并发与高并发(二)-JAVA内存模型
一、java内存模型(JMM)-同步操作与规则
它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。一个线程如何和何时能看到其他线程共享变量的值,以及在必须时如何同步访问共享变量。
JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有些地方称为栈空间),用于存储线程私有的数据,而Java内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问,但线程对变量的操作(读取赋值等)必须在工作内存中进行,首先要将变量从主内存拷贝的自己的工作内存空间,然后对变量进行操作,操作完成后再将变量写回主内存,不能直接操作主内存中的变量,工作内存中存储着主内存中的变量副本拷贝(私有拷贝)。
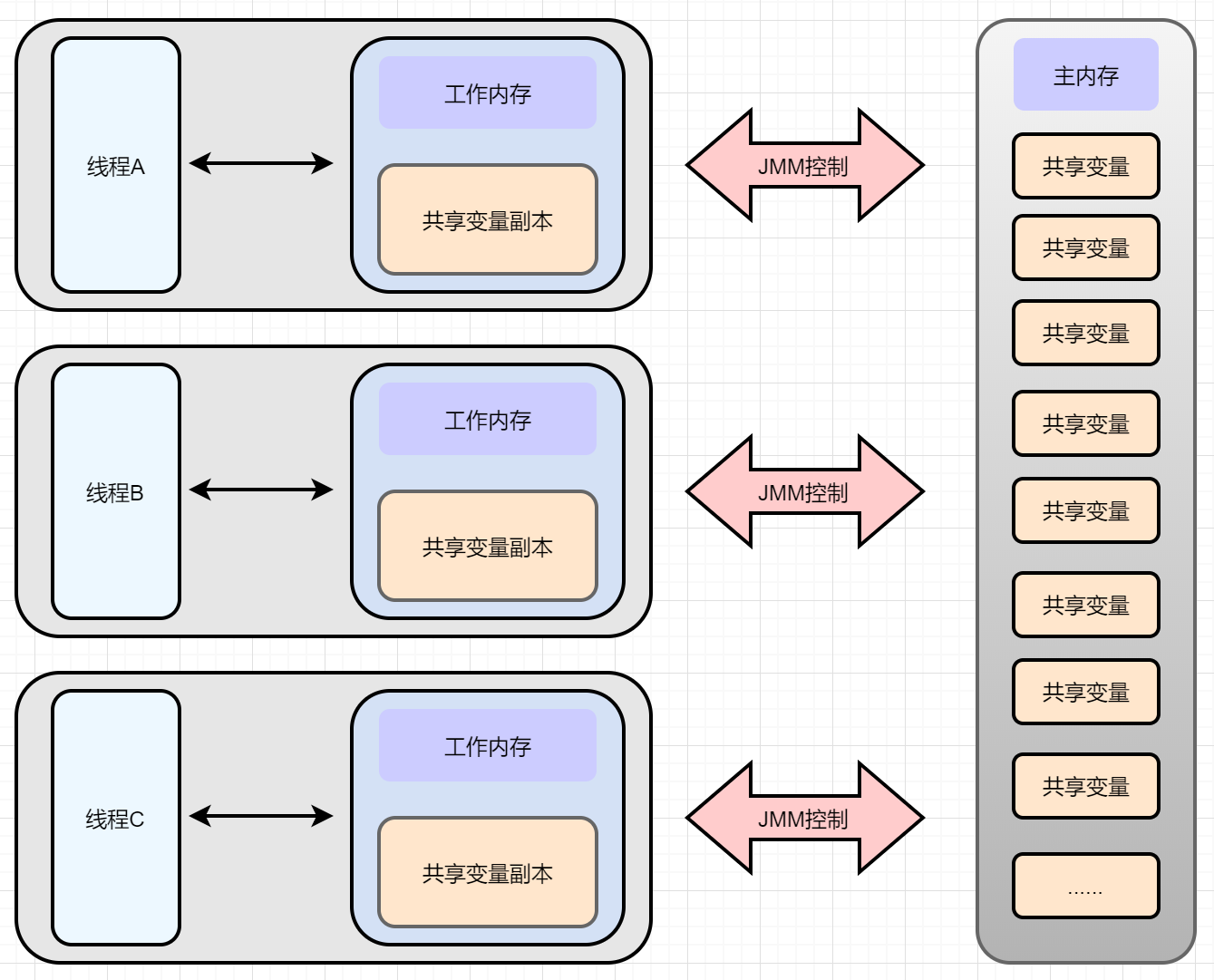
二、Java内存区域
堆:运行时的数据区,由垃圾回收来负责的,优点是 可以动态分配内存大小,(生存区)也不用事先告诉编译器,因为它是在运行时动态分配内存的,垃圾收集器会自动回收不再使用的对象。缺点: 由于是运行时动态分配内存,存取速度相对就比较慢一些。
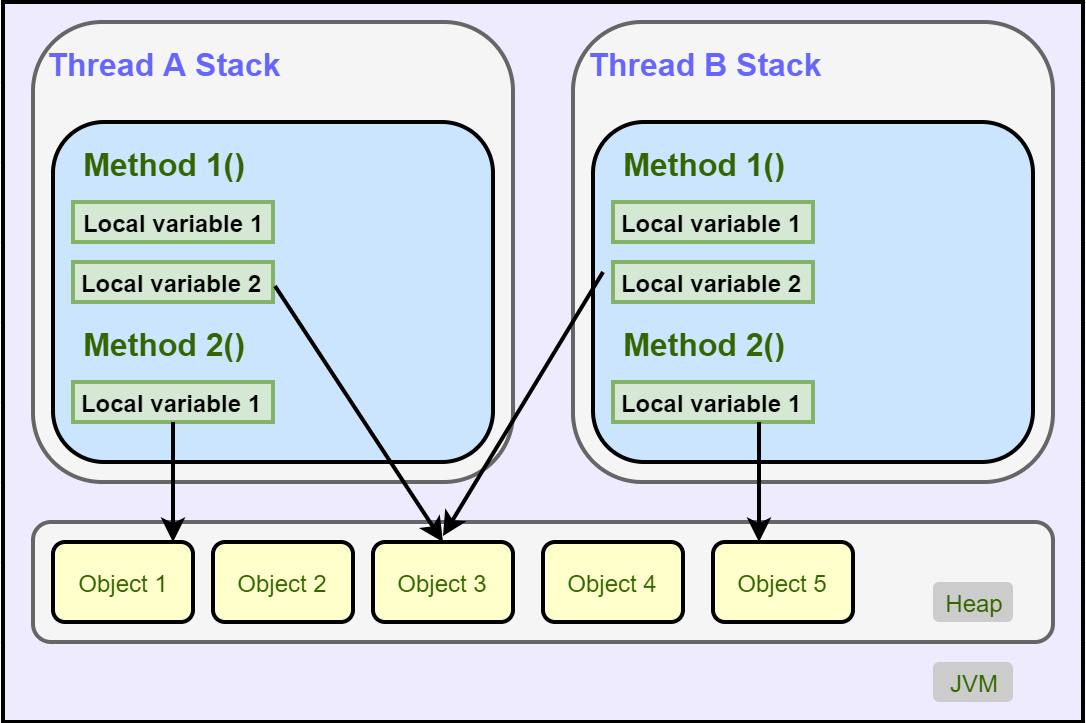
栈:存取速度比堆要快,仅次于计算机里的寄存器,栈里的数据是共享的,但是存在栈中的数据大小与生存区必须是确定的,缺乏一些灵活性。 栈中主要存放一些基本的数据类型变量,比如小写的int,short,long ,byte,调用栈,本地变量存放在栈上,一个本地变量也可以是引用,指向堆中对象。