Solr4.8.0源码分析(14)之SolrCloud索引深入(1)
Solr4.8.0源码分析(14) 之 SolrCloud索引深入(1)
上一章节《Solr In Action 笔记(4) 之 SolrCloud分布式索引基础》简要学习了SolrCloud的索引过程,本节开始将通过阅读源码来深入学习下SolrCloud的索引过程。
1. SolrCloud的索引过程流程图
这里借用下《solrCloud Update Request Handling 更新索引流程》流程图:
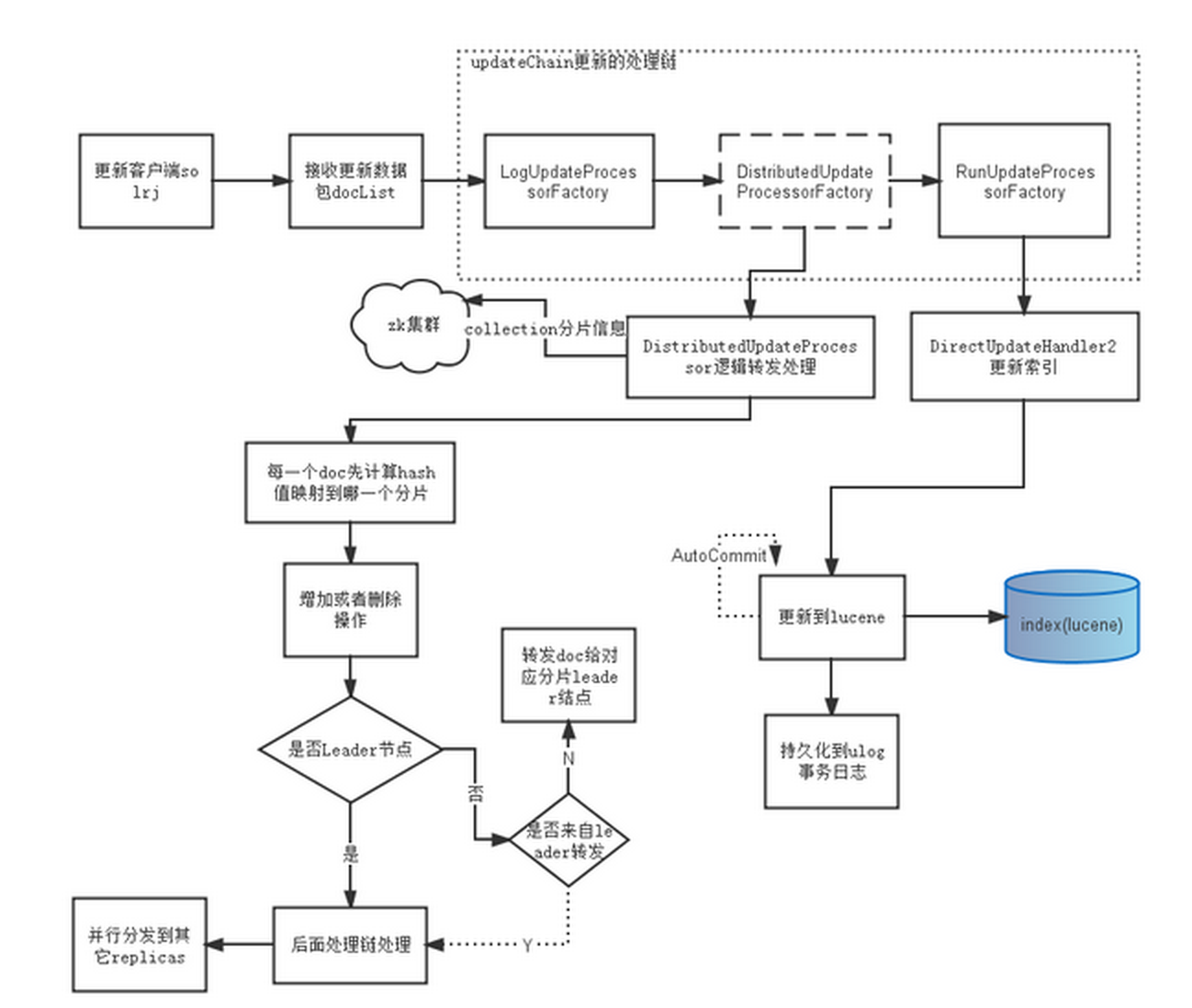
由上图可以看出,SolrCloud的索引过程主要通过一个索引链过程来实现的,那么本节主要讲述下索引链以及DistributedUpdateProcessor这个过程。
2. SolrCloud update索引链
- SolrCloud的Update索引链的类是UpdateRequestProcessorChain,这个类在Solr初始化的时候就会进行定义。
- SolrCloud的Update索引链的组成可以通过solrconfig.xml进行自定义,比较灵活,例如:
<updateRequestProcessorChain name="key" default="true">
<processor class="package.Class1" />
<processor class="package.Class2" >
<str name="someInitParam1">value</str>
<int name="someInitParam2">42</int>
</processor>
<processor class="solr.LogUpdateProcessorFactory" >
<int name="maxNumToLog">100</int>
</processor>
<processor class="solr.RunUpdateProcessorFactory" />
</updateRequestProcessorChain>
- 如果未自定义UpdateRequestProcessorChain,那么Solr就默认以下三个过程组成索引链,依次如下:
LogUpdateProcessorFactory, 它对应的处理过程为LogUpdateProcessor , 主要负责日志的记录;
DistributedUpdateProcessorFactory, 它对应的处理过程为DistributedUpdateProcessor ,主要负责对version的处理以及request的分发;
RunUpdateProcessorFactory, 它对应的处理过程为DirectUpdateHandler2 ,主要负责将记录add进本shard的lucene中;
- 如果最后一个索引链包含了RunUpdateProcessorFactory,但是没有包含DistributedUpdateProcessorFactory,那么Solr会在索引链init的时候自动在RunUpdateProcessorFactory前面加入DistributedUpdateProcessorFactory;
- 每一次update操作,都会重新创建一个索引链,即createProcessor,然后依次进行下去;
- update操作包含add,delete,commit,所以上述UpdateProcessor都会分别包含processAdd,processDelete,processCommit,依次可以细分成add 索引链,delete索引链,commit索引链。
明白了以上几点,那么开始学习索引链的源码
- 首先来查看索引链的init代码,UpdateRequestProcessorChain.init()在初始化SolrCore的时候就调用了
public void init(PluginInfo info) {
final String infomsg = "updateRequestProcessorChain \"" +
(null != info.name ? info.name : "") + "\"" +
(info.isDefault() ? " (default)" : "");
log.info("creating " + infomsg);
// wrap in an ArrayList so we know we know we can do fast index lookups
// and that add(int,Object) is supported
//从solrcore获取索引链的成员,存放成列表形式。索引链在Solrconfig.xml中是以插件的形式加入的
