[ APUE ] 第三章 文件系统
1. 文件描述符
打开或创建一个文件时,内核向进程返回一个文件描述符,当读、写一个文件时,用open()或creat()返回的文件描述符标识该文件,将其作为参数传递给write、read。
| stdin标准输入 | fd = 0 |
|---|---|
| stdout标准输出 | fd = 1 |
| stderr标准错误 | fd = 2 |
为了可读性可以用 STDIN_FILENO,STDOUT_FILENO,STDERR_FILENO宏来表示。这些宏在<unistd.h>中定义。
文件描述符的变化范围 :0~OPEN_MAX-1
2. open 和 openat
#include<fcntl.h>
int open(const char *pathname, int flags);
int openat(int dirfd, const char *pathname, int flags);
负责**打开或创建**一个文件,成功返回文件描述符,失败返回 -1
path: 要打开或创建文件的名字。
oflag参数用于说明函数选项,以下一个或多个宏用或运算来表示参数:



open和openat函数返回的文件描述符一定是 最小未使用描述符 。
openat的几种使用情况:
path如果是绝对路径名,则忽略dirfd。open = openat
path如果是相对路径名,dirfd指出了相对路径名在文件系统中的开始地址。
path如果是相对路径名,fd参数具有特殊值AT_FDCWD,则路径名在当前工作目录中获取。
openat的存在的意义?
线程可以使用相对路径名打开目录中的文件,而不仅仅局限于当前工作目录。让多个线程工作在不同的目录。(但是似乎新版的open里是可以通过相对路径来打开文件的,不知这里是否是老版本的问题)。
避免TOCTTOU错误(time-of-check-to-time-of-use).
TOCTTOU错误是指:如果有两个基于文件的系统调用,其中第二个依赖于第一个,那么程序是脆弱的。因为这两次调用不是原子操作,中间可能会发生 第一个调用的结果被改变 导致第二个调用的结果不正确。
文件名超出NAME_MAX(现在大多是255),会出错返回并设置errno为 ENAMETOOLONG。
3. creat函数
#include<fcntl.h>
int creat(const char *pathname, mode_t mode);
成功返回文件描述符,失败返回-1. mode参数可以是O_CREAT选项下对文件的权限设置。
此函数等价于:
open(path,O_WRONLY|O_CREAT|O_TRUNC,mode);
以前open的选项参数只有0,1,2,所以只需要用creat。
creat只能以只写的方式打开创建的文件,所以要读写文件的话必须先creat,再close,再open,很麻烦,现在可以用这个代替。
open(path,O_RDWR|O_CREAT|O_TRUNC,mode);
4. close函数
#include<unistd.h>
int close(int fd);
关闭一个文件同时也会释放文件的所有记录锁。
当一个进程终止时,内核会自动关闭他打开的文件,所以很多程序不显式调用close函数。
5. lseek函数
#include<unistd.h>
off_t lseek(int fd, off_t offset, int whence);
成功返回当前文件偏移量,出错返回-1.
每一个打开的文件都有一个与之关联的 “当前文件偏移量”,非负整数,计算从文件开始处经历的字节数。通常,读写操作都是从当前文件偏移量处开始,并使偏移量增加所读写字节数。
打开文件时的默认偏移量一般是0,除非使用O_APPEND选项。
offset参数与whence参数之间的关系:
- 若whence = SEEK_SET, 将当前文件偏移量设置为 距文件开始处offset个字节。
- 若whence = SEEK_CUR, 将当前文件偏移量设置为 偏移量当前值+offset个字节。
- 若whence = SEEK_END, 将当前文件偏移量设置为 文件长度+offset个字节。
offset_t curpos = lseek(fd,0,SEET_CUR); 可以用于判断文件的当前文件偏移量。
同时也可以用于判断fd对应的文件能否设置文件偏移量。如果是stdin/stdout/FIFO/PIPE/socket都是不行的,返回-1.