本地变量是存在线程栈上的,尽管这些方法所处的对象处于堆上,一个对象的成员变量可能会随着对象自身存放在堆上,不管这个成员变量是原始类型还是引用类型,本地变量是存在线程栈上的,尽管这些方法所处的对象处于堆上,静态成员变量跟随着类的定义一起存放在堆上,存放在这个堆上的对象可以被所持有对这个对象的引用线程访问,当一个线程能访问这个对象,那么也能访问这个对象的成员变量,如果两个线程同时调用同一个方法的同一个成员变量,但是每一个线程都拥有这个成员变量的私有拷贝。
三、硬件架构

多个CPU,有的CPU还有多核,同时运行多个线程。每个CPU上的线程是可以并行执行的,每个CPU都包含一系列的寄存器,它们是CPu内存的基础。访问速度远大于主存的速度。所以内存和CPU之间有高速缓存,可能还有多级缓存,主存是很大的。
四、JMM与硬件架构的模型
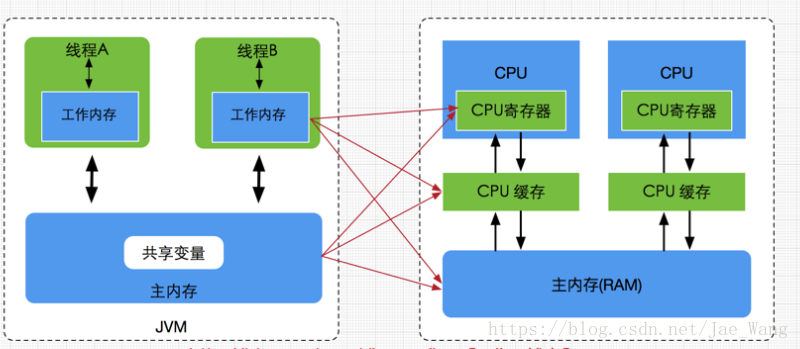
硬件内存架构没有区别线程,栈和堆。对于硬件来说,都分布在主内存里,可能部分堆,栈分布在CPU缓存中或寄存器中
线程间共享变量在主内存里,每个线程都有一个私有的本地内存,他是JAVA内存模型的抽象概念,并不是真实存在的,它涵盖了缓存,缓冲区,以及其他的硬件和编译器的优化,存的是一个副本。
比如线程A从主内存拿到1放到自己的本地内存A,执行+1,再把2写回主内存。两个线程间的不同步性。
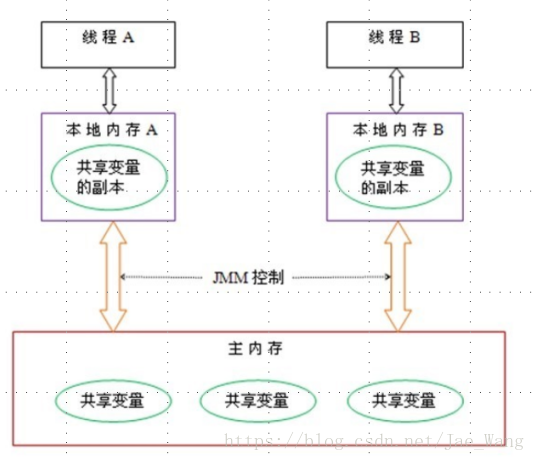
五、Java内存模型的的同步8中操作
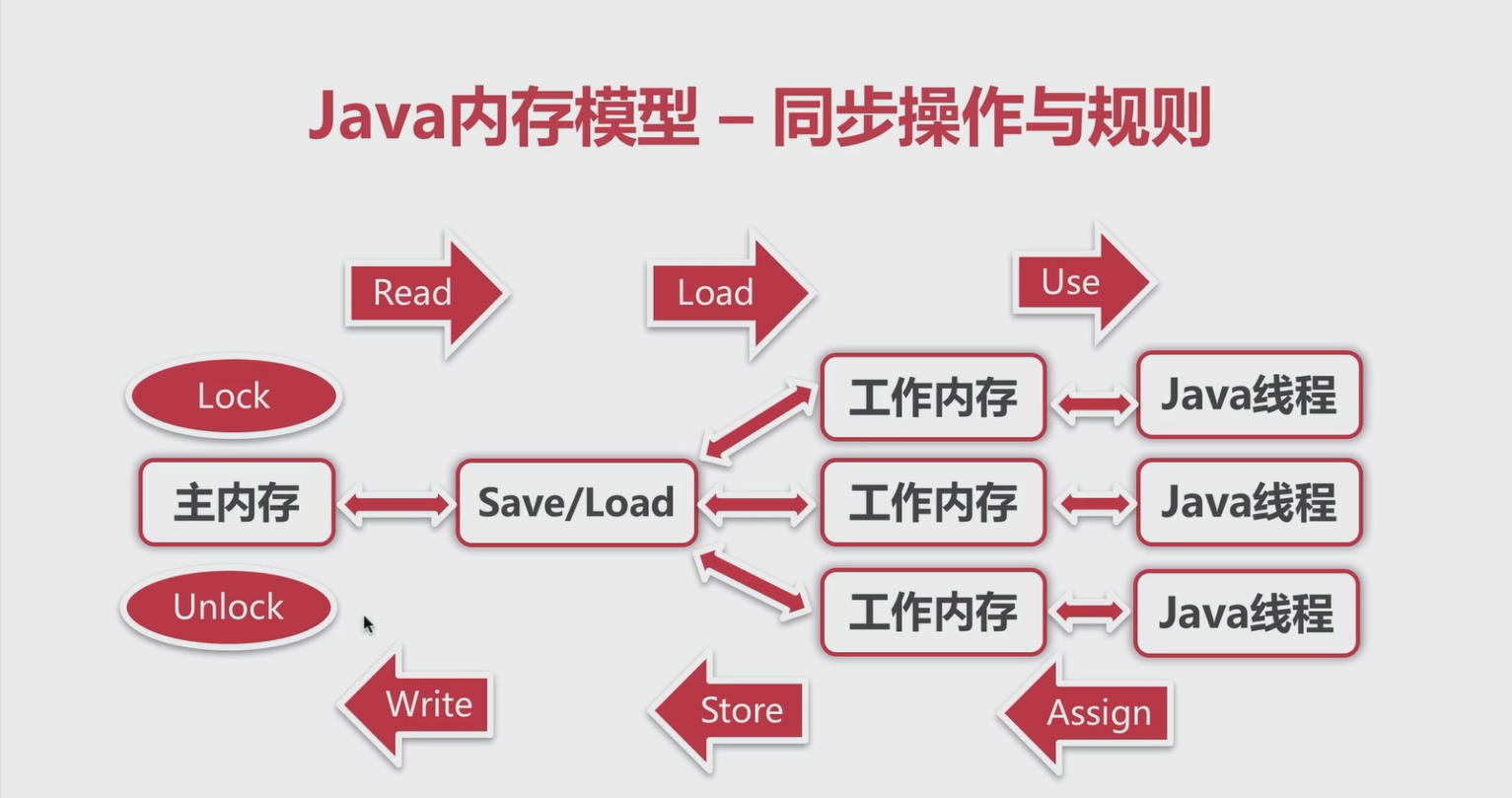
Java虚拟机内存模型中定义了8种关于主内存和工作内存的交互协议操作:
- lock:作用于主内存的变量,把一个变量标识为一条线程独占状态。