List<UpdateRequestProcessorFactory> list = new ArrayList
(solrCore.initPlugins(info.getChildren("processor"),UpdateRequestProcessorFactory.class,null));
if(list.isEmpty()){
throw new SolrException(SolrException.ErrorCode.SERVER_ERROR,
infomsg + " require at least one processor");
}
int numDistrib = 0;
int runIndex = -1;
// hi->lo incase multiple run instances, add before first one
// (no idea why someone might use multiple run instances, but just in case)
//从后往前遍历索引链列表,寻找DistributingUpdateProcessorFactory和RunUpdateProcessorFactory
for (int i = list.size()-1; 0 <= i; i--) {
UpdateRequestProcessorFactory factory = list.get(i);
if (factory instanceof DistributingUpdateProcessorFactory) {
numDistrib++; //DistributingUpdateProcessorFactory的个数不能超过1
}
if (factory instanceof RunUpdateProcessorFactory) {
runIndex = i; //RunUpdateProcessorFactory的编号
}
}
if (1 < numDistrib) {
throw new SolrException(SolrException.ErrorCode.SERVER_ERROR,
infomsg + " may not contain more then one " +
"instance of DistributingUpdateProcessorFactory");
}
//如果存在RunUpdateProcessorFactory且没有DistributingUpdateProcessorFactory,
//那么会在RunUpdateProcessorFactory之前加入DistributingUpdateProcessorFactory
if (0 <= runIndex && 0 == numDistrib) {
// by default, add distrib processor immediately before run
DistributedUpdateProcessorFactory distrib
= new DistributedUpdateProcessorFactory();
distrib.init(new NamedList());
list.add(runIndex, distrib);
log.info("inserting DistributedUpdateProcessorFactory into " + infomsg);
}
chain = list.toArray(new UpdateRequestProcessorFactory[list.size()]);
}
- 每当有update请求时候就会触发索引链的创建,UpdateRequestProcessorChain.createProcessor。
public UpdateRequestProcessor createProcessor(SolrQueryRequest req,
SolrQueryResponse rsp)
{
UpdateRequestProcessor processor = null;
UpdateRequestProcessor last = null;
//获取distribPhase 是否需要跳过DistributingUpdateProcessorFactory前面那一过程(即LogUpdateProcessor),该参数不是由客户端生成
final String distribPhase = req.getParams().get(DistributingUpdateProcessorFactory.DISTRIB_UPDATE_PARAM);
final boolean skipToDistrib = distribPhase != null;
