2-10 就业课(2.0)-oozie:10、伪分布式环境转换为HA集群环境
hadoop 的基础环境增强 HA模式
HA是为了保证我们的业务 系统 7 *24 的连续的高可用提出来的一种解决办法,
现在hadoop当中的主节点,namenode以及resourceManager都已经实现了HA
如果active状态namenode出现故障,standBy状态的节点会检测到并代替active节点继续工作
常用的HA的实现方式:QJM的方式
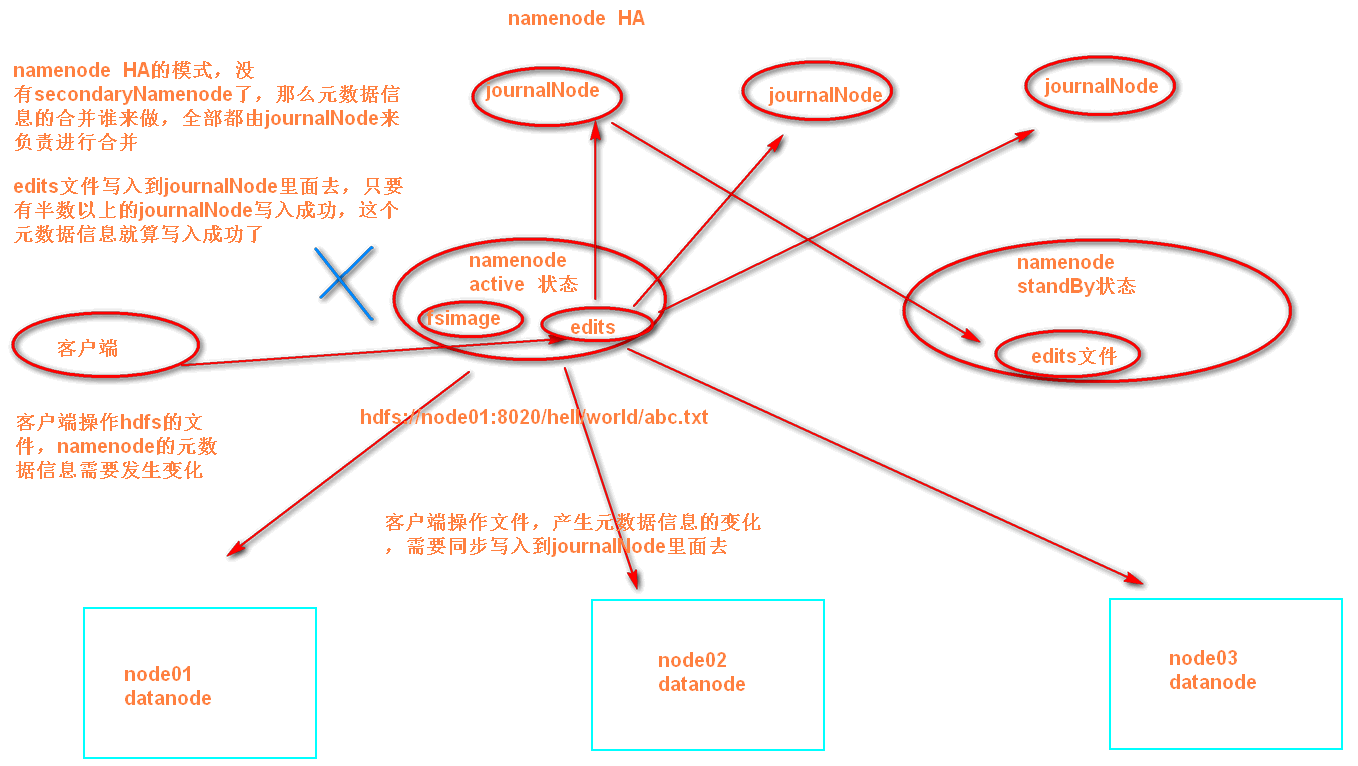
使用qjm的方式实现我们的namnode的HA就会出现一个问题,edits文件如何同步
zkFailoverController:监控namenode的健康状态 主要有以下三个功能 健康检测,会话管理,选举机制
将伪分布式模式,转换成高可用的模式,并且保证hdfs的数据的不丢失。

===========================================
7、hadoop基础环境增强
Hadoop High Availability
HA(High Available), 高可用,是保证业务连续性的有效解决方案,一般有两个或两个以上的节点,分为活动节点(Active)及备用节点(Standby)。通常把正在执行业务的称为活动节点,而作为活动节点的一个备份的则称为备用节点。当活动节点出现问题,导致正在运行的业务(任务)不能正常运行时,备用节点此时就会侦测到,并立即接续活动节点来执行业务。从而实现业务的不中断或短暂中断。
Hadoop1.X版本,NN是HDFS集群的单点故障点,每一个集群只有一个NN,如果这个机器或进程不可用,整个集群就无法使用。为了解决这个问题,出现了一堆针对HDFS HA的解决方案(如:Linux HA, VMware FT, shared NAS+NFS, BookKeeper, QJM/Quorum Journal Manager, BackupNode等)。
在HA具体实现方法不同情况下,HA框架的流程是一致的, 不一致的就是如何存储、管理、同步edits编辑日志文件。
在Active NN和Standby NN之间要有个共享的存储日志的地方,Active NN把edit Log写到这个共享的存储日志的地方,Standby NN去读取日志然后执行,这样Active和Standby NN内存中的HDFS元数据保持着同步。一旦发生主从切换Standby NN可以尽快接管Active NN的工作。
Namenode HA
Namenode HA详解
hadoop2.x之后,Clouera提出了QJM/Qurom Journal Manager,这是一个基于Paxos算法(分布式一致性算法)实现的HDFS HA方案,它给出了一种较好的解决思路和方案,QJM主要优势如下:
不需要配置额外的高共享存储,降低了复杂度和维护成本。
消除spof(单点故障)。
系统鲁棒性(Robust)的程度可配置、可扩展。
基本原理就是用2N+1台 JournalNode 存储EditLog,每次写数据操作有>=N+1返回成功时即认为该次写成功,数据不会丢失了。当然这个算法所能容忍的是最多有N台机器挂掉,如果多于N台挂掉,这个算法就失效了。这个原理是基于Paxos算法。
在HA架构里面SecondaryNameNode已经不存在了,为了保持standby NN时时的与Active NN的元数据保持一致,他们之间交互通过JournalNode进行操作同步。
任何修改操作在 Active NN上执行时,JournalNode进程同时也会记录修改log到至少半数以上的JN中,这时 Standby NN 监测到JN 里面的同步log发生变化了会读取 JN 里面的修改log,然后同步到自己的目录镜像树里面,如下图:

当发生故障时,Active的 NN 挂掉后,Standby NN 会在它成为Active NN 前,读取所有的JN里面的修改日志,这样就能高可靠的保证与挂掉的NN的目录镜像树一致,然后无缝的接替它的职责,维护来自客户端请求,从而达到一个高可用的目的。
在HA模式下,datanode需要确保同一时间有且只有一个NN能命令DN。为此:
每个NN改变状态的时候,向DN发送自己的状态和一个序列号。
DN在运行过程中维护此序列号,当failover时,新的NN在返回DN心跳时会返回自己的active状态和一个更大的序列号。DN接收到这个返回则认为该NN为新的active。
如果这时原来的active NN恢复,返回给DN的心跳信息包含active状态和原来的序列号,这时DN就会拒绝这个NN的命令。
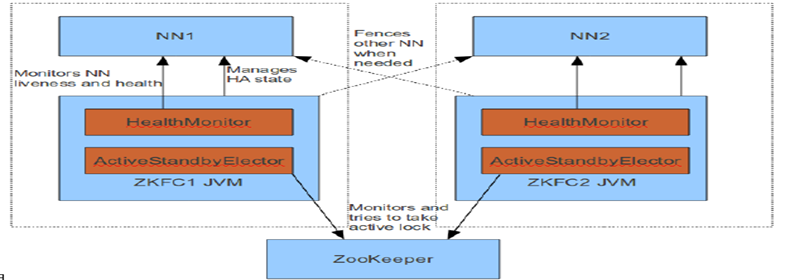
Failover Controller
HA模式下,会将FailoverController部署在每个NameNode的节点上,作为一个单独的进程用来监视NN的健康状态。FailoverController主要包括三个组件:
HealthMonitor: 监控NameNode是否处于unavailable或unhealthy状态。当前通过RPC调用NN相应的方法完成。
ActiveStandbyElector: 监控NN在ZK中的状态。
ZKFailoverController: 订阅HealthMonitor 和ActiveStandbyElector 的事件,并管理NN的状态,另外zkfc还负责解决fencing(也就是脑裂问题)。
上述三个组件都在跑在一个JVM中,这个JVM与NN的JVM在同一个机器上。但是两个独立的进程。一个典型的HA集群,有两个NN组成,每个NN都有自己的ZKFC进程。
ZKFailoverController主要职责:
l 健康监测:周期性的向它监控的NN发送健康探测命令,从而来确定某个NameNode是否处于健康状态,如果机器宕机,心跳失败,那么zkfc就会标记它处于一个不健康的状态
