【NLP面试QA】预训练模型
自回归语言模型与自编码语言
自回归语言模型
- 通过给定文本的上文,对下一个字进行预测
- 优点:对文本序列联合概率的密度估计进行建模,使得该模型更适用于一些生成类的NLP任务,因为这些任务在生成内容的时候就是从左到右的,这和自回归的模式天然匹配。
- 缺点:联合概率是按照文本序列从左至右进行计算的,因此无法提取下文信息;
- 代表模型:ELMo/GPT1.0/GPT2.0/XLNet(XLNet 做了些改进使得能够提取到下文特征)
自编码语言模型
- 其通过随机 mask 掉一些单词,在训练过程中根据上下文对这些单词进行预测,使预测概率最大化。其本质为去噪自编码模型,加入的 [MASK] 即为噪声,模型对 [MASK] 进行预测即为去噪。
- 优点:能够利用上下文信息得到双向特征表示
- 缺点:其引入了独立性假设,即每个 [MASK] 之间是相互独立的。这实际上是语言模型的有偏估计,另外,由于预训练中 [MASK] 的存在,使得模型预训练阶段的数据与微调阶段的不匹配,使其难以直接用于生成任务。
- 代表模型:Bert/Roberta/ERNIE
Bert
Bert 中的预训练任务
Masked Language Model
在预训练任务中,15%的 Word Piece 会被 mask,这15%的 Word Piece 中,80%的时候会直接替换为 [Mask] ,10%的时候将其替换为其它任意单词,10%的时候会保留原始Token
- 没有 100% mask 的原因
- 如果句子中的某个Token100%都会被mask掉,那么在fine-tuning的时候模型就会有一些没有见过的单词
- 加入 10% 随机 token 的原因
- Transformer 要保持对每个输入token的分布式表征,否则模型就会记住这个 [mask] 是token ’hairy‘
- 另外编码器不知道哪些词需要预测的,哪些词是错误的,因此被迫需要学习每一个 token 的表示向量
- 另外,每个 batchsize 只有 15% 的单词被 mask 的原因,是因为性能开销的问题,双向编码器比单项编码器训练要更慢
Next Sentence Prediction
仅仅一个MLM任务是不足以让 BERT 解决阅读理解等句子关系判断任务的,因此添加了额外的一个预训练任务,即 Next Sequence Prediction。
具体任务即为一个句子关系判断任务,即判断句子B是否是句子A的下文,如果是的话输出’IsNext‘,否则输出’NotNext‘。
