Tensorflow学习教程------过拟合
Tensorflow学习教程------过拟合
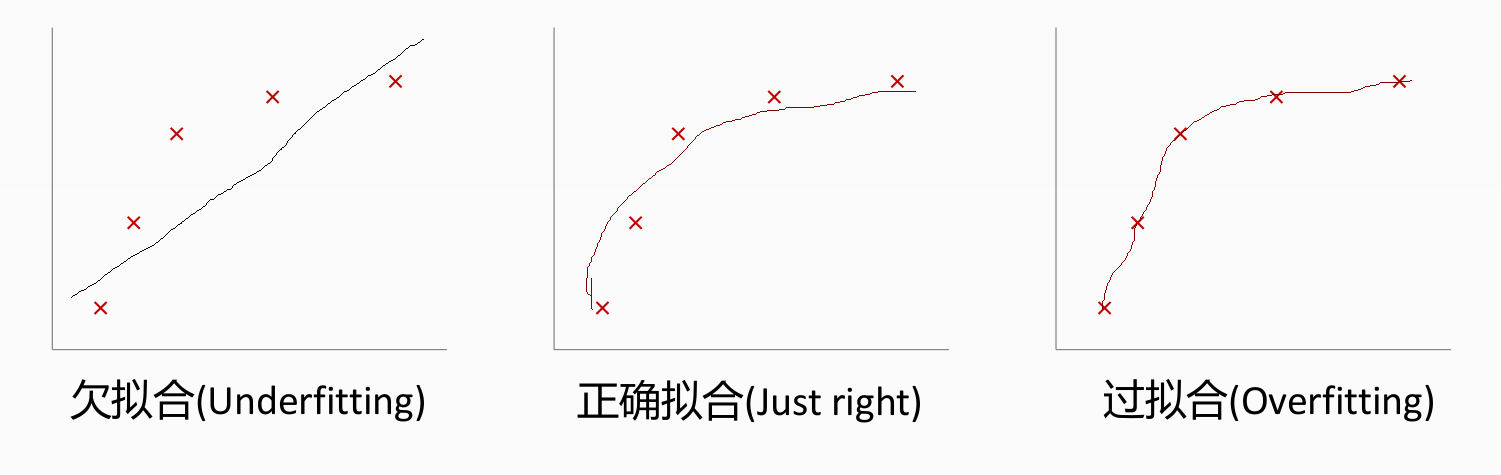
回归:过拟合情况
/
分类过拟合
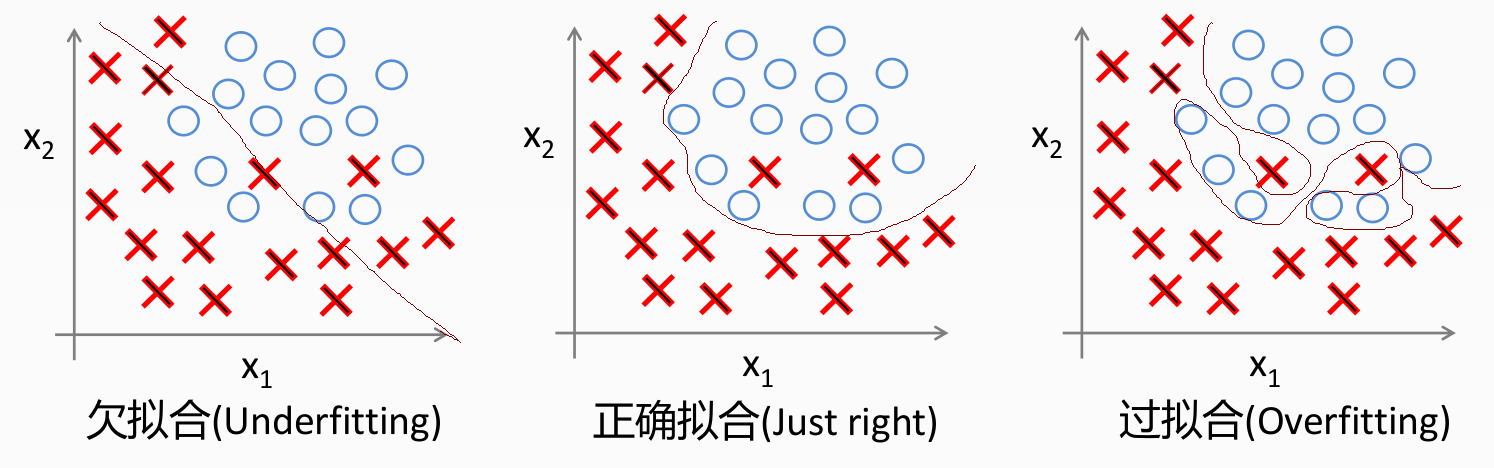
防止过拟合的方法有三种:
1 增加数据集
2 添加正则项
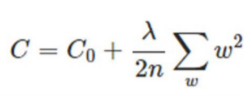
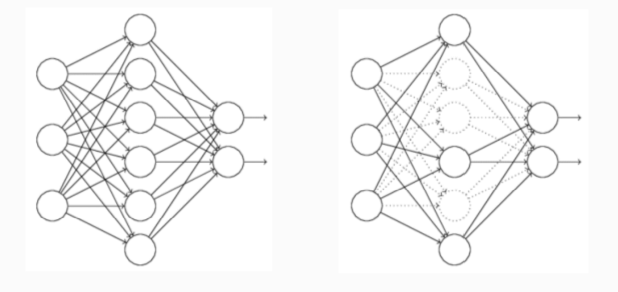
3 Dropout,意思就是训练的时候隐层神经元每次随机抽取部分参与训练。部分不参与
最后对之前普通神经网络分类mnist数据集的代码进行优化,初始化权重参数的时候采用截断正态分布,偏置项加常数,采用dropout防止过拟合,加三层隐层神经元,最后的准确率达到97%以上。代码如下

# coding: utf-8 # 微信公众号:深度学习与神经网络
# Github:https://github.com/Qinbf
# 优酷频道:http://i.youku.com/sdxxqbf import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data #载入数据集
mnist = input_data.read_data_sets("MNIST_data",one_hot=True) #每个批次的大小
batch_size = 100
#计算一共有多少个批次
n_batch = mnist.train.num_examples // batch_size #定义两个placeholder
x = tf.placeholder(tf.float32,[None,784])
y = tf.placeholder(tf.float32,[None,10])
keep_prob=tf.placeholder(tf.float32) #创建一个简单的神经网络
W1 = tf.Variable(tf.truncated_normal([784,2000],stddev=0.1))
b1 = tf.Variable(tf.zeros([2000])+0.1)
L1 = tf.nn.tanh(tf.matmul(x,W1)+b1)
L1_drop = tf.nn.dropout(L1,keep_prob) W2 = tf.Variable(tf.truncated_normal([2000,2000],stddev=0.1))
b2 = tf.Variable(tf.zeros([2000])+0.1)
L2 = tf.nn.tanh(tf.matmul(L1_drop,W2)+b2)
L2_drop = tf.nn.dropout(L2,keep_prob) W3 = tf.Variable(tf.truncated_normal([2000,1000],stddev=0.1))
b3 = tf.Variable(tf.zeros([1000])+0.1)
L3 = tf.nn.tanh(tf.matmul(L2_drop,W3)+b3)
L3_drop = tf.nn.dropout(L3,keep_prob) W4 = tf.Variable(tf.truncated_normal([1000,10],stddev=0.1))
b4 = tf.Variable(tf.zeros([10])+0.1)
prediction = tf.nn.softmax(tf.matmul(L3_drop,W4)+b4) #二次代价函数
# loss = tf.reduce_mean(tf.square(y-prediction))
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction))
#使用梯度下降法
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss) #初始化变量
init = tf.global_variables_initializer() #结果存放在一个布尔型列表中
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))#argmax返回一维张量中最大的值所在的位置
#求准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) with tf.Session() as sess:
sess.run(init)
for epoch in range(31):
for batch in range(n_batch):
batch_xs,batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys,keep_prob:0.7}) test_acc = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels,keep_prob:1.0})
