UFLDL教程(五)之self-taught learning
这里所谓的自学习,其实就是利用稀疏自编码器对无标签样本学习其特征
该自学习程序包括两部分:
- 稀疏自编码器学习图像特征(实现自学习)---用到无标签的样本集
- softmax回归对样本分类---用到有标签的训练样本集
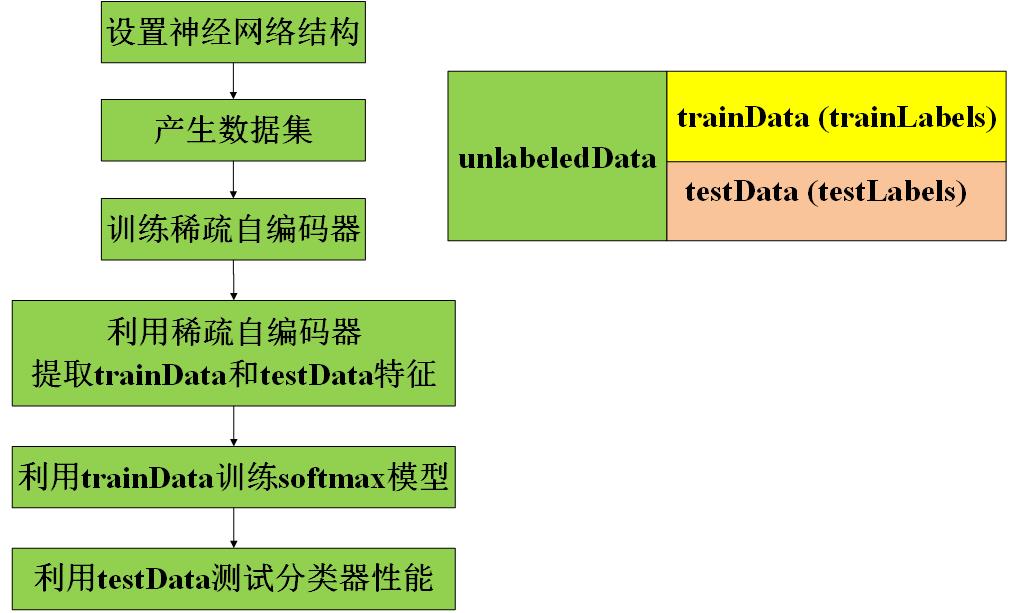
准备工作
下载Yann Lecun的MNIST数据集,本程序用到了如下的两个数据集:

第0步:设置神经网络的结构
该神经网络包括三层:
输入层的神经元个数(数字识别,则设置输入的图像大小)
输出端的神经元个数(也就是类别数)
隐藏层神经元个数
另外一些关于系数编码的参数
sparsityParam、lambda、beta
最大迭代次数:maxIter
% STEP 0: Here we provide the relevant parameters values that will
% allow your sparse autoencoder to get good filters; you do not need to
% change the parameters below.
% 设置神经网络的相关参数
inputSize = 28 * 28; %样本特征维数
numLabels = 5;%样本类别
hiddenSize = 200;%隐藏层神经元个数
sparsityParam = 0.1; % desired average activation of the hidden units.
% (This was denoted by the Greek alphabet rho, which looks like a lower-case "p",
% in the lecture notes).
lambda = 3e-3; % weight decay parameter
beta = 3; % weight of sparsity penalty term
maxIter = 400;%最大迭代步数
第一步:产生无标签样本集和有标签样本集(训练数据集和测试数据集)
(1)导入数据集mnistData和mnistLabels
mnistData是一个矩阵,每一列为一个输入样本(也就是一个输入的数字图像所有像素点按列排布)
mnistLabels是一个向量,它存储的数字表示mnistData中每一列样本的类别
(2)将输入的样本集mnistData进行分组
① 首先,将mnistData分为两组:一组为有标签的数据集(数字0-4的样本),另一组为无标签的数据集(数字5-9的样本)
(这两组的指标集分别为labeledSet和unlabeledSet)
② 然后,再将有标签的数据集平均分为两组,一组作为训练集、一组作为测试集;
(这两组的指标集分别为trainSet和testSet)
这里的指标,指在mnistData中的列序号
③ 分别得到上述三组指标集得到相应的数据集,并得到有标签数据集的标签
unlabeledData:无标签数据集,每一列为一个样本
trainData:有标签训练集,每一列为一个样本,相应的标签存放在trainLabels中
testData:有标签测试集,每一列为一个样本,相应的标签存放在testLabels中
%% ======================================================================
% STEP 1: Load data from the MNIST database
% This loads our training and test data from the MNIST database files.
