Hadoop Compression
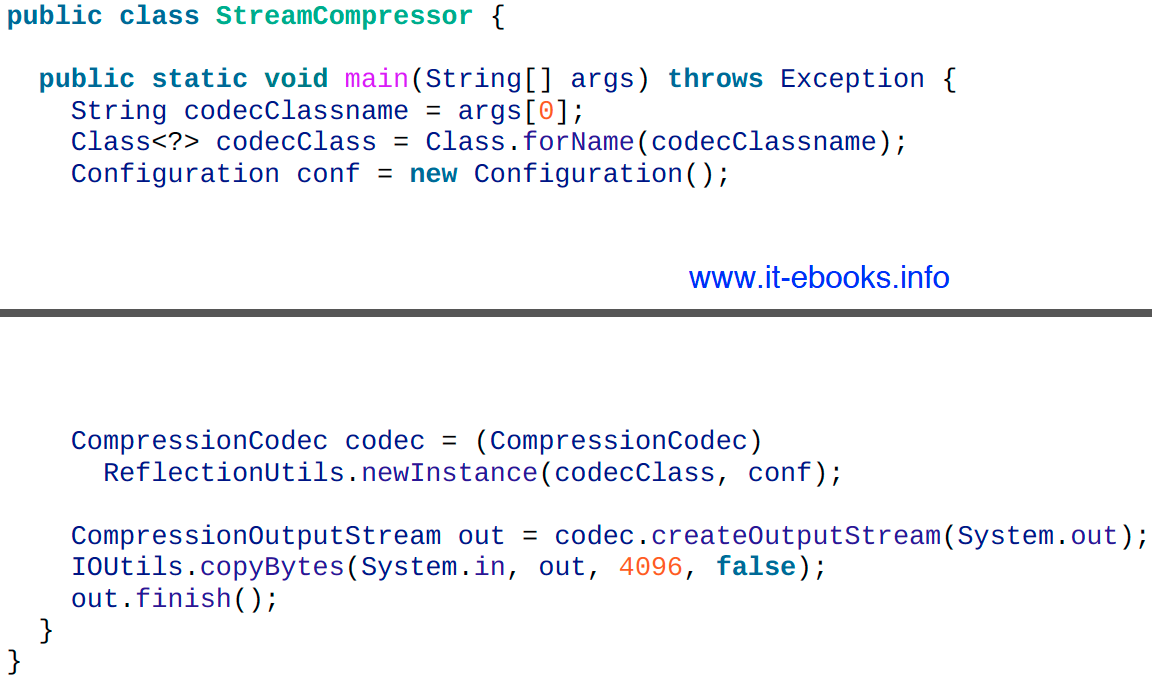
public interface CompressionCodec {
CompressionOutputStream createOutputStream(OutputStream out) throws IOException;
CompressionOutputStream createOutputStream(OutputStream out, Compressor compressor) throws IOException;
Class<? extends Compressor> getCompressorType();
Compressor createCompressor();
CompressionInputStream createInputStream(InputStream in) throws IOException;
CompressionInputStream createInputStream(InputStream in, Decompressor decompressor) throws IOException;
Class<? extends Decompressor> getDecompressorType();
Decompressor createDecompressor();
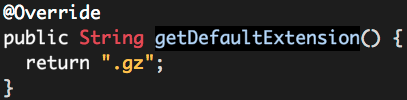
String getDefaultExtension();
}




Hadoop Compression的更多相关文章
- Spark on Yarn出现hadoop.compression.lzo.LzoCodec not found问题发现及解决
问题描述: spark.SparkContext: Created broadcast 0 from textFile at WordCount.scala:37 Exception in threa ...
