python爬取网站页面时,部分标签无指定属性而报错
在写爬取页面a标签下href属性的时候,有这样一个问题,如果a标签下没有href这个属性则会报错,如下:


百度了有师傅用正则匹配的,方法感觉都不怎么好,查了BeautifulSoup的官方文档,发现一个不错的方法,如下图:
官方文档链接:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
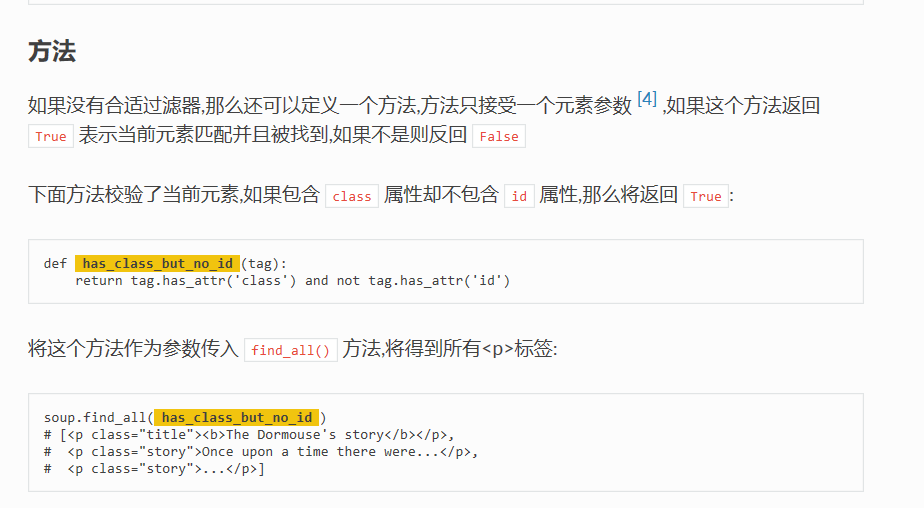
has_attr() 这个方法可以判断某标签是否存在某属性,如果存在则返回 True
解决办法:
为美观使用了匿名函数
soup_a = soup.find_all(lambda tag:tag.has_attr('href'))

最终实现爬取页面 url 脚本如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Riy import time
import requests
import sys
import logging
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
from multiprocessing import Process, Pool logging.basicConfig(
level=logging.DEBUG,
format='%(levelname)-10s: %(message)s',
) class down_url:
def download(self, url):
'''爬取url'''
try:
start = time.time()
logging.debug('starting download url...')
response = requests.get(url)
page = response.content
soup = BeautifulSoup(page, 'lxml')
soup_a = soup.select('a')
soup_a = soup.find_all(lambda tag:tag.has_attr('href'))
soup_a_href_list = []
# print(soup_a)
for k in soup_a:
# print(k)
soup_a_href = k['href']
if soup_a_href.find('.'):
# print(soup_a_href)
soup_a_href_list.append(soup_a_href)
print(f'运行了{time.time()-start}秒')
except RecursionError as e:
print(e)
return soup_a_href_list def write(soup_a_href_list, txt):
'''下载到txt文件'''
logging.debug('starting write txt...')
with open(txt, 'a', encoding='utf-8') as f:
for i in soup_a_href_list:
f.writelines(f'{i}\n')
print(f'已生成文件{txt}') def help_memo(self):
'''查看帮助'''
print('''
-h or --help 查看帮助
-u or --url 添加url
-t or --txt 写入txt文件
''') def welcome(self):
'''欢迎页面'''
desc = ('欢迎使用url爬取脚本'.center(30, '*'))
print(desc) def main():
'''主函数'''
p = Pool(3)
p_list = []
temp = down_url()
logging.debug('starting run python...')
try:
if len(sys.argv) == 1:
temp.welcome()
temp.help_memo()
elif sys.argv[1] in {'-h', '--help'}:
temp.help_memo()
elif sys.argv[1] in {'-u ', '--url'} and sys.argv[3] in {'-t', '--txt'}:
a = temp.download(sys.argv[2])
temp.write(a, sys.argv[4])
elif sys.argv[1] in {'-t', '--txt'}:
print('请先输入url!')
elif sys.argv[1] in {'-u', '--url'}:
url_list = sys.argv[2:]
print(url_list)
for i in url_list:
a = p.apply_async(temp.download, args=(i,))
p_list.append(a)
for p in p_list:
print(p.get())
else:
temp.help_memo() print('输入的参数有误!')
except Exception as e:
print(e)
temp.help_memo() if __name__ == '__main__':
main()
python爬取网站页面时,部分标签无指定属性而报错的更多相关文章
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取网站数据保存使用的方法
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存的方法,其中解决了编码问题和如何使用正则匹配数据的方法,详情看下文 编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这 ...