% We have sorted the data for you in this so that you will not have to
% change it. % Load MNIST database files
addpath MNIST\ %MNIST数据集及其相关操作函数均在此文件夹中
mnistData = loadMNISTImages('mnist/train-images-idx3-ubyte');
mnistLabels = loadMNISTLabels('mnist/train-labels-idx1-ubyte'); % 无标签样本集和有标签样本集的指标集(将整个数据集分为无标签样本集和有标签样本集)
unlabeledSet = find(mnistLabels >= 5);% 无标号数据集的指标(数字5-9的样本)
labeledSet = find(mnistLabels >= 0 & mnistLabels <= 4);% 有标签数据集的指标(数字0-4的样本) % 无标记样本集的数据
unlabeledData = mnistData(:, unlabeledSet); % 训练数据集和测试数据集的指标集(有标签数据集再分为两部分:训练数据集和测试数据集)
numTrain = round(numel(labeledSet)/2);%训练样本个数
trainSet = labeledSet(1:numTrain);%训练样本集
testSet = labeledSet(numTrain+1:end);%测试样本集 % 训练数据集的数据和标签
trainData = mnistData(:, trainSet);
trainLabels = mnistLabels(trainSet)' + 1; % Shift Labels to the Range 1-5 % 测试数据集的数据和标签
testData = mnistData(:, testSet);
testLabels = mnistLabels(testSet)' + 1; % Shift Labels to the Range 1-5 % Output Some Statistics
fprintf('# examples in unlabeled set: %d\n', size(unlabeledData, 2));
fprintf('# examples in supervised training set: %d\n\n', size(trainData, 2));
fprintf('# examples in supervised testing set: %d\n\n', size(testData, 2));
第二步:训练稀疏自编码器
利用无标签数据集unlabeledData训练稀疏自编码器
① 初始化化自编码器的参数theta
② 调用minFunc中的最优化函数,计算得到稀疏自编码器的参数
包括设置minFunc函数的一些参数及对minFunc函数的调用,这里要用到稀疏自编码器的代价函数和梯度计算的函数sparseAutoencoderCost
下图是学习得到的W1的图像

% STEP 2: Train the sparse autoencoder
% This trains the sparse autoencoder on the unlabeled training images. % 初始化化自编码器的参数theta
theta = initializeParameters(hiddenSize, inputSize); % 利用无标签样本集对稀疏自编码器进行学习
%(利用优化函数,这里要用到minFunc文件夹下的优化函数和sparseAutoencoder文件夹下的sparseAutoencoderCost函数)
addpath minFunc/
addpath sparseAutoencoder\
% 优化函数的一些参数设置
options.Method = 'lbfgs'; % Here, we use L-BFGS to optimize our cost
% function. Generally, for minFunc to work, you
% need a function pointer with two outputs: the
% function value and the gradient. In our problem,
% sparseAutoencoderCost.m satisfies this.
options.maxIter = 400; % Maximum number of iterations of L-BFGS to run
options.display = 'on';
% 调用优化函数,得到opttheta,即为稀疏自编码器的所有权值构成的向量
[opttheta, cost] = minFunc( @(p) sparseAutoencoderCost(p, ...
inputSize, hiddenSize, ...
lambda, sparsityParam, ...
beta, unlabeledData), ...
theta, options); % Visualize weights
W1 = reshape(opttheta(1:hiddenSize * inputSize), hiddenSize, inputSize);
display_network(W1');
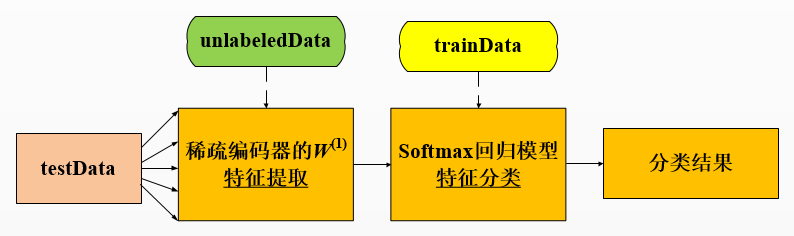
第三步:利用稀疏自编码器对有标签的训练样本集和测试样本集提取特征
在得到稀疏自编码器后,可以利用它从有标签的数据集中提取图像特征,这里需要完成feedForwardAutoencoder.m函数
所谓图像的特征,其实就是指该图像在稀疏自编码器的权值矩阵W1作用下得到的隐藏层的输出
可以得到训练集的特征trainFeatures和测试集的特征testFeatures
它们的每一列分别是由稀疏自编码器提取出的特征
%% STEP 3: Extract Features from the Supervised Dataset
% 利用稀疏自编码器提取训练样本集中所有样本的特征
trainFeatures = feedForwardAutoencoder(opttheta, hiddenSize, inputSize, ...