对于某些文件(设备)支持负的偏移量,所以比较返回值的时候不要用<0,而是用== -1.
lseek将当前文件偏移量存在内核里,下次读写时使用,但是它本身不读写。
文件偏移量可以大于文件长度,下一次写入将加长文件,这会导致文件中形成一个空洞,范围是从文件的旧末尾到当前文件偏移量,这里的内容读出来都是0,但实际上空洞并不一定占据存储空间,新写入的数据分配磁盘块,但空洞是没必要分配磁盘块的,这与文件系统的实现有关。
可使用以下代码创建空洞:
int main(){
int fd;
if((fd = open("test",O_RDWR|O_CREAT|O_TRUNC,777))==-1){
err_sys("usage:open:");
}
if(write(fd,"12345",5)==-1){
err_sys("usage:write:");
}
if(lseek(fd,100,SEEK_CUR)==-1){
err_sys("usage:open:");
}
if(write(fd,"12345",5)==-1){
err_sys("usage:write:");
}
}
使用od命令观察。
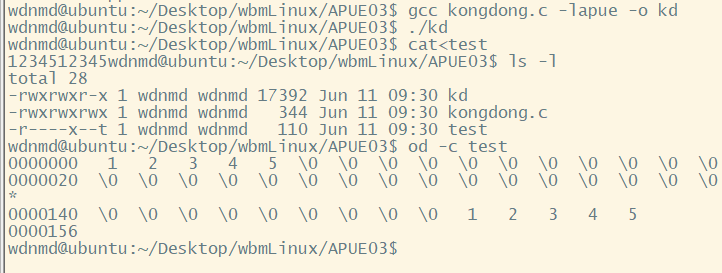
把偏移量调到10000,发现有空洞文件只分配了8个磁盘块。(使用fallocate -l),而没空洞的10000大小的文件占了12个盘块。

文件偏移量可以使用64位的off_t,但是它的大小和文件大小没有必然关系,能创建多大的文件取决于底层的文件系统!
6. read函数
#include<unistd.h>
ssize_t read(int fd, void *buf, size_t count);
成功返回读取字节数,出错返回-1,如果到达文件末尾返回0.(ssize_t 有符号整型,size_t 无符号整型)
造成读取字节数小于要求字节数的情况:
- 偏移量与文件末尾距离大于要求字节数。
- 终端设备通常一次最多读一行
- 从网络读,缓冲机制导致返回值小于要求字节数
- 从管道或FIFO读,里面包含多的字节数小于要求的字节数,返回实际读取值