训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。这个关系保存在图4中的[CLS]符号中
但实际上这个任务是过于简单了的,对于模型的预训练并没有太大的帮助,在 Roberta 的模型中将其去掉了
Bert 的 Embedding
BERT的输入表征由三种Embedding求和而成:
- Token Embeddings:即传统的词向量层,每个输入样本的首字符需要设置为 [CLS],可以用于之后的分类任务,若有两个不同的句子,需要用 [SEP] 分隔,且最后一个字符需要用 [SEP] 表示终止
- Segment Embeddings:为 \([0, 1]\) 序列,用来在 NSP 任务中区别两个句子,便于做句子关系判断任务
- Position Embeddings:与 Transformer 中的位置向量不同,BERT 中的位置向量是直接训练出来的
BERT-wwm
- Whole Word Masking 即全词 Mask,打破了传统 Bert 的独立性假设,即每个 [MASK] 之间是相互独立的。这使得同一个词中不同字符的预测的上下文语境是相同的,加强同一个词不同字符之间的相关性。
Roberta 与 Bert 的区别
- 训练参数经过了仔细的挑参,训练数据更大,训练 Batch Size 更大
- 认为 Next Sentence Prediction 任务没有太大帮助,将 NSP loss 去掉,输入改为从一个文档中连续抽取句子,当到达文档末尾时,加一个分隔符再抽样下一个文档的句子。
- Bert 的语料在预处理的时候就会被 Mask,在训练阶段保持不变;而 Roberta 中改为动态的 Mask,使得每次读取到的数据都不一样(具体是将数据复制10遍,统一随机 Mask)
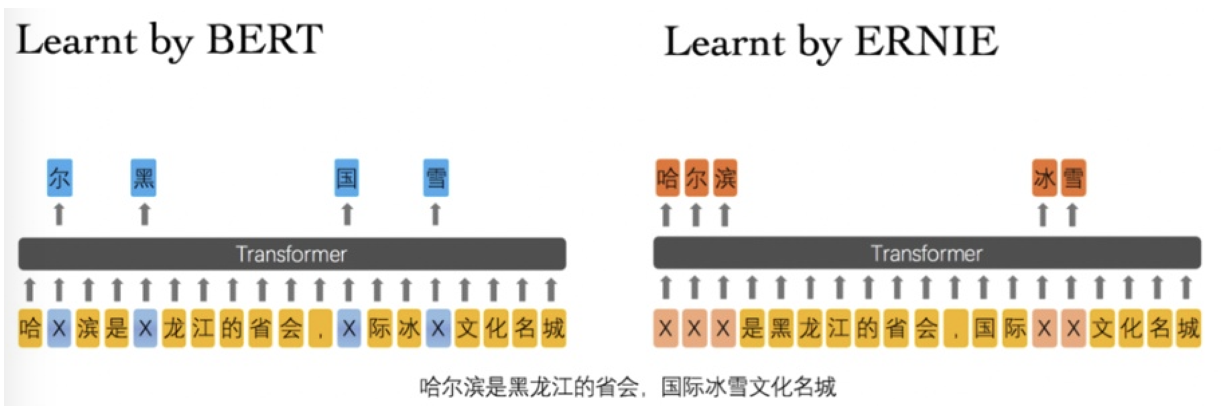
ERNIE 与 Bert 的区别
由于 Bert 仅对单个的字符进行 Mask 很容易使得模型提取到字搭配的低层次的语义特征,而对于短语和实体层次的语义信息抽取能力较弱。因此将外部知识引入到预训练任务中,主要有三个层次的预训练任务
- Basic-Level Masking: 跟bert一样对单字进行mask,很难学习到高层次的语义信息;
- Phrase-Level Masking: 输入仍然是单字级别的,mask连续短语;