l 会话管理:如果NN是健康的,zkfc就会在zookeeper中保持一个打开的会话,如果NameNode同时还是Active状态的,那么zkfc还会在Zookeeper中占有一个类型为短暂类型的znode,当这个NN挂掉时,这个znode将会被删除,然后备用的NN将会得到这把锁,升级为主NN,同时标记状态为Active
l 当宕机的NN新启动时,它会再次注册zookeper,发现已经有znode锁了,便会自动变为Standby状态,如此往复循环,保证高可靠,需要注意,目前仅仅支持最多配置2个NN
l master选举:通过在zookeeper中维持一个短暂类型的znode,来实现抢占式的锁机制,从而判断那个NameNode为Active状态
Yarn HA
Yarn作为资源管理系统,是上层计算框架(如MapReduce,Spark)的基础。在Hadoop 2.4.0版本之前,Yarn存在单点故障(即ResourceManager存在单点故障),一旦发生故障,恢复时间较长,且会导致正在运行的Application丢失,影响范围较大。从Hadoop 2.4.0版本开始,Yarn实现了ResourceManager HA,在发生故障时自动failover,大大提高了服务的可靠性。
ResourceManager(简写为RM)作为Yarn系统中的主控节点,负责整个系统的资源管理和调度,内部维护了各个应用程序的ApplictionMaster信息、NodeManager(简写为NM)信息、资源使用等。由于资源使用情况和NodeManager信息都可以通过NodeManager的心跳机制重新构建出来,因此只需要对ApplicationMaster相关的信息进行持久化存储即可。
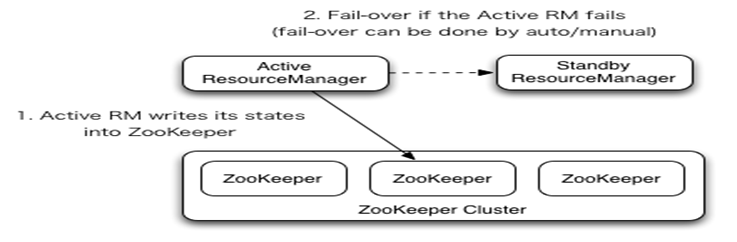
在一个典型的HA集群中,两台独立的机器被配置成ResourceManger。在任意时间,有且只允许一个活动的ResourceManger,另外一个备用。切换分为两种方式:
手动切换:在自动恢复不可用时,管理员可用手动切换状态,或是从Active到Standby,或是从Standby到Active。
自动切换:基于Zookeeper,但是区别于HDFS的HA,2个节点间无需配置额外的ZFKC守护进程来同步数据。
Hadoop HA集群的搭建
如何在已有的节点上面搭建HA高可用集群
集群服务规划:
|
机器ip |
192.168.52.100 |
192.168.52.110 |
192.168.52.120 |
|
主机名称 |
node01.hadoop.com |
node02.hadoop.com |
node03.hadoop.com |
|
NameNode |
是(active) |
是(standBy) |
否 |
|
DataNode |
是 |
是 |
是 |
|
journalNode |
是 |
是 |
是 |
|
ZKFC |
是 |
是 |
否 |
|
ResourceManager |
否 |
是(standBy) |
是(active) |
|
NodeManager |
是 |
是 |
是 |
|
zookeeper |
是 |
是 |
是 |
|
jobHistory |
是 |
第一步:停止服务
停止hadoop集群的所有服务,包括HDFS的服务,以及yarn集群的服务,包括impala的服务,hive的服务以及oozie的服务等
停止oozie服务
node03停止oozie服务
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozied.sh stop
停止hue服务
node03停止hue的服务
停止impala服务
直接使用kill -9杀死进程即可
node03停止impala相关服务
service impala-catalog stop
service impala-state-store stop
service impala-server stop
node02停止impala相关服务
service impala-server stop
node01停止impala相关服务
service impala-server stop
停止hive服务
node03停止hive服务
通过kill命令直接杀死相关hive进程即可
停止hadoop服务
node01机器执行以下命令停止hadoop服务
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/stop-dfs.sh
sbin/stop-yarn.sh
sbin/mr-jobhistory-daemon.sh stop historyserver
第二步:启动所有节点的zookeeper服务
cd /export/servers/zookeeper-3.4.5-cdh5.14.0
bin/zkServer.sh start
第三步:更改配置文件
所有节点修改配置文件,注意yarn-site.xml当中的
yarn.resourcemanager.ha.id 这个属性值,node03机器与node02机器的配置值不太一样
修改core-site.xml
<!--
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.52.100:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/tempDatas</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
-->
<property>
<name>ha.zookeeper.quorum</name>