- 从面向记录的设备读(如磁带),一次最多返回一个记录。
- 中断信号
7. write函数
#include<unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
成功返回写入字节数,失败返回-1.
返回值一般与count大小相同,否则出错。一般是因为硬盘已满或超过给定进程的文件长度限制。
write和read都会改变文件偏移量!
8. I/O的效率
大多数文件系统为改善性能都采取了预读的技术,即当系统检测到正在顺序读取时,实际每次读取字节比要求读取字节数多,用于减少读取次数。
提高缓冲区大小也可以提高效率,但一般大到磁盘块大小就接近瓶颈了。
core dump的由来:早期主存用的是铁氧体磁芯(ferrite core),所以有了core dump这么一说,即内存映像,把程序的内存的镜像存在一个文件里便于测试和诊断问题。
多次读取的文件时,os会把文件暂存在内存里便于读取,之后的读写速度可能好于第一次。但是不同缓冲区长度下进行的读取,其存在内存里的副本是不一样的,所以没有好的影响。
9. 文件共享
内核使用3种数据结构表示打开文件,它们之间的关系表示了文件共享方面一个进程对另一个进程的可能的影响。
每个进程在进程表中都有一个记录项,记录项中包含一张打开文件描述符表。
每个描述符表相关联的是:
a. 文件描述符标志(close_on_exec)
b. 指向一个文件表项的指针。
内核为所有打开的文件维护一个文件表,每个表包括:
a. 文件状态标志
b. 当前文件偏移量
c. 指向该文件v节点表项的指针。
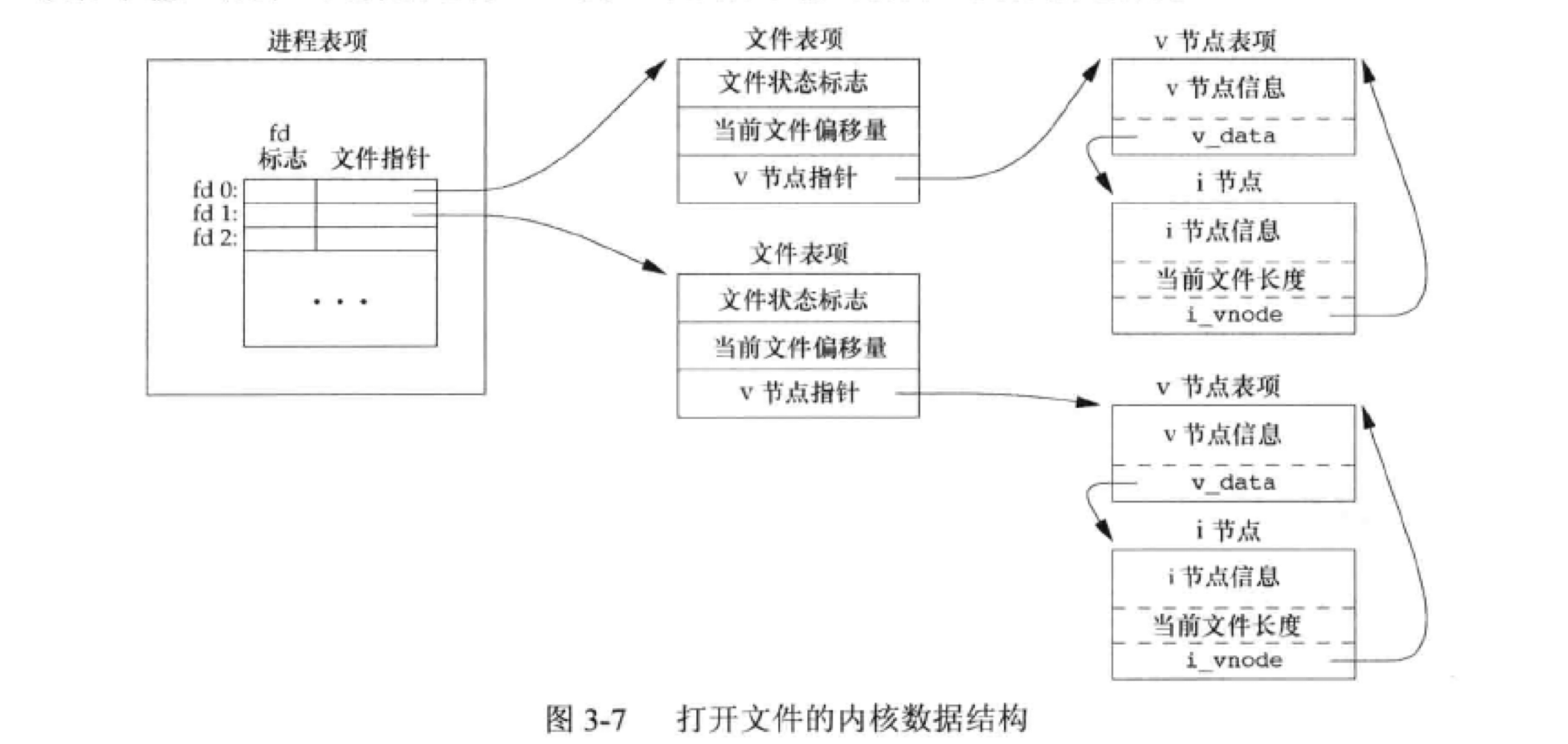
3. 每个文件都有一个v节点(v_node)数据结构。它包含了当前文件类型和对此文件进行各种操作的函数的指针。对于大多数文件,v节点还包含了该文件的i节点(i_node,索引节点)。这些数据结构里的内容打开文件的时候从磁盘上读到内存的。(Linux没有使用v节点)