- unlock:作用于主内存的变量,把一个处于锁定状态的变量释放出来,释放后的变量可以被其他线程锁定。
- read:作用于主内的变量,把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用。
- load:作用于工作内存的变量,把read读取操作从主内存中得到的变量值放入工作内存的变量拷贝中。
- use:作用于工作内存的变量,把工作内存中一个变量的值传递给java虚拟机执行引擎,每当虚拟机遇到一个需要使用到变量值的字节码指令时将会执行该操作。
- assign:作用于工作内存变量,把一个从执行引擎接收到的变量的值赋值给工作变量,每当虚拟机遇到一个给变量赋值的字节码时将会执行该操作。
- store:作用于工作内存的变量,把工作内存中一个变量的值传送到主内存中,以便随后的write操作使用。
- write:作用于主内存的变量,把store操作从工作内存中得到的变量值放入主内存的变量中。
Java内存模型对上述8种操作有如下的约束:
- 把一个变量从主内存复制到工作内存中必须顺序执行read读入操作和load载入操作。把一个变量从工作内存同步回主内存中必须顺序执行store存储操作和write写入操作。 read和load操作之间、store和write操作之间可以插入其他指令,但是read和load操作、store和write操作必须要按顺序执行,即不允许read和load、store和write操作之一单独出现。
- 不允许一个线程丢弃它的最近的assign赋值操作,即工作内存变量值改变之后必须同步回主内存。只有发生过assign赋值操作的变量才需要从工作内存同步回主内存。
- 一个新变量只能在主内存中产生,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量,即一个变量在进行use和store操作之前,必须先执行过assgin和load操作。