<value>node01.hadoop.com:2181,node02.hadoop.com:2181,node03.hadoop.com:2181</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hann</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/tempDatas</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
修改hdfs-site.xml
<!-- NameNode存储元数据信息的路径,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<!-- 集群动态上下线
<property>
<name>dfs.hosts</name>
<value>/export/servers/hadoop-2.7.4/etc/hadoop/accept_host</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/export/servers/hadoop-2.7.4/etc/hadoop/deny_host</value>
</property>
-->
<!--
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/snn/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/var/run/hdfs-sockets/dn</value>
</property>
<property>
<name>dfs.client.file-block-storage-locations.timeout.millis</name>
<value>10000</value>
</property>
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
-->
<property>
<name>dfs.nameservices</name>
<value>hann</value>
</property>
<property>
<name>dfs.ha.namenodes.hann</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hann.nn1</name>
<value>node01.hadoop.com:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hann.nn2</name>
<value>node02.hadoop.com:8020</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.hann.nn1</name>
<value>node01.hadoop.com:8022</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.hann.nn2</name>
<value>node02.hadoop.com:8022</value>
</property>
<property>
<name>dfs.namenode.http-address.hann.nn1</name>
<value>node01.hadoop.com:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.hann.nn2</name>
<value>node02.hadoop.com:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01.hadoop.com:8485;node02.hadoop.com:8485;node03.hadoop.com:8485/hann</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/jn</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.hann</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/var/run/hdfs-sockets/dn</value>
</property>
<property>
<name>dfs.client.file-block-storage-locations.timeout.millis</name>
<value>10000</value>
</property>
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
修改mapred-site.xml
<!--
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
-->
<!--
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.type</name>
<value>RECORD</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
-->
<!--指定运行mapreduce的环境是yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MapReduce JobHistory Server IPC host:port -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node03:10020</value>
</property>