v节点的出现时为了对多文件系统类型提供支持,它被称为虚拟文件系统,v节点就是与文件系统无关的i节点部分。linux实现的时候,使用了与文件系统相关的i节点和与文件系统无关的i节点。
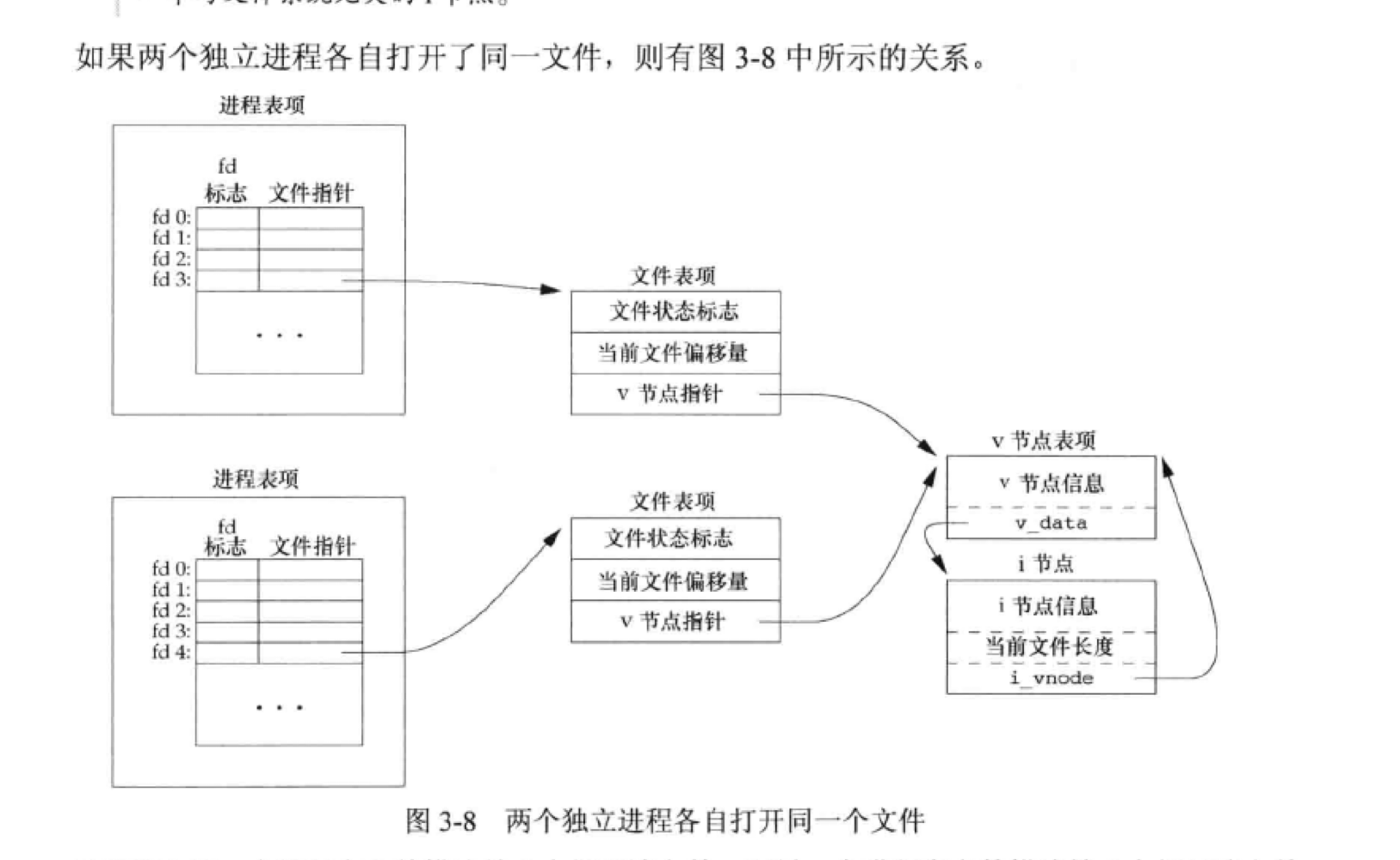
如图,进程1在fd3上打开该文件,进程2在fd4上打开该文件。打开该文件的每个进程都获得各自的一个文件表项。文件表项又指向同一个v节点表项(因为一个文件只有一个v节点),每个进程的文件表项不同是为了获取不同的偏移量。
当然,也可能出现多个fd指向同一个文件表项的情况,比如,可以用dup复制fd。fork也行,父子进程的文件描述符共享同一个文件表项。
文件描述符是对某一个进程来说的,而文件状态标志影响的是所有指向该文件表项的进程。
10. 原子操作
1.追加到一个文件
假设A、B两个进程都在对一个文件进行追加写入,但不是通过open并采用O_APPEND选项,而是采取古老的lseek+write的方式进行,但是这么做,可能会出现lseek已执行,write未执行,但文件尾端被修改(文件增长了),它再write,就修改了里面的内容,这不是我们想要的。所以我们需要将找文件末尾对应的偏移量+写入作为一个原子操作进行。
(任何一个多于一个函数的调用操作都不是原子操作,因为进程可能会被挂起)
#include <unistd.h>
ssize_t pread(int fd, void *buf, size_t count, off_t offset);
成功返回读取字节数,失败返回-1,若到文件尾返回0
ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset);
成功返回实际写入字节数,失败返回-1
pread类似于 lseek+read操作,但是有所不同:
- 调用pread不能中断定位和读操作
- 不更新当前文件表项的偏移量
pwrite也类似。
2. 创建文件
open时采用O_CREAT|O_EXCL两个选项,用于将创建文件和测试文件是否存在合并为一个原子操作。不原子的操作可参见open->(errno == ENOENT)-> creat.