- Entity-Level Masking: 首先进行实体识别,然后将识别出的实体进行mask。
XLNet
XLNet 针对自回归语言模型单向编码以及 BERT 类自编码语言模型的有偏估计的缺点,提出了一种广义自回归语言预训练方法。
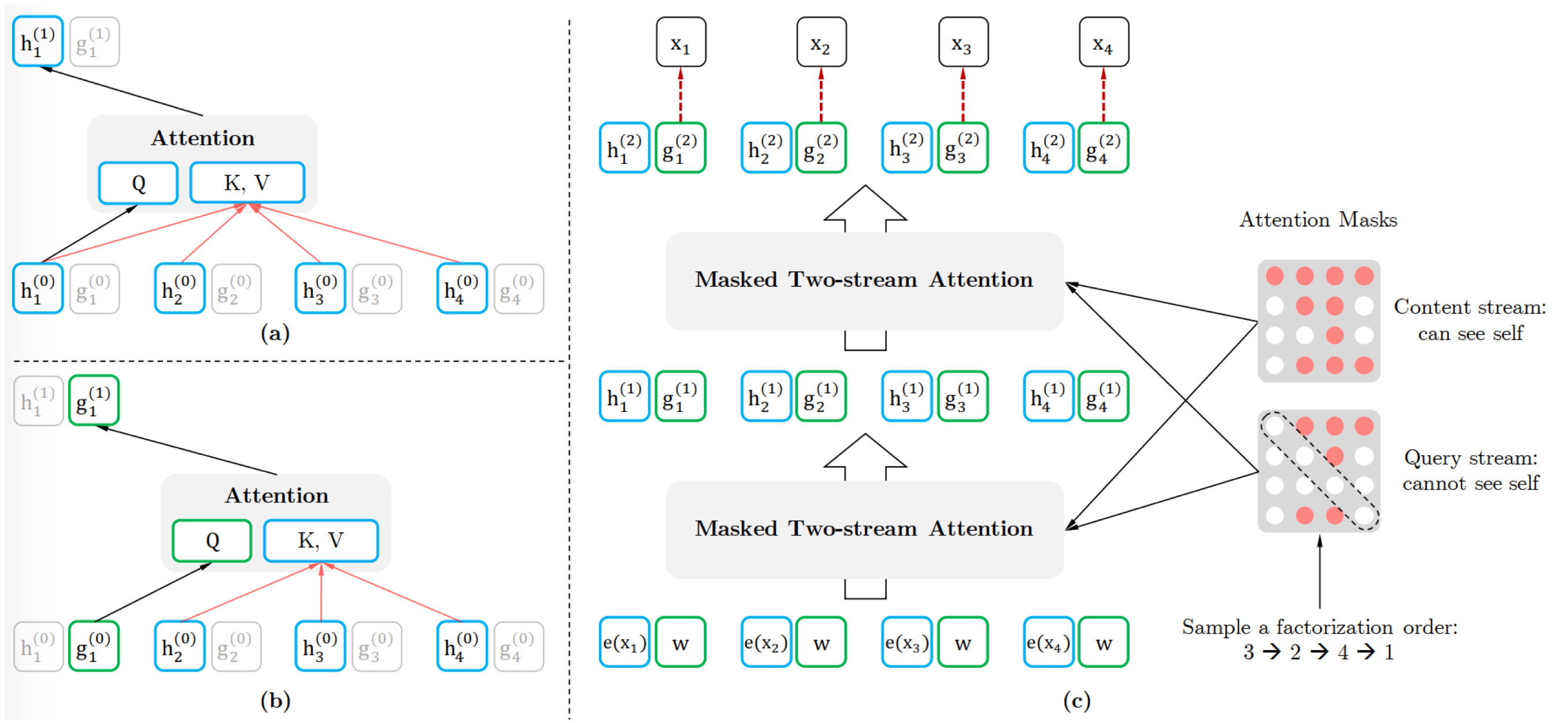
排列语言模型(Permutation Language Model,PLM)
通过引入一个排列语言模型,希望语言模型用自回归的方法从左往右预测下一个字符的时候,不仅要包含上文信息,同时也要能够提取到对应字符的下文信息,且不需要引入Mask符号。
首先将句子进行重排列,重排列后的末尾几个字就能够看见其之后的一些词,根据能够看到的对象进行相应的 Mask 即可。在实现上是通过对 Attention 矩阵增加掩码来选择哪些词能够被看见哪些词不能够被看见的。
双流注意力机制(Two-Stream Self-Attention)
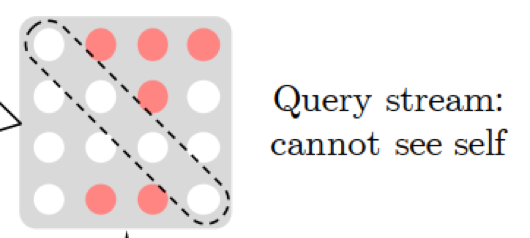
由于我们有多层的 Transformer,需要在最后一层预测最末尾的几个字,比如最大长度为 512,最后一层只需要预测最后 10 个词,我们需要所有字的信息都能传输到最后一层,但又希望最后在预测某个字的时候看不到这个字的信息,因此引入了双流注意力机制
Query Stream 的掩码矩阵中仅传输位置信息,用于表明预测顺序是什么样的;Content Stream 与传统的 Transformer 一致,包括内容信息和位置信息,确保所有的字信息都能传输到最后一层。个 Attention Stream 的区别仅在于掩码是否能看见自己,以及输入一个是仅有位置信息,另一个是包括位置和内容信息。

部分预测(Partial Prediction)
如果重排列之后对所有字都进行预测的话模型难以收敛(可能是前几个字看到的字的个数太少),计算量也大。因此仅对最后 15% 的字进行预测
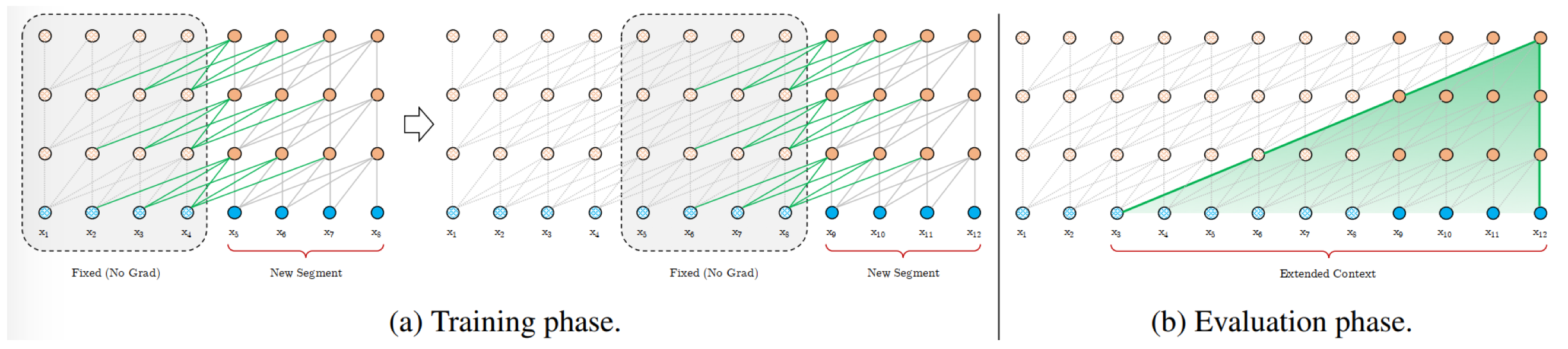
Transformer-XL
传统的 Transformer 的输入长度限制在 512,更长的文本信息模型是学不到的。
- 片段递归机制(segment-level recurrence mechanism):指的是当前时刻的隐藏信息在计算过程中,将通过循环递归的方式利用上一时刻较浅层的隐藏状态(上一时刻的隐藏状态均存储到一个临时存储空间中),这使得每次的计算将利用更大长度的上下文信息,大大增加了捕获长距离信息的能力。