<!-- MapReduce JobHistory Server Web UI host:port -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node03:19888</value>
</property>
<!-- The directory where MapReduce stores control files.默认 ${hadoop.tmp.dir}/mapred/system -->
<property>
<name>mapreduce.jobtracker.system.dir</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/jobtracker</value>
</property>
<!-- The amount of memory to request from the scheduler for each map task. 默认 1024-->
<property>
<name>mapreduce.map.memory.mb</name>
<value>1024</value>
</property>
<!-- <property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024m</value>
</property> -->
<!-- The amount of memory to request from the scheduler for each reduce task. 默认 1024-->
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>1024</value>
</property>
<!-- <property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2048m</value>
</property> -->
<!-- 用于存储文件的缓存内存的总数量,以兆字节为单位。默认情况下,分配给每个合并流1MB,给个合并流应该寻求最小化。默认值100-->
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>100</value>
</property>
<!-- <property>
<name>mapreduce.jobtracker.handler.count</name>
<value>25</value>
</property>-->
<!-- 整理文件时用于合并的流的数量。这决定了打开的文件句柄的数量。默认值10-->
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>10</value>
</property>
<!-- 默认的并行传输量由reduce在copy(shuffle)阶段。默认值5-->
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>25</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx1024m</value>
</property>
<!-- MR AppMaster所需的内存总量。默认值1536-->
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>1536</value>
</property>
<!-- MapReduce存储中间数据文件的本地目录。目录不存在则被忽略。默认值${hadoop.tmp.dir}/mapred/local-->
<property>
<name>mapreduce.cluster.local.dir</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/mapreduce/local</value>
</property>
修改yarn-site.xml
注意:yarn.resourcemanager.ha.id 这个属性的配置,node03的这个属性值与node02的这个属性值内容不同
<!--
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
-->
<!-- Site specific YARN configuration properties -->
<!-- 是否启用日志聚合.应用程序完成后,日志汇总收集每个容器的日志,这些日志移动到文件系统,例如HDFS. -->
<!-- 用户可以通过配置"yarn.nodemanager.remote-app-log-dir"、"yarn.nodemanager.remote-app-log-dir-suffix"来确定日志移动到的位置 -->
<!-- 用户可以通过应用程序时间服务器访问日志 -->
<!-- 启用日志聚合功能,应用程序完成后,收集各个节点的日志到一起便于查看 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--开启resource manager HA,默认为false-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 集群的Id,使用该值确保RM不会做为其它集群的active -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>mycluster</value>
</property>
<!--配置resource manager 命名-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 配置第一台机器的resourceManager -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node03.hadoop.com</value>