原子操作指多步组成的一个操作,只能全部执行或不执行,不可能只执行其子集。
11. dup和dup2函数
#include<unistd.h>
int dup(int fd);
int dup2(int fd,int fd2);
成功返回新的fd,失败返回-1.
dup返回的新文件描述符一定是当前可用文件描述符中的最小数值。
dup2可以用fd2参数指定新描述符的值。如果fd2已经打开就关闭,如果fd==fd2,则返回fd2而不关闭。其他情况下,fd2的FD_CLOEXEC文件描述符标志被清除,这样fd在进程调用exec时是打开状态。
这两个函数的参数fd与返回的fd共享同一个文件表项。
每一个fd都有自己的文件描述符标志,正如新描述符的执行时关闭(close-on-exec)标志总是由dup函数清除。
复制一个文件描述符的另一种方式是使用fcntl()函数:
实际上 dup(fd) ;等效于 fcntl(fd,F_DUPFD,0);
dup2(fd,fd2);(不严格)等效于 close(fd2); fcntl(fd,F_DUPFD,fd2);,因为:
dup2是原子的,如果close和fcntl之间调用了信号捕获函数,它可能会修改文件描述符;或者不同的线程也可能会修改。
dup2和fcntl有一些不同的errno
12. sync、fsync和fdatasync
unix内核中设有缓冲区高速缓存或者页高速缓存,大多数硬盘I/O都通过。当我们向文件写入数据时,内核先将数据存到缓冲区,然后排入队列,之后再写入硬盘。这种方式称作延迟写 (delay write)。
当内核需要重用缓冲区存入其他磁盘块数据时,他会将所有延迟写数据写入磁盘。为了保证磁盘上的实际内容与缓冲区内容一致,unix提供了sync、fsync和fdatasync三个函数。
#include <unistd.h>
void sync(void);
int fsync(int fd);
int fdatasync(int fd);
sync只是将修改过的块缓冲区排入写队列,然后返回,它不等待实际写硬盘操作结束。
update 系统守护进程周期性调用sync函数。保证定期flush内核的块缓冲区。命令sync也是调动sync函数。
fsync函数只对fd对应文件起作用,并且等待实际写硬盘操作结束,fsync可用于数据库,确保修改过的块立即写到硬盘上。
fdatasync类似fsync,但只影响文件的数据部分。fsync还会同步文件的属性。
13. fcntl函数
#include<fcntl.h>
int fcntl(int fd, int cmd, ... /* arg */ );
成功则返回结果依赖于cmd,失败返回-1.