- 一个变量在同一时刻只允许一条线程对其进行lock锁定操作,但是lock锁定可以被一条线程重复执行多次,多次执行lock之后,只有执行相同次数的unlock操作变量才会被解锁。
- 如果对一个变量执行lock锁定操作,将会清空工作内存中该变量的值,在执行引擎使用这个变量前,需要重新执行load或assign操作初始化变量的值。
- 如果一个变量事先没有被lock锁定,则不允许对这个变量进行unlock解锁操作,也不允许对一个被别的线程锁定的变量进行unlock解锁。
- 一个变量进行unlock解锁操作之前,必须先把此变量同步回主内存中(执行store和write操作)。
当一个变量被声明为volatile之后,JMM对其做了特殊规则:
- volatile变量的操作必须严格按load->use顺序,前一个动作是load时才能执行use动作,后一个动作是use时才能执行load动作,即每次在工作内存中使用变量前必须先从主内存中刷新最新的值,以保证能看到其他线程对变量的最新修改。
- volatile变量的操作必须严格按assign->store顺序,前一个动作是assign时才能执行store动作,后一个动作是store时才能执行assign动作,即每次在工作内存为变量赋值之后必须将变量的值同步回主内存,以保证让其他线程能看到变量的最新修改。
- 若线程对volatile变量V的assign或者use操作先于对volatile变量W的assign或者use操作,则线程对volatile变量A的read/load或者store/write操作也必定先于对volatile变量B的read/load或者store/write操作。