</property>
<!-- 配置第二台机器的resourceManager -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node02.hadoop.com</value>
</property>
<!-- 配置第一台机器的resourceManager通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>node03.hadoop.com:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>node03.hadoop.com:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>node03.hadoop.com:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>node03.hadoop.com:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node03.hadoop.com:8088</value>
</property>
<!-- 配置第二台机器的resourceManager通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>node02.hadoop.com:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>node02.hadoop.com:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>node02.hadoop.com:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>node02.hadoop.com:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node02.hadoop.com:8088</value>
</property>
<!--开启resourcemanager自动恢复功能-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--在node3上配置rm1,在node2上配置rm2,注意:一般都喜欢把配置好的文件远程复制到其它机器上,但这个在YARN的另一个机器上一定要修改,其他机器上不配置此项-->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
<description>If we want to launch more than one RM in single node, we need this configuration</description>
</property>
<!--用于持久存储的类。尝试开启-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node01.hadoop.com:2181,node02.hadoop.com:2181,node03.hadoop.com:2181</value>
<description>For multiple zk services, separate them with comma</description>
</property>
<!--开启resourcemanager故障自动切换,指定机器-->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
<description>Enable automatic failover; By default, it is enabled only when HA is enabled.</description>
</property>
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value>
</property>
<!-- 允许分配给一个任务最大的CPU核数,默认是8 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<!-- 每个节点可用内存,单位MB -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>512</value>
</property>
<!-- 单个任务可申请最少内存,默认1024MB -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 单个任务可申请最大内存,默认8192MB -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>512</value>
</property>
<!--多长时间聚合删除一次日志 此处-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>2592000</value><!--30 day-->
</property>
<!--时间在几秒钟内保留用户日志。只适用于如果日志聚合是禁用的-->
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>604800</value><!--7 day-->
</property>
<!--指定文件压缩类型用于压缩汇总日志-->
<property>