train_acc = sess.run(accuracy,feed_dict={x:mnist.train.images,y:mnist.train.labels,keep_prob:1.0})
print("Iter " + str(epoch) + ",Testing Accuracy " + str(test_acc) +",Training Accuracy " + str(train_acc))
结果如下
Iter 0,Testing Accuracy 0.913,Training Accuracy 0.909146
Iter 1,Testing Accuracy 0.9318,Training Accuracy 0.927218
Iter 2,Testing Accuracy 0.9397,Training Accuracy 0.9362
Iter 3,Testing Accuracy 0.943,Training Accuracy 0.940637
Iter 4,Testing Accuracy 0.9449,Training Accuracy 0.945746
Iter 5,Testing Accuracy 0.9489,Training Accuracy 0.949491
Iter 6,Testing Accuracy 0.9505,Training Accuracy 0.9522
Iter 7,Testing Accuracy 0.9542,Training Accuracy 0.956
Iter 8,Testing Accuracy 0.9543,Training Accuracy 0.957782
Iter 9,Testing Accuracy 0.954,Training Accuracy 0.959
Iter 10,Testing Accuracy 0.9558,Training Accuracy 0.959582
Iter 11,Testing Accuracy 0.9594,Training Accuracy 0.963146
Iter 12,Testing Accuracy 0.959,Training Accuracy 0.963746
Iter 13,Testing Accuracy 0.961,Training Accuracy 0.964764
Iter 14,Testing Accuracy 0.9605,Training Accuracy 0.9658
Iter 15,Testing Accuracy 0.9635,Training Accuracy 0.967528
Iter 16,Testing Accuracy 0.9639,Training Accuracy 0.968582
Iter 17,Testing Accuracy 0.9644,Training Accuracy 0.969309
Iter 18,Testing Accuracy 0.9651,Training Accuracy 0.969564
Iter 19,Testing Accuracy 0.9664,Training Accuracy 0.971073
Iter 20,Testing Accuracy 0.9654,Training Accuracy 0.971746
Iter 21,Testing Accuracy 0.9664,Training Accuracy 0.971764
Iter 22,Testing Accuracy 0.9682,Training Accuracy 0.973128
Iter 23,Testing Accuracy 0.9679,Training Accuracy 0.973346
Iter 24,Testing Accuracy 0.9681,Training Accuracy 0.975164
Iter 25,Testing Accuracy 0.969,Training Accuracy 0.9754
Iter 26,Testing Accuracy 0.9706,Training Accuracy 0.975764
Iter 27,Testing Accuracy 0.9694,Training Accuracy 0.975837
Iter 28,Testing Accuracy 0.9703,Training Accuracy 0.977109
Iter 29,Testing Accuracy 0.97,Training Accuracy 0.976946
Iter 30,Testing Accuracy 0.9715,Training Accuracy 0.977491
Testing Accuracy和Training Accuracy之间的差距为0.005991
dropout值设置为1的时候,