- [Compression] Hadoop 压缩
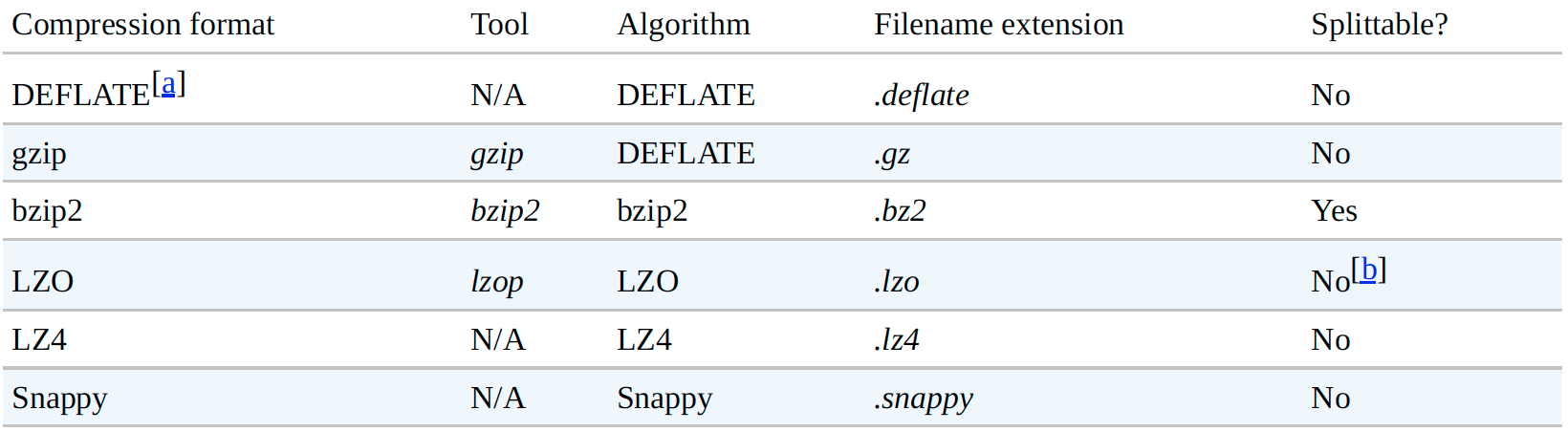
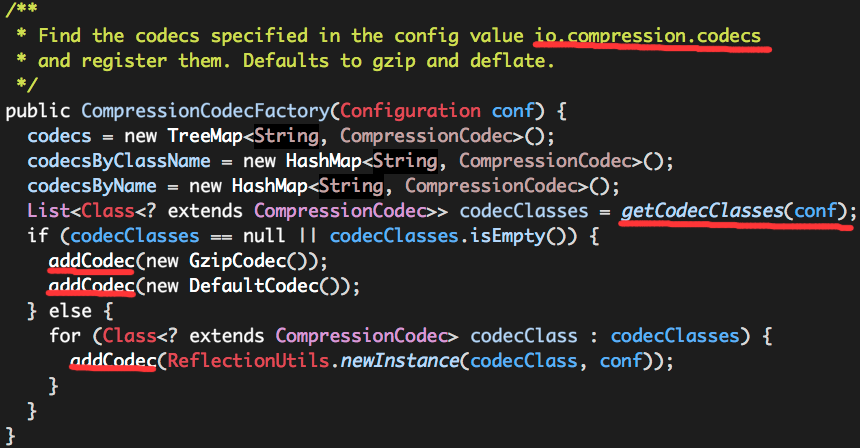
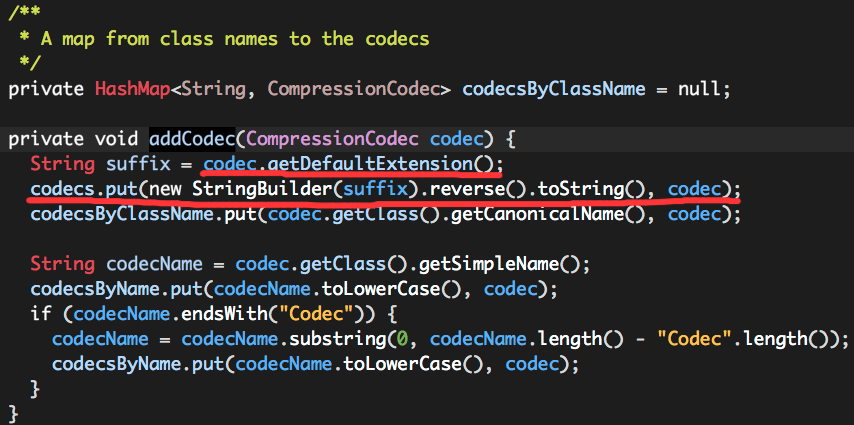
0. 说明 Hadoop 压缩介绍 && 压缩格式总结 && 压缩编解码器测试 1. 介绍 [文件压缩的好处] 文件压缩的好处如下: 减少存储文件所需要的磁盘空间 加速 ...