<name>yarn.nodemanager.log-aggregation.compression-type</name>
<value>gz</value>
</property>
<!-- nodemanager本地文件存储目录-->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/yarn/local</value>
</property>
<!-- resourceManager 保存最大的任务完成个数 -->
<property>
<name>yarn.resourcemanager.max-completed-applications</name>
<value>1000</value>
</property>
<!-- 逗号隔开的服务列表,列表名称应该只包含a-zA-Z0-9_,不能以数字开始-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--rm失联后重新链接的时间-->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
改完之后,将配置文件分发到其他的各个节点
还要记得改node02机器的yarn-site.xml
第四步:服务的启动
第一步:初始化zookeeper
在node01机器上进行zookeeper的初始化,其本质工作是创建对应的zookeeper节点
cd /export/servers/hadoop-2.6.0-cdh5.14.0
bin/hdfs zkfc -formatZK
第二步:启动journalNode
三台机器执行以下命令启动journalNode,用于我们的元数据管理
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/hadoop-daemon.sh start journalnode
第三步:初始化journalNode
node01机器上准备初始化journalNode
cd /export/servers/hadoop-2.6.0-cdh5.14.0
bin/hdfs namenode -initializeSharedEdits -force
第四步:启动namenode
node01机器上启动namenode
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/hadoop-daemon.sh start namenode
node02机器上启动namenode
cd /export/servers/hadoop-2.6.0-cdh5.14.0
bin/hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode
第五步:启动所有节点的datanode进程
在node01机器上启动所有节点的datanode进程
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/hadoop-daemons.sh start datanode
第六步:启动zkfc
在node01机器上面启动zkfc进程
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/hadoop-daemon.sh start zkfc
在node02机器上面启动zkfc进程
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/hadoop-daemon.sh start zkfc
第七步:启动yarn进程
node03机器上启动yarn集群
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/start-yarn.sh
node02机器上启动yarn集群
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/start-yarn.sh
第八步:启动jobhsitory
node03节点启动jobhistoryserver
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/mr-jobhistory-daemon.sh start historyserver
2-10 就业课(2.0)-oozie:10、伪分布式环境转换为HA集群环境的更多相关文章
- 2-10 就业课(2.0)-oozie:9、oozie与hue的整合,以及整合后执行MR任务
5.hue整合oozie 第一步:停止oozie与hue的进程 通过命令停止oozie与hue的进程,准备修改oozie与hue的配置文件 第二步:修改oozie的配置文件(老版本的bug,新版本已经 ...
- 2-10 就业课(2.0)-oozie:8、定时任务的执行
4.5.oozie的任务调度,定时任务执行 在oozie当中,主要是通过Coordinator 来实现任务的定时调度,与我们的workflow类似的,Coordinator 这个模块也是主要通过xml ...
- 2-10 就业课(2.0)-oozie:12、cm环境搭建的基础环境准备
8.clouderaManager5.14.0环境安装搭建 Cloudera Manager是cloudera公司提供的一种大数据的解决方案,可以通过ClouderaManager管理界面来对我们的集 ...
- 2-10 就业课(2.0)-oozie:13、14、clouderaManager的服务搭建
3.clouderaManager安装资源下载 第一步:下载安装资源并上传到服务器 我们这里安装CM5.14.0这个版本,需要下载以下这些资源,一共是四个文件即可 下载cm5的压缩包 下载地址:htt ...