关于详细的java内存模型介绍,可参考以下博客链接:
https://blog.csdn.net/qq_34964197/article/details/80937147
并发与高并发(二)-JAVA内存模型的更多相关文章
- Java高并发--CPU多级缓存与Java内存模型
Java高并发--CPU多级缓存与Java内存模型 主要是学习慕课网实战视频<Java并发编程入门与高并发面试>的笔记 CPU多级缓存 为什么需要CPU缓存:CPU的频率太快,以至于主存跟 ...
- 《Java并发编程的艺术》Java内存模型(三)
Java内存模型 一.Java内存模型的基础 1.并发编程模型的两个关键问题: 两个关键问题,线程之间如何通信和如何同步.两种方式,共享内存和消息传递.Java里线程的通信是通过共享内存,线程的同步是 ...
- Java并发编程(五)-- Java内存模型补充
前面我们已经介绍了:当对象和变量存储到计算机的各个内存区域时,必然会遇到的两个问题及解决方法 共享对象的可见性-- 解决方法:使用java volatile关键字 共享对象的竞争现象 -- 解决方法: ...
- Java并发编程(四)-- Java内存模型
Java内存模型 前面讲到了Java线程之间的通信采用的是共享内存模型,这里提到的共享内存模型指的就是Java内存模型(简称JMM),JMM决定一个线程对共享变量的写入何时对另一个线程可见.从抽象的角 ...
- Java并发(1)- 聊聊Java内存模型
引言 在计算机系统的发展过程中,由于CPU的运算速度和计算机存储速度之间巨大的差距.为了解决CPU的运算速度和计算机存储速度之间巨大的差距,设计人员在CPU和计算机存储之间加入了高速缓存来做为他们之间 ...