- Python 爬取网站资源文件
爬虫原理: 以下来自知乎解释 首先你要明白爬虫怎样工作.想象你是一只蜘蛛,现在你被放到了互联“网”上.那么,你需要把所有的网页都看一遍.怎么办呢?没问题呀,你就随便从某个地方开始,比如说人民日报的首页 ...
- python 爬取html页面
#coding=utf-8 import urllib.request def gethtml(url): page=urllib.request.urlopen(url) html=page.rea ...
- Python爬取中文页面的时候出现的乱码问题(续)
我在上一篇博客中说明了在爬取数据的时候,把数据写入到文件的乱码问题 在这一篇里面我做一个总结: 1.首先应该看一个案例 我把数据写在.py文件中: #coding:utf-8 s = 'hehe测试中 ...
- Python爬取中文页面的时候出现的乱码问题
一.读取返回的页面数据 在浏览器打开的时候查看源代码,如果在头部信息中指定了UTF-8 那么再python代码中读取页面信息的时候,就需要指定读取的编码方式: response.read().deco ...
- Python爬取网站上面的数据很简单,但是如何爬取APP上面的数据呢
- 3.15学习总结(Python爬取网站数据并存入数据库)
在官网上下载了Python和PyCharm,并在网上简单的学习了爬虫的相关知识. 结对开发的第一阶段要求: 网上爬取最新疫情数据,并存入到MySql数据库中 在可视化显示数据详细信息 项目代码: im ...
- 解决:Python爬取https站点时SNIMissingWarning和InsecurePlatformWarning
今天想利用Requests库爬取糗事百科站点,写了一个请求,却报错了: 后来参考kinsomy的博客,在cmd中pip install pyopenssl ndg-httpsclient pyasn1 ...
随机推荐
- 添砖加瓦:Linux系统监测
前言 前段时间因为项目需求,需要实时获取系统当前的运行状态,遂查阅了不少资料,基于/proc目录下的部分文件,实现了系统CPU.内存.网络和磁盘的实时监测. 一.CPU使用情况获取 获取CPU使用情况 ...
- 在线做RAID命令
# 安装raid卡管理工具 wget http://10.12.30.102:10800/other/MegaCli-8.07.14-1.noarch.rpm -O /tmp/MegaCli-8.07 ...
- Oracle介绍
Published: 2016-11-08 22:15:00 In Data Mining. tags: SQL 版本与配置 企业版 标准版 个人版 事务性数据表 分析型数据表 PL/SQL 配置 控 ...
- 事务Transaction
目录 为什么写这系列的文章 事务概念 ACID 并发事务导致的问题 脏读(Dirty Read) 非重复读(Nonrepeatable Read) 幻读(Phantom Reads) 丢失修改(Los ...
- GDB调试系列之了解GDB
想要熟练利用GDB进行程序调试,首先要了解什么是GDB. 1. 什么是GDB GDB (the GNU Project Debugger) 是一个可以运行在大多数常见的UNIX架构.Windows.M ...
- ORB-SLAM2 运行 —— ROS + Android 手机摄像头
转载请注明出处,谢谢 原创作者:Mingrui 原创链接:https://www.cnblogs.com/MingruiYu/p/12404730.html 本文要点: ROS 配置安装 解决 sud ...
- 7-35 jmu-python-求三角形面积及周长 (10 分)
输入的三角形的三条边a.b.c,计算并输出面积和周长.假设输入三角形三边是合法整形数据. 三角形面积计算公式: ,其中s=(a+b+c)/2. import math #导入math库 math.s ...
- 7-30 jmu-python-凯撒密码加密算法 (10 分)
编写一个凯撒密码加密程序,接收用户输入的文本和密钥k,对明文中的字母a-z和字母A-Z替换为其后第k个字母. 输入格式: 接收两行输入,第一行为待加密的明文,第二行为密钥k. 输出格式: 输出加密后的 ...
- 7-10 jmu-python-异常-学生成绩处理基本版 (15 分)
小明在帮老师处理数据,这些数据的第一行是n,代表有n行整数成绩需要统计.数据没有错误,则计算平均值(保留2位小数)并输出.数据有错误,直接停止处理,并且不进行计算. 注:该程序可以适当处理小错误,比如 ...
- D3.js实现拓扑图
最近写项目需要画出应用程序调用链的网路拓扑图,完全自己写需要花费些时间,那么首先想到的是echarts,但echarts的自定义写法写起来非常麻烦,而且它的文档都是基于配置说明的,对于自定义开发不太方 ...