Iter 0,Testing Accuracy 0.9471,Training Accuracy 0.955037
Iter 1,Testing Accuracy 0.9597,Training Accuracy 0.9738
Iter 2,Testing Accuracy 0.9616,Training Accuracy 0.980928
Iter 3,Testing Accuracy 0.9661,Training Accuracy 0.985091
Iter 4,Testing Accuracy 0.9674,Training Accuracy 0.987709
Iter 5,Testing Accuracy 0.9692,Training Accuracy 0.989255
Iter 6,Testing Accuracy 0.9692,Training Accuracy 0.990146
Iter 7,Testing Accuracy 0.9708,Training Accuracy 0.991182
Iter 8,Testing Accuracy 0.9711,Training Accuracy 0.991982
Iter 9,Testing Accuracy 0.9712,Training Accuracy 0.9924
Iter 10,Testing Accuracy 0.971,Training Accuracy 0.992691
Iter 11,Testing Accuracy 0.9706,Training Accuracy 0.993055
Iter 12,Testing Accuracy 0.971,Training Accuracy 0.993309
Iter 13,Testing Accuracy 0.9717,Training Accuracy 0.993528
Iter 14,Testing Accuracy 0.9719,Training Accuracy 0.993764
Iter 15,Testing Accuracy 0.9715,Training Accuracy 0.993927
Iter 16,Testing Accuracy 0.9715,Training Accuracy 0.994091
Iter 17,Testing Accuracy 0.9714,Training Accuracy 0.994291
Iter 18,Testing Accuracy 0.9719,Training Accuracy 0.9944
Iter 19,Testing Accuracy 0.9719,Training Accuracy 0.994564
Iter 20,Testing Accuracy 0.9722,Training Accuracy 0.994673
Iter 21,Testing Accuracy 0.9725,Training Accuracy 0.994855
Iter 22,Testing Accuracy 0.9731,Training Accuracy 0.994891
Iter 23,Testing Accuracy 0.9721,Training Accuracy 0.994928
Iter 24,Testing Accuracy 0.9722,Training Accuracy 0.995018
Iter 25,Testing Accuracy 0.9725,Training Accuracy 0.995109
Iter 26,Testing Accuracy 0.9729,Training Accuracy 0.9952
Iter 27,Testing Accuracy 0.9726,Training Accuracy 0.995255
Iter 28,Testing Accuracy 0.9725,Training Accuracy 0.995327
Iter 29,Testing Accuracy 0.9725,Training Accuracy 0.995364
Iter 30,Testing Accuracy 0.9722,Training Accuracy 0.995437
Testing Accuracy和Training Accuracy之间的差距为0.23237,本次实验中只有60000个样本,当样本量到达几百万的时候,这个差距值会更大,也就是训练出的模型在训练数据集中效果非常好,几乎满足了任意一个样本,但是在测试数据集中效果却很差,此时就是典型的过拟合现象。
所以一般稍微复杂的网络中都会加入dropout,防止过拟合。
Tensorflow学习教程------过拟合的更多相关文章
- Tensorflow学习教程------代价函数
Tensorflow学习教程------代价函数 二次代价函数(quadratic cost): 其中,C表示代价函数,x表示样本,y表示实际值,a表示输出值,n表示样本的总数.为简单起见,使用一 ...