boolean afterDistrib = true; // we iterate backwards, so true to start
//从后往前组件索引链即
//LogUpdateProcessor.next = DistributedUpdateProcessor
//DistributedUpdateProcessor.next = DirectUpdateHandler2
//DirectUpdateHandler2.next = null
for (int i = chain.length-1; i>=0; i--) {
UpdateRequestProcessorFactory factory = chain[i]; if (skipToDistrib) {
if (afterDistrib) {
// 跳过DistributingUpdateProcessorFactory前面的索引链过程
if (factory instanceof DistributingUpdateProcessorFactory) {
afterDistrib = false;
}
} else if (!(factory instanceof UpdateRequestProcessorFactory.RunAlways)) {
// skip anything that doesn't have the marker interface
continue;
}
}
//创建UpdateRequestProcessorFactory对应的UpdateProcessor,并进行连接
processor = factory.getInstance(req, rsp, last);
last = processor == null ? last : processor;
} return last;
}
- 在UpdateRequestProcessorChain.createProcessor会调用UpdateRequestProcessorFactory的getInstance创建对应的updateProcessor,
LogUpdateProcessor
public UpdateRequestProcessor getInstance(SolrQueryRequest req, SolrQueryResponse rsp, UpdateRequestProcessor next) {
return LogUpdateProcessor.log.isInfoEnabled() ? new LogUpdateProcessor(req, rsp, this, next) : null;
}
- DistributedUpdateProcessor
public DistributedUpdateProcessor getInstance(SolrQueryRequest req,
SolrQueryResponse rsp, UpdateRequestProcessor next) { return new DistributedUpdateProcessor(req, rsp, next);
}
RunUpdateProcessorFactory
public UpdateRequestProcessor getInstance(SolrQueryRequest req, SolrQueryResponse rsp, UpdateRequestProcessor next)
{
return new RunUpdateProcessor(req, next);
}
总结:本节主要学习了SolrCloud分布式索引的整体流程,以及SolrCloud建索引时候索引链的情况,下一节将详细介绍索引链的具体过程。
Solr4.8.0源码分析(14)之SolrCloud索引深入(1)的更多相关文章
- Solr4.8.0源码分析(15) 之 SolrCloud索引深入(2)
Solr4.8.0源码分析(15) 之 SolrCloud索引深入(2) 上一节主要介绍了SolrCloud分布式索引的整体流程图以及索引链的实现,那么本节开始将分别介绍三个索引过程即LogUpdat ...
- Solr4.8.0源码分析(17)之SolrCloud索引深入(4)
Solr4.8.0源码分析(17)之SolrCloud索引深入(4) 前面几节以add为例已经介绍了solrcloud索引链建索引的三步过程,delete以及deletebyquery跟add过程大同 ...
- Solr4.8.0源码分析(16)之SolrCloud索引深入(3)
Solr4.8.0源码分析(16)之SolrCloud索引深入(3) 前面两节学习了SolrCloud索引过程以及索引链的前两步,LogUpdateProcessorFactory和Distribut ...
