删除 1.查看行或列是否有空格(以下的df为DataFrame类型,axis=0,代表列,axis=1代表行,以下的返回值都是行或列 ...
- Python基础 — Pandas
Pandas -- 简介 Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的. Pandas ...
随机推荐
- JSR310-新日期APIJSR310新日期API(完结篇)-生产实战
前提 前面通过五篇文章基本介绍完JSR-310常用的日期时间API以及一些工具类,这篇博文主要说说笔者在生产实战中使用JSR-310日期时间API的一些经验. 系列文章: JSR310新日期API(一 ...
- 从0开发3D引擎(补充):介绍领域驱动设计
我们使用领域驱动设计(英文缩写为DDD)的方法来设计引擎,在引擎开发的过程中,领域模型会不断地演化. 本文介绍本系列使用的领域驱动设计思想的相关概念和知识点,给出了相关的资料. 上一篇博文 从0开发3 ...
- 用 Python 生成 HTML 表格
在 邮件报表 之类的开发任务中,需要生成 HTML 表格. 使用 Python 生成 HTML 表格基本没啥难度, for 循环遍历一遍数据并输出标签即可. 如果需要实现合并单元格,或者按需调整表格样 ...
- Asp.Net Core 2.0实现HttpResponse中繁切换
随笔背景:因为项目中有个简单的功能是需要实现中文简体到繁体的切换,数据库中存储的源数据都是中文简体的,为了省事就想着通过HttpHeader的方式来控制Api返回对应的繁体数据. 实现方式:通过Asp ...
- 【Java实用工具】——使用oshi获取主机信息
最近在筹划做一个监控系统.其中就要获取主机信息,其中遇到一些问题.在此做个记录,以便以后查阅. 在该监控系统中,想要做到主机的CPU.内存.磁盘.网络.线程.JVM内存.JVM GC 等维度的监控,J ...
- R语言实战(二) 创建数据集
2.1 数据集的概念 不同的行业对于数据集的行和列叫法不同.统计学家称它们为观测(observation)和变量(variable),数据库分析师则称其为记录(record)和字段(field),数据 ...
- Button相关设置
2020-03-11 每日一例第4天 1.添加按钮1-6,并修改相应的text值: 2.窗体Load事件加载代码: private void Form1_Load(object sender, Ev ...
- Python实现对excel的操作
1.操作excel使用第三方库openpyxl安装:pip install openpyxy引入:import openpyxl2.常用简单操作1)打开excel文件获取工作簿wb = openpyx ...
- 数据结构 - ArrayList
简介 ArrayList是一个动态数组.ArrayList几乎拥有数组所有优点,例如元素有序,索引访问等:并且一般情况下它还不会越界,添加元素时它能动态扩容.平时工作中ArrayList被我们广泛应用 ...
- React利用Antd的Form组件实现表单功能(转载)
一.构造组件 1.表单一定会包含表单域,表单域可以是输入控件,标准表单域,标签,下拉菜单,文本域等. 这里先引用了封装的表单域 <Form.Item /> 2.使用Form.create处 ...