- Java并发程序设计(三) Java内存模型和线程安全
Java内存模型和线程安全 一 .原子性 原子性是指一个操作是不可中断的.即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其它线程干扰. 思考:i++是原子操作吗? 二.有序性 Java代 ...
- 【Java并发编程】:深入Java内存模型—内存操作规则总结
主内存与工作内存 java内存模型的主要目标是定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样的底层细节.此处的变量主要是指共享变量,存在竞争问题的变量.Java内存模 ...
- 【Java并发编程】:深入Java内存模型——happen-before规则及其对DCL的分析
happen—before规则介绍 Java语言中有一个“先行发生”(happen—before)的规则,它是Java内存模型中定义的两项操作之间的偏序关系,如果操作A先行发生于操作B,其意思就是说, ...
- java高并发实战(三)——Java内存模型和线程安全
转自:https://blog.csdn.net/gududedabai/article/details/80816488
- 并发系列(二)----Java内存模型
一 简介 在并发编程中,两个线程(A.B)同时操作一个普通变量的时候会出现线程A在操作变量时线程B也将变量操作了,此时线程A是无法感知变量发生变化的,造成变量改变错误.更据以上例子我们需要解决的问题就 ...
随机推荐
- spring boot集成mybatis(1)
Spring Boot 集成教程 Spring Boot 介绍 Spring Boot 开发环境搭建(Eclipse) Spring Boot Hello World (restful接口)例子 sp ...
- .NET via C#笔记17——委托
一.委托的内部实现 C#中的委托是一种类型安全的回调函数,假设有这样一个委托: internal delegate void Feedback(int value); 编译器会生成一个类: inter ...
- Java Web学生信息保存
Course.javapackage entity; public class Course { private int id; private String num; private String ...
- Kubernetes-基于helm安装部署高可用的Redis及其形态探索(二)
上一章,我们通过实践和其他文章的帮助,在k8s的环境安装了redis-ha,并且对其进行了一些实验来验证他的主从切换是否有效.本篇中将会分析,究竟是如何实现了redis-ha的主从切换,以及其与K8S ...
- SQL的查询结果复制到Excel 带标题Head 有换行符导致换行错乱 的解决方案
将SQL查询到的结果保存为excel有很多方法,其中最简单的就是直接复制粘贴了 1.带Head的复制粘贴 1)先左击红色区域实现选择所有数据 2)随后右击选择Copy with Headers 再粘 ...
- bugku-Web-多次(异或注入,判断被过滤的关键字)
进去看到url感觉是sql注入, 加上',报错但是%23不报错,加上'--+,也不报错,说明可以用--+注释 加上' or 1=1--+,报错 尝试' oorr 1=1--+,正常 说明or被过滤了. ...
- UML-设计模式-对一组相关的对象使用抽象工厂模式
1.场景 问题: javapos驱动,有2套,一套是IBM的,另一套是NCR的.如: 使用IBM硬件时要用IBM的驱动,使用NCR的硬件时要用NCR的驱动.那该如何设计呢? 注意,此处需要创建一组类( ...
- 在设备上启用 adb 调试,有一个小秘密
要在通过 USB 连接的设备上使用 adb,您必须在设备的系统设置中启用 USB 调试(位于开发者选项下). 在搭载 Android 4.2 及更高版本的设备上,“开发者选项”屏幕默认情况下处于隐藏状 ...
- SeetaFaceQt:Qt多线程
为什么要做多线程,说个最简单的道理就是我们不希望在软件处理数据的时候界面处于无法响应的假死状态.有些处理是灰常花时间的,如果把这样的处理放到主线程中执行,就会导致软件一条路走到底,要等到处理完才能接收 ...
- Codeforces Round #599 (Div. 2) Tile Painting
题意:就是给你一个n,然后如果 n mod | i - j | == 0 并且 | i - j |>1 的话,那么i 和 j 就是同一种颜色,问你最大有多少种颜色? 思路: 比赛的时候,看到 ...