- 2-10 就业课(2.0)-oozie:2、介绍和安装1
oozie的安装及使用 1. oozie的介绍 Oozie是运行在hadoop平台上的一种工作流调度引擎,它可以用来调度与管理hadoop任务,如,MapReduce.Pig等.那么,对于Oozie ...
- 2-10 就业课(2.0)-oozie:5、通过oozie执行hive的任务
4.2.使用oozie调度我们的hive 第一步:拷贝hive的案例模板 cd /export/servers/oozie-4.1.0-cdh5.14.0 cp -ra examples/apps/h ...
- 2-10 就业课(2.0)-oozie:7、job任务的串联
4.4.oozie的任务串联 在实际工作当中,肯定会存在多个任务需要执行,并且存在上一个任务的输出结果作为下一个任务的输入数据这样的情况,所以我们需要在workflow.xml配置文件当中配置多个ac ...
- 2-10 就业课(2.0)-oozie:6、通过oozie执行mr任务,以及执行sqoop任务的解决思路
执行sqoop任务的解决思路(目前的问题是sqoop只安装在node03上,而oozie会随机分配一个节点来执行任务): ======================================= ...
- 2-10 就业课(2.0)-oozie:4、通过oozie执行shell脚本
oozie的配置文件job.properties:里面主要定义的是一些key,value对,定义了一些变量,这些变量往workflow.xml里面传递workflow.xml :workflow的配置 ...
随机推荐
- rem布局,在用户调整手机字体大小/用户调整浏览器字体大小后,布局错乱问题
一.用户调整浏览器字体大小,影响的是从浏览器打开的web页. 浏览器设置字体大小,影响浏览器打开的页面.通过js可控制用户修改字体大小,使页面不受影响. (function(doc, win) { / ...
- [运维] 如何访问虚拟机上的 Tomcat ?
环境: 虚拟机: VMware 15 pro 操作系统 Linux CentOS 7 64 物理机: Windows 7 事先准备: 1: 下载 Tomcat 的压缩包 apache-t ...
- java finalize学习
1 finalize()调用的时机 与C++的析构函数(对象在清除之前析构函数会被调用)不同,在Java中,由于GC的自动回收机制,因而并不能保证finalize方法会被及时地执行(垃圾对象的回收时机 ...
- element-ui的el-table的表头与列不对齐
最好加到全局样式中: body .el-table th.gutter{ display: table-cell!important; }
- 无线渗透之ettercap
无线渗透之ettercap ettercap命令查看 # ettercap -h Usage: ettercap [OPTIONS] [TARGET1] [TARGET2] TARGET is in ...
- Java基础 -5.3
方法的递归调用 指的是一个方法自己调用自己的情况,利用递归调用可以解决一些重复且麻烦的问题 在进行我们递归调用的时候一般要考虑如下几点问题 一定要设置方法递归调用的结束条件 每一次调用的过程之中一定要 ...
- 二次代价函数、交叉熵(cross-entropy)、对数似然代价函数(log-likelihood cost)(04-1)
二次代价函数 $C = \frac{1} {2n} \sum_{x_1,...x_n} \|y(x)-a^L(x) \|^2$ 其中,C表示代价函数,x表示样本,y表示实际值,a表示输出值,n表示样本 ...
- bootloader与启动地址偏移
如果项目工程是IAP+APP,则在keil的APP中要么在修改IROM/IRAM的开始地址和大小,并在MAP中勾选设置. 在NVIC中修改system_stm32f10x.c修改 这个在void Sy ...
- Rcnn/Faster Rcnn/Faster Rcnn的理解
基于候选区域的目标检测器 1. 滑动窗口检测器 根据滑动窗口从图像中剪切图像块-->将剪切的图像块warp成固定大小-->cnn网络提取特征-->SVM和regressor进行分类 ...
- Codeforces1301D
其实感觉这道题在D简单了(但我都没做到这一题,路径最多的方式只有一种,将所有的边都走一遍,从第一行开始,向右走到头,然后向左回来,向下一格,向右走到头,然后上下左重复直到第一列,如此重复直到最后一行, ...