fcntl函数有以下几种功能;
复制已有描述符(cmd = F_DUPFD或F_DUPFD_CLOEXEC)
获取、设置文件描述符标志(cmd = F_GETFD/F_SETFD)
获取、设置文件状态标志(cmd = F_GETFL /F_SETFL)
获取、设置异步IO所有权(cmd = F_GETOWN/F_SETOWN)
获取、设置记录锁( cmd = F_GETLK/F_SETLK或F_SETLKW)


O_SYNC可以保证等待文件IO完成,即已写到硬盘上再返回。unix系统中,write通常只把数据排入队列,实际写入硬盘可能在以后某个时刻进行,但数据库系统要防止系统异常导致队列中数据丢失,所以需要write一返回就能确定数据确实写入硬盘。
F_SETFL/F_GETFL 都很重要,可以用这俩写个set_fl和get_fl函数。
O_SYNC标志会增加系统时间和时钟时间。
linux系统不允许通过fcntl函数打开O_SYNC选项,但是只提示失败不返回出错。(所以没设的话就老老实实调fsync或fdatasync )。
14.ioctl函数
#include <sys/ioctl.h>
int ioctl(int fd, unsigned long request, ...);
它是IO操作的杂物箱,终端IO操作用它比较多。
它虽然是不定参数的,但参数一般只有一个,一般是指向一个变量或结构的指针。
每个设备驱动程序可以定义它自己的一组专用ioctl命令。系统则为不同种类设备提供通用ioctl命令。
15. /dev/fd
打开/dev/fd/n等效于复制描述符n(若描述符n打开)。
fd = open("/dev/fd/0",mode); 等效于 fd = dup(0);
打开文件的mode必须是初始打开模式的一个子集,多的会被忽略,不报错。
fd = open("/dev/fd/0",O_RDWR); 即便这样stdin还是只读。
不过linux的实现比这个要特别,它不是忽略,而是/dev/fd里的文件描述符被映射指向底层文件的符号链接,所以返回的fd的mode和/dev/fd本身的mode无关。
习题以后再补
来了来了 2020.6.12 23:26
第一题
读写文件时,本章的函数没有缓冲机制么?个人想法: 怎么可能没缓冲,内核应该有吧,设备驱动程序也应该有吧。。。。
标答:所有硬盘IO都要经过内核的块缓存器,唯一例外的是对原始磁盘设备的IO,但是我们不考虑这种情况。本章“无缓存的IO”实际是指用户进程不会对读写自动缓存。第二题
不用fcntl编写一个功能和dup2一样的函数,并做好出错处理。细节还蛮复杂的,参考一下这个
基本思路就是close+dup组合,其中注意处理原fd和要更换指向的fd相等情况(直接返回);正常情况下注意dup返回的fd是最小的,不一定是我们目标fd,所以要while循环一波直到获得我们想要的,然后把多复制的全关了。(dup改变指向的的一定是最小的空闲fd,这个思想必须牢牢把握!)第三题

图没必要画,没啥技术含量。。
F_SETFD只影响fd1;F_SETFL影响fd1,fd2。为啥?自己想。第四题
题目和答案都奇奇怪怪,没啥难度和意思。第五题
Bourne shell Bourne-again shell,Korn shell中,digit1>&digit2表示把描述符digit1重定位到描述符digit2。说明下面两条命令的区别:
./a.out > outfile 2>&1;
./a.out 2>&1 > outfile;
个人想法:第一句是 进程标准输出重定向到outfile,再把标准错误重定向到标准输出。第二句是 标准错误重定向到标准输出,标准输出重定向到outfile。一个是stdout和stderr都向outfile输出,一个是stderr向原来的标准输出流fd输出,stdout向outfile输出。第六题
用追加标志打开文件进行读写,能否用lseek从任一位置读,能否用lseek更新文件任一部分数据?
lseek和read可以,但write不行,因为write会自动把偏移量设置为文件尾部,因此写文件只能从文件尾开始。
[ APUE ] 第三章 文件系统的更多相关文章
- 【转】《APUE》第三章笔记(4)及习题3-2
原文网址:http://www.cnblogs.com/fusae-blog/p/4256794.html APUE第三章的最后面给出的函数,现在还用不着,所以,先留个名字,待到时候用着了再补上好了. ...
- 《APUE》第三章笔记(4)及习题3-2
APUE第三章的最后面给出的函数,现在还用不着,所以,先留个名字,待到时候用着了再补上好了. dup和dup2函数:用来复制文件描述符的 sync函数,fsync函数和fdatasync函数:大致的功 ...
- 《APUE》第三章笔记(3)
文件共享 UNIX系统支持在不同进程中共享打开的文件,首先先用一幅apue的图来介绍一下内核用于I/O文件的数据结构: 如图所见,一个进程都会有一个记录项,记录项中包含有一张打开文件描述符表,每个描述 ...
- 《APUE》第三章笔记(2)
read函数 调用read函数从打开的文件中读数据. #include <unistd.h> ssize_t read(int filedes, void *buf, size_t nby ...