- Solr4.8.0源码分析(22)之SolrCloud的Recovery策略(三)
Solr4.8.0源码分析(22)之SolrCloud的Recovery策略(三) 本文是SolrCloud的Recovery策略系列的第三篇文章,前面两篇主要介绍了Recovery的总体流程,以及P ...
- Solr4.8.0源码分析(20)之SolrCloud的Recovery策略(一)
Solr4.8.0源码分析(20)之SolrCloud的Recovery策略(一) 题记: 我们在使用SolrCloud中会经常发现会有备份的shard出现状态Recoverying,这就表明Solr ...
- Solr4.8.0源码分析(24)之SolrCloud的Recovery策略(五)
Solr4.8.0源码分析(24)之SolrCloud的Recovery策略(五) 题记:关于SolrCloud的Recovery策略已经写了四篇了,这篇应该是系统介绍Recovery策略的最后一篇了 ...
- Solr4.8.0源码分析(25)之SolrCloud的Split流程
Solr4.8.0源码分析(25)之SolrCloud的Split流程(一) 题记:昨天有位网友问我SolrCloud的split的机制是如何的,这个还真不知道,所以今天抽空去看了Split的原理,大 ...
- Solr4.8.0源码分析(23)之SolrCloud的Recovery策略(四)
Solr4.8.0源码分析(23)之SolrCloud的Recovery策略(四) 题记:本来计划的SolrCloud的Recovery策略的文章是3篇的,但是没想到Recovery的内容蛮多的,前面 ...
- Solr4.8.0源码分析(21)之SolrCloud的Recovery策略(二)
Solr4.8.0源码分析(21)之SolrCloud的Recovery策略(二) 题记: 前文<Solr4.8.0源码分析(20)之SolrCloud的Recovery策略(一)>中提 ...
随机推荐
- 什么是method swizzling
其实跟字面的意思很相近.方法的调和.可以去修改oc中两个方法的调用. 这张图看起来会比较形象 20130718230430859.png 就是把两个实现调换具体的做法,首先,用Categroy建立自己 ...
- javaweb开发过程中的地址写法
凡是要表示web资源的地址,比如浏览器地址栏中,都是 /凡是要表示硬盘地址, 都是 \ public class ServletDemo1 extends HttpServlet { //实际开发过 ...
- 高性能Java Web 页面静态化技术(原创)
package com.yancms.util; import java.io.*; import org.apache.commons.httpclient.*; import org.apache ...
- NGUI对象跟随鼠标拖拽移动
public Camera WNGUICamera; Vector3 _WoldPosition;//指针的初始位置 // Vector3 _WoldAng; Vector3 WscreenSpace ...
- android——wifi系统架构
1. 系统架构 Android WiFi系统引入了wpa_supplicant,它的整个WiFi系统以wpa_supplicant为核心来定义上层用户接口和下层驱动接口.整个WiFi系统架构如下图所示 ...
- Understanding Extension Class Loading--官方
http://docs.spring.io/spring-amqp/docs/1.3.6.RELEASE/reference/html/sample-apps.html#d4e1285 http:// ...
- [转] java中的匿名内部类总结
匿名内部类也就是没有名字的内部类 正因为没有名字,所以匿名内部类只能使用一次,它通常用来简化代码编写 但使用匿名内部类还有个前提条件:必须继承一个父类或实现一个接口 实例1:不使用匿名内部类来实现抽象 ...
- C++笔试题库-------Coding整理
1. 反转字符串 char* strrev1(const char* str) { int len = strlen(str); ]; char *p = temp + len; *p = '\0'; ...
- Could not fetch https://api.github.com/repos/RobinHerbots/jquery
使用 composer 安装YII2时, 如题所示提示, 原因是由于yii安装中, 需要有一些相关的认证[或许说是composer的认证], 如有如下提示 Could not fetch https: ...
- android EditText设置光标、边框和图标
控制边框形状,先在drawable中建一个xml文件:shape.xml <?xml version="1.0" encoding="utf-8"?> ...