trainData);
% 利用稀疏自编码器提测试练样本集中所有样本的特征
testFeatures = feedForwardAutoencoder(opttheta, hiddenSize, inputSize, ...
testData);
第四步:利用训练样本集训练softmax回归模型
利用训练集的特征集trainFeatures及其标签集trainLabels,训练softmax回归模型
注:softmaxTrain函数的输入参数(特征维数,标签数,惩罚项权值λ,训练数据集的数据,训练数据集的标签,其他参数)
%% STEP 4: Train the softmax classifier
% Use softmaxTrain.m from the previous exercise to train a multi-class classifier.
% Use lambda = 1e-4 for the weight regularization for softmax
% You need to compute softmaxModel using softmaxTrain on trainFeatures and trainLabels
addpath Softmax\
options.maxIter = 100;
softmaxModel = softmaxTrain(inputSize, numLabels, lambda, ...
trainData, trainLabels, options);
第五步:对测试数据集进行分类
利用得到的softmax回归模型对测试集进行分类
%% STEP 5: Testing
% Compute Predictions on the test set (testFeatures) using softmaxPredict and softmaxModel
[pred] = softmaxPredict(softmaxModel, testData);
% Classification Score
fprintf('Test Accuracy: %f%%\n', 100*mean(pred(:) == testLabels(:)));
下面是函数feedForwardAutoencoder
%% 该函数的作用是:利用稀疏自编码器从数据中提取特征
function [activation] = feedForwardAutoencoder(theta, hiddenSize, visibleSize, data) % theta: trained weights from the autoencoder
% visibleSize: the number of input units (probably 64)
% hiddenSize: the number of hidden units (probably 25)
% data: Our matrix containing the training data as columns. So, data(:,i) is the i-th training example. % We first convert theta to the (W1, W2, b1, b2) matrix/vector format, so that this
% follows the notation convention of the lecture notes. W1 = reshape(theta(1:hiddenSize*visibleSize), hiddenSize, visibleSize);
b1 = theta(2*hiddenSize*visibleSize+1:2*hiddenSize*visibleSize+hiddenSize); %% ---------- YOUR CODE HERE --------------------------------------
% Instructions: Compute the activation of the hidden layer for the Sparse Autoencoder.
activation=sigmoid(W1*data+repmat(b1,1,size(data,2))); %------------------------------------------------------------------- end %-------------------------------------------------------------------
% Here's an implementation of the sigmoid function, which you may find useful
% in your computation of the costs and the gradients. This inputs a (row or
% column) vector (say (z1, z2, z3)) and returns (f(z1), f(z2), f(z3)). function sigm = sigmoid(x)
sigm = 1 ./ (1 + exp(-x));
end
UFLDL教程(五)之self-taught learning的更多相关文章
- Deep Learning 13_深度学习UFLDL教程:Independent Component Analysis_Exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程.Deep learning:三十三(ICA模型).Deep learning:三十九(ICA模型练习) 实验环境:win7, matlab2015b,16G内存,2T机 ...
- Deep Learning 19_深度学习UFLDL教程:Convolutional Neural Network_Exercise(斯坦福大学深度学习教程)
理论知识:Optimization: Stochastic Gradient Descent和Convolutional Neural Network CNN卷积神经网络推导和实现.Deep lear ...
- Deep Learning 7_深度学习UFLDL教程:Self-Taught Learning_Exercise(斯坦福大学深度学习教程)
前言 理论知识:自我学习 练习环境:win7, matlab2015b,16G内存,2T硬盘 练习内容及步骤:Exercise:Self-Taught Learning.具体如下: 一是用29404个 ...