- 《APUE》第三章笔记(1)
以下内容是我看<APUE>第二版第三章的笔记,有错还希望指出来,谢谢. unbuffered I/O,跟buffered I/O相对,buffered I/O就是 ISO C标准下的标准输 ...
- 《Linux内核设计与实现》读书笔记 第三章 进程管理
第三章进程管理 进程是Unix操作系统抽象概念中最基本的一种.我们拥有操作系统就是为了运行用户程序,因此,进程管理就是所有操作系统的心脏所在. 3.1进程 概念: 进程:处于执行期的程序.但不仅局限于 ...
- Laxcus大数据管理系统2.0(5)- 第三章 数据存取
第三章 数据存取 当前的很多大数据处理工作,一次计算产生几十个GB.或者几十个TB的数据已是正常现象,驱动数百.数千.甚至上万个计算机节点并行运行也已经不足为奇.但是在数据处理的后面,对于这种在网络间 ...
- apue第七章学习总结
apue第七章学习总结 1.main函数 程序是如何执行有关的c程序的? C程序总是从main函数开始执行.main函数的原型是 int main(int argc,char *argv[]); 其中 ...
- 《Linux命令行与shell脚本编程大全》 第三章 学习笔记
第三章:基本的bash shell命令 bash程序使用命令行参数来修改所启动shell的类型 参数 描述 -c string 从string中读取命令并处理他们 -r 启动限制性shell,限制用户 ...
随机推荐
- [工具-007] C#手机短信发送
本工具是基于中国网建SMS短信通的API进行开发的,主要功能就是用注册的号码对指定的号码发送短信,此功能主要应用于企业营销方面. 中国网建SMS短信通http://www.smschinese.cn/ ...
- [Objective-C] 012_数据持久化_XML属性列表,NSUserDefaults
在日常开发中经常要对NSString.NSDictionary.NSArray.NSData.NSNumber这些基本类的数据进行持久化,我们可以用XML属性列表持久化到.plist 文件中,也可以用 ...
- Java中的集合(四)PriorityQueue常用方法
Java中的集合(四)PriorityQueue常用方法 PriorityQueue的基本概念等都在上一篇已说明,感兴趣的可以点击 Java中的集合(三)继承Collection的Queue接口 查看 ...
- 【书签】stacking、blending
读懂stacking:模型融合Stacking详解/Stacking与Blending的区别 https://blog.csdn.net/u014114990/article/details/5081 ...
- AVIRIS反射率数据简介
Surface Reflectance 高光谱图像 ↑ AVIRIS高光谱成像光谱仪采集得到的原始图像为辐亮度图像,经过校正后的L1级产品为地表辐亮度信息.但是许多时候,我们更希望知道地面目标物的反射 ...
- ES6-函数与数组命名
1 箭头函数 1.1 以往js function 名字(){ 其他语句 } 1.2 现在ES6 修正了一些this,以前this可以变 ()=>{ 其他语句 } 如果只有一个参数,()可以省 . ...
- Java面向对象 类与对象与方法的储存情况
栈.堆.方法区 类(含方法)储存在方法区 main函数入栈 堆里面存储方法区中类与方法的地址 main函数调用方法,找堆里面方法的地址,再从方法区找到对应函数,函数入栈,用完出栈 总结: 1.类.方法 ...
- Java实现 LeetCode 143 重排链表
143. 重排链表 给定一个单链表 L:L0→L1→-→Ln-1→Ln , 将其重新排列后变为: L0→Ln→L1→Ln-1→L2→Ln-2→- 你不能只是单纯的改变节点内部的值,而是需要实际的进行节 ...
- java中Runtime类详细介绍
Runtime类描述了虚拟机一些信息.该类采用了单例设计模式,可以通过静态方法 getRuntime()获取Runtime类实例.下面演示了获取虚拟机的内存信息: package Main; publ ...
- java实现第四届蓝桥杯危险系数
危险系数 抗日战争时期,冀中平原的地道战曾发挥重要作用. 地道的多个站点间有通道连接,形成了庞大的网络.但也有隐患,当敌人发现了某个站点后,其它站点间可能因此会失去联系. 我们来定义一个危险系数DF( ...