- 相对位置编码(Relative Positional Encodings):采用了片段递归机制之后,不同片段的位置信息是一样的然后叠加在了一起,这是不合适的,因此提出了相对位置编码的方式来替代绝对位置编码
ALBERT
ALBERT 贡献在于,其提出了两种模型参数缩减的技术,使得在减小模型重量的同时,模型性能不会受到太大的影响。
对Embedding因式分解
采用了一个因式分解的方式对 Embedding 层的矩阵进行压缩。简单来说,就是先将 one-hot 映射到一个低维空间 \(E\),然后再将其从低维空间映射到高维空间 \(H\),即参数量的变化为 \(O(V \times H) => O(V \times E + E \times H)\),且论文也用实验证明,Embedding的参数缩减对整个模型的性能并没有太大的影响
跨层参数共享
多层 Transformer 共享参数,提高参数利用率,使得参数量得到有效的减少。(参数共享的对象为 Transformer 中的 feed-forward layer 参数和 self-attention 的参数)
句间连贯性损失
ALBERT 针对预训练任务中的 NSP 任务进行改进,即句间连贯性判断。NSP 任务仅需判断两个文段是否是一个主题即可,该任务太简单了。句间连贯性判断任务需要判断两个文段的顺序是否颠倒,强迫模型去学习文段的语意,这相比于 NSP 任务更加巧妙。
【NLP面试QA】预训练模型的更多相关文章
- 【NLP面试QA】基本策略
目录 防止过拟合的方法 什么是梯度消失和梯度爆炸?如何解决? 在深度学习中,网络层数增多会伴随哪些问题,怎么解决? 关于模型参数 模型参数初始化的方法 模型参数初始化为 0.过大.过小会怎样? 为什么 ...
- 【NLP面试QA】激活函数与损失函数
目录 Sigmoid 函数的优缺点是什么 ReLU的优缺点 什么是交叉熵 为什么分类问题的损失函数为交叉熵而不能是 MSE? 多分类问题中,使用 sigmoid 和 softmax 作为最后一层激活函 ...
- 【转载】最强NLP预训练模型!谷歌BERT横扫11项NLP任务记录
本文介绍了一种新的语言表征模型 BERT--来自 Transformer 的双向编码器表征.与最近的语言表征模型不同,BERT 旨在基于所有层的左.右语境来预训练深度双向表征.BERT 是首个在大批句 ...