- Deep Learning 4_深度学习UFLDL教程:PCA in 2D_Exercise(斯坦福大学深度学习教程)
前言 本节练习的主要内容:PCA,PCA Whitening以及ZCA Whitening在2D数据上的使用,2D的数据集是45个数据点,每个数据点是2维的.要注意区别比较二维数据与二维图像的不同,特 ...
- Deep Learning 12_深度学习UFLDL教程:Sparse Coding_exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程.Deep learning:二十六(Sparse coding简单理解).Deep learning:二十七(Sparse coding中关于矩阵的范数求导).Deep ...
- Deep Learning 11_深度学习UFLDL教程:数据预处理(斯坦福大学深度学习教程)
理论知识:UFLDL数据预处理和http://www.cnblogs.com/tornadomeet/archive/2013/04/20/3033149.html 数据预处理是深度学习中非常重要的一 ...
- Deep Learning 10_深度学习UFLDL教程:Convolution and Pooling_exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程和http://www.cnblogs.com/tornadomeet/archive/2013/04/09/3009830.html 实验环境:win7, matlab ...
- Deep Learning 9_深度学习UFLDL教程:linear decoder_exercise(斯坦福大学深度学习教程)
前言 实验内容:Exercise:Learning color features with Sparse Autoencoders.即:利用线性解码器,从100000张8*8的RGB图像块中提取颜色特 ...
- Deep Learning 8_深度学习UFLDL教程:Stacked Autocoders and Implement deep networks for digit classification_Exercise(斯坦福大学深度学习教程)
前言 1.理论知识:UFLDL教程.Deep learning:十六(deep networks) 2.实验环境:win7, matlab2015b,16G内存,2T硬盘 3.实验内容:Exercis ...
- Deep Learning 5_深度学习UFLDL教程:PCA and Whitening_Exercise(斯坦福大学深度学习教程)
前言 本文是基于Exercise:PCA and Whitening的练习. 理论知识见:UFLDL教程. 实验内容:从10张512*512自然图像中随机选取10000个12*12的图像块(patch ...
随机推荐
- XML结构文件的读写
附件:http://files.cnblogs.com/xe2011/XML_Writer_And_Read.rar 下面这段代码实现了以下功能 数据保存 textBox1的文本,textBox2的文 ...
- UVA 11551 - Experienced Endeavour(矩阵高速幂)
UVA 11551 - Experienced Endeavour 题目链接 题意:给定一列数,每一个数相应一个变换.变换为原先数列一些位置相加起来的和,问r次变换后的序列是多少 思路:矩阵高速幂,要 ...
- Android M 新的运行时权限开发者需要知道的一切
android M 的名字官方刚发布不久,最终正式版即将来临!android在不断发展,最近的更新 M 非常不同,一些主要的变化例如运行时权限将有颠覆性影响.惊讶的是android社区鲜有谈论这事儿, ...
- .NET 解析HTML代码——NSoup
NSoup是一个开源框架,是JSoup(Java)的.NET移植版本 1.直接用起来 NSoup.Nodes.Document htmlDoc = NSoup.NSoupClient.Parse(HT ...
- ASP.NET中常用重置数据的方法
aspx: <asp:Repeater ID="rptProlist" runat="server" onitemdatabound="rptP ...
- Summary: How to calculate PI? Based on Monte Carlo method
refer to: http://www.stealthcopter.com/blog/2009/09/python-calculating-pi-using-random-numbers/ Duri ...
- 【转】Web前端开发规范文档
规范目的: 使开发流程更加规范化. 通用规范: TAB键用两个空格代替(WINDOWS下TAB键占四个空格,LINUX下TAB键占八个空格). CSS样式属性或者JAVASCRIPT代码后加“;”方便 ...
- GPS定位,经纬度附近地点查询–C#实现方法
目前的工作是需要手机查找附近N米以内的商户,功能如下图 数据库中记录了商家在百度标注的经纬度(如:116.412007, 39.947545), 最初想法 以圆心点为中心点,对半径做循环,半径每增加 ...
- Java获取项目路径
参考博客.自己就不写了.我觉得他写得很详细 http://blog.csdn.net/hpf911/article/details/5852127
- Windows下的进程【一】
什么是进程?进程就是一个正在运行的程序的实例,由两部分组成: 内核对象.操作系统用内核对象对进程进行管理,内核对象是操作系统保存进程统计信息的地方. 地址空间.其中包含所有可执行文件或DLL模块的代码 ...