- hadoop安装遇到的各种异常及解决办法
hadoop安装遇到的各种异常及解决办法 异常一: 2014-03-13 11:10:23,665 INFO org.apache.hadoop.ipc.Client: Retrying connec ...
- Hadoop安装lzo实验
参考http://blog.csdn.net/lalaguozhe/article/details/10912527 环境:hadoop2.3cdh5.0.2 hive 1.2.1 目标:安装lzo ...
- hadoop core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text ...
- Hadoop配置文件
部分内容参考:http://www.linuxqq.net/archives/964.html http://slaytanic.blog.51cto.com/2057708/1100974/ ht ...
- Hadoop使用lzo压缩格式
在hadoop中搭建lzo环境: wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.06.tar.gz export CFLAGS ...
- 使用yum安装CDH Hadoop集群
使用yum安装CDH Hadoop集群 2013.04.06 Update: 2014.07.21 添加 lzo 的安装 2014.05.20 修改cdh4为cdh5进行安装. 2014.10.22 ...
- [大牛翻译系列]Hadoop(20)附录A.10 压缩格式LZOP编译安装配置
附录A.10 LZOP LZOP是一种压缩解码器,在MapReduce中可以支持可分块的压缩.第5章中有一节介绍了如何应用LZOP.在这一节中,将介绍如何编译LZOP,在集群做相应配置. A.10.1 ...
随机推荐
- dubbo(soa分布式)与cobar(mysql分布式)
http://www.jianshu.com/p/0dde591f21d0 (Dubbo编译不是个顺利的事) Cobar是提供关系型数据库(MySQL)分布式服务的中间件,它可以让传统的数据库得到良好 ...
- 4道过滤菜鸟的iOS面试题
网上已经有很多针对各种知识点的面试题,面试时有些人未必真正理解也能通过背题看上去很懂.我自己总结了4道面试题,好快速的判断这个人是否是一个合格的工程师,欢迎大家点评. 1.struct和class的区 ...
- yii redirect
redirect 这个方法是在 CController 里定义的 先来看下官方介绍 redirect() 方法 public void redirect(mixed $url, boolean $te ...
- Dedecms调用文章发布时间的方法
在织梦系统中,有时候需要调用文章发布的时间,格式不同,代码不同.现总结织梦系统dedecms调用文章发布时间的几种方法. 11-20 样式 ([field:pubdate function='st ...
- android开发中的5种存储数据方式
数据存储在开发中是使用最频繁的,根据不同的情况选择不同的存储数据方式对于提高开发效率很有帮助.下面笔者在主要介绍Android平台中实现数据存储的5种方式. 1.使用SharedPreferences ...
- 在Global.asax文件里实现通用防SQL注入漏洞程序(适应于post/get请求)
可使用Global.asax中的Application_BeginRequest(object sender, EventArgs e)事件来实现表单或者URL提交数据的获取,获取后传给SQLInje ...
- LINQ to SQL 基础
取得数据库Gateway 要操作数据库,我们首先要获得一个DataContext对象,这个对象相当于一个数据 库的Gateway,所有的操作都是通过它进行的.这个对象的名字是“Linq to SQL ...
- unexpected nil window in _UIApplicationHandleEventFromQueueEvent...
unexpected nil window in _UIApplicationHandleEventFromQueueEvent, _windowServerHitTestWindow: <UI ...
- cas sso单点登录系列6_cas单点登录防止登出退出后刷新后退ticket失效报500错
转(http://blog.csdn.net/ae6623/article/details/9494601) 问题: 我登录了client2,又登录了client3,现在我把client2退出了,在c ...
- hdu1301 Jungle Roads (Prim)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1301 依旧Prim............不多说了 #include<iostream> ...