- NLP与深度学习(五)BERT预训练模型
1. BERT简介 Transformer架构的出现,是NLP界的一个重要的里程碑.它激发了很多基于此架构的模型,其中一个非常重要的模型就是BERT. BERT的全称是Bidirectional En ...
- 最强中文NLP预训练模型艾尼ERNIE官方揭秘【附视频】
“最近刚好在用ERNIE写毕业论文” “感觉还挺厉害的” “为什么叫ERNIE啊,这名字有什么深意吗?” “我想让艾尼帮我写作业” 看了上面火热的讨论,你一定很好奇“艾尼”.“ERNIE”到底是个啥? ...
- 百度NLP预训练模型ERNIE2.0最强实操课程来袭!【附教程】
2019年3月,百度正式发布NLP模型ERNIE,其在中文任务中全面超越BERT一度引发业界广泛关注和探讨.经过短短几个月时间,百度ERNIE再升级,发布持续学习的语义理解框架ERNIE 2.0,及基 ...
- 最强 NLP 预训练模型库 PyTorch-Transformers 正式开源:支持 6 个预训练框架,27 个预训练模型
先上开源地址: https://github.com/huggingface/pytorch-transformers#quick-tour 官网: https://huggingface.co/py ...
- 预训练模型——开创NLP新纪元
预训练模型--开创NLP新纪元 论文地址 BERT相关论文列表 清华整理-预训练语言模型 awesome-bert-nlp BERT Lang Street huggingface models 论文 ...
- 管正雄:基于预训练模型、智能运维的QA生成算法落地
分享嘉宾:管正雄 阿里云 高级算法工程师 出品平台:DataFunTalk 导读:面对海量的用户问题,有限的支持人员该如何高效服务好用户?智能QA生成模型给业务带来的提效以及如何高效地构建算法服务,为 ...
随机推荐
- Selenium2自动化——初体验
一.Windows下的环境搭建 1.安装Python 访问Python官网:https://www.python.org/ 2.安装setuptools与pip setuptools是Python e ...
- C++扬帆远航——7(年月日)
/* * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:charizi.cpp * 作者:常轩 * 完成日期:2016年 ...
- 微信小程序app.js中设置公有变量
初始化GlobalData 在App.js的最上方可以设置GlobalData的初始值. App({ globalData:{ appid: '1wqas2342dasaqwe232342xxxxxx ...
- node生成excel,动态替换表格内容
这里使用的是exceljs模块, 好上手,易操作 1. 大致使用步骤 npm install exceljs // 引用var Excel = require('exceljs'); // 创建一个w ...
- Kafka体系架构详细分解
我的个人博客排版更舒服: https://www.luozhiyun.com/archives/260 基本概念 Kafka 体系架构 Kafka 体系架构包括若干 Producer.若干 Broke ...
- (27)ASP.NET Core .NET标准REST库Refit
1.简介 Refit是一个受到Square的Retrofit库(Java)启发的自动类型安全REST库.通过HttpClient网络请求(POST,GET,PUT,DELETE等封装)把REST AP ...
- python 深浅拷贝 元组 字典 集合操作
深浅拷贝 :值拷贝 :ls = [,,] res = ls 则print(res)就是[,,] 浅拷贝 :ls.copy() 深拷贝:ls3 = deepcopy(ls) # 新开辟列表空间,ls列表 ...
- 使用openxml提取word中的文本和图片并转为Html
使用openxml提取word中的文本和图片 使用 openXml 提取 word 中的 Text 和 Drawing 使用 openXml 将 word 中的文本和图片转为Html 使用 openX ...
- Git建立本地分支和远程分支的映射关系
git branch -vv:查看本地分支和远程分支的映射关系 在切换分支前,须本地建立新分支,例如:git branch release/v1.1 //本地建立release/v1.1分支成功后 ...
- Docker Compose + Traefik v2 快速安装, 自动申请SSL证书 http转https 初次尝试
前言 昨晚闲得无聊睡不着觉,拿起服务器尝试部署了一下Docker + Traefik v2.1.6 ,以下是一些配置的总结,初次接触,大佬勿喷. 我的系统环境是 Ubuntu 18.04.3 LTS ...