- Tensorflow学习教程------读取数据、建立网络、训练模型,小巧而完整的代码示例
紧接上篇Tensorflow学习教程------tfrecords数据格式生成与读取,本篇将数据读取.建立网络以及模型训练整理成一个小样例,完整代码如下. #coding:utf-8 import t ...
- tensorflow 学习教程
tensorflow 学习手册 tensorflow 学习手册1:https://cloud.tencent.com/developer/section/1475687 tensorflow 学习手册 ...
- Tensorflow学习教程------创建图启动图
Tensorflow作为目前最热门的机器学习框架之一,受到了工业界和学界的热门追捧.以下几章教程将记录本人学习tensorflow的一些过程. 在tensorflow这个框架里,可以讲是若数据类型,也 ...
- Tensorflow学习教程------lenet多标签分类
本文在上篇的基础上利用lenet进行多标签分类.五个分类标准,每个标准分两类.实际来说,本文所介绍的多标签分类属于多任务学习中的联合训练,具体代码如下. #coding:utf-8 import te ...
- tensorflow学习2-线性拟合和神经网路拟合
线性拟合的思路: 线性拟合代码: import tensorflow as tf import numpy as np import matplotlib.pyplot as plt #%%图形绘制 ...
- Tensorflow学习教程------非线性回归
自己搭建神经网络求解非线性回归系数 代码 #coding:utf-8 import tensorflow as tf import numpy as np import matplotlib.pypl ...
- Tensorflow学习教程------利用卷积神经网络对mnist数据集进行分类_利用训练好的模型进行分类
#coding:utf-8 import tensorflow as tf from PIL import Image,ImageFilter from tensorflow.examples.tut ...
- Tensorflow学习教程------实现lenet并且进行二分类
#coding:utf-8 import tensorflow as tf import os def read_and_decode(filename): #根据文件名生成一个队列 filename ...
随机推荐
- MySQL 如何使用 PV 和 PVC?【转】
本节演示如何为 MySQL 数据库提供持久化存储,步骤为: 创建 PV 和 PVC. 部署 MySQL. 向 MySQL 添加数据. 模拟节点宕机故障,Kubernetes 将 MySQL 自动迁移到 ...
- 05.Delphi接口的多重继承深入
由于是IInterface,申明了SayHello,需要由继承类来实现函数,相对于03篇可以再精简一下 unit uSayHello; interface uses SysUtils, Windows ...
- yum 安装 tomcat
前言对于一个新安装的 centos 系统来说,是没有 tomcat 服务器的.用下面的命令可以查看 tomcat 服务的状态. systemctl status tomcat.service//或者 ...
- leetcode1143 Longest Common Subsequence
""" Given two strings text1 and text2, return the length of their longest common subs ...
- 解决fedora28桌面图标问题
正文 在fedora28中默认是没有桌面图标的,对于那些习惯使用桌面的图标的人来说使用有点不适应. 替代方法是: 下载nemo,在终端内输入sudo dnf install nemo 创建~/.con ...
- 一、Vue环境搭建及基础用法
一.项目初始化及安装 官网:https://cn.vuejs.org/ 1.1安装及运行项目步骤 1.安装vue-cli(-g=-global) npm install -g vue-cli cnpm ...
- POJ 1195:Mobile phones 二维树状数组
Mobile phones Time Limit: 5000MS Memory Limit: 65536K Total Submissions: 16893 Accepted: 7789 De ...
- HihoCoder#1052:基因工程
HihoCoder#1052:基因工程 时间限制:1000ms 单点时限:1000ms 内存限制:256MB 描述 小Hi和小Ho正在进行一项基因工程实验.他们要修改一段长度为N的DNA序列,使得这段 ...
- Codeforces 2A :winner
A. Winner time limit per test 1 second memory limit per test 64 megabytes input standard input outpu ...
- 通过fiddler修改通讯返回值
1 在fiddler里选中url,右键unlock for editing 2 在fiddler里点击url, 在右面的返回值的 TextView 项里修改数据 3 取消 unlock for e ...