SQL Server 堆表与栈表的对比(大表)
- 环境准备
使用1个表,生成1000万行来进行性能对比(勉强也算比较大了),对比性能差别。
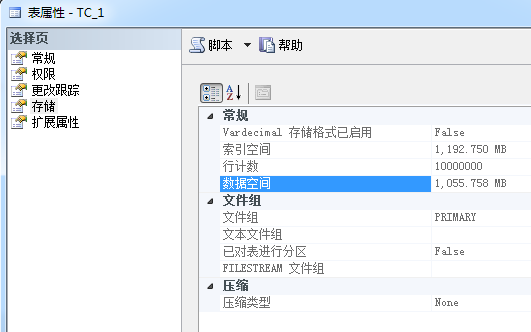
为了简化过程,不提供生成随机数据的过程。该表初始为非聚集索引(堆表),测试过程中会改为聚集索引(栈表)。
CREATE TABLE [dbo].[TC_1](
[sys_guid] [nvarchar](50) NOT NULL, -- 主键,非聚集索引
[valueF] [decimal](18, 2) NOT NULL,
[valueN] [bigint] NOT NULL,
[c] [bigint] IDENTITY(1,1) NOT NULL,
[g] [int] NOT NULL, -- 1-4的随机整数,相当于随机分成4组(接近平均分)
CONSTRAINT [PK_TC_1] PRIMARY KEY NONCLUSTERED
(
[sys_guid] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] GO
-- 先使用非聚集索引,再改为聚集索引进行相同查询
CREATE NONCLUSTERED INDEX [IX_TC_1_c] ON [dbo].[TC_1]
(
[c] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_TC_1_g] ON [dbo].[TC_1]
(
[g] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
SELECT COUNT(*) FROM dbo.TC_1
SELECT TOP 10 * FROM dbo.TC_1
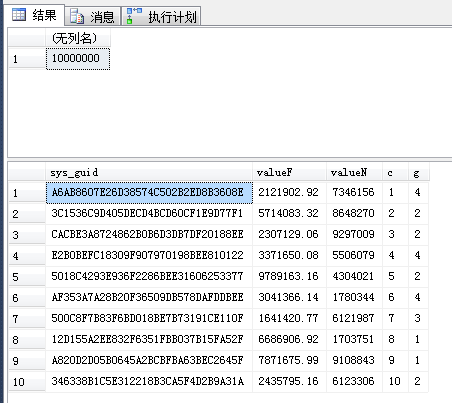
找出一行用于产生seek执行计划(用以下查询任挑一行):
SELECT TOP 10 * FROM dbo.TC_1 ORDER BY NEWID()
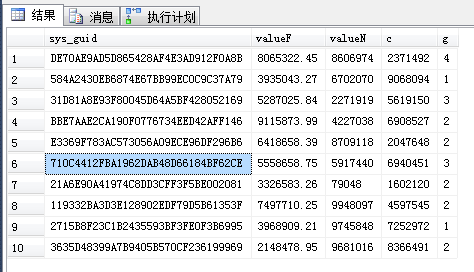
- 语句准备
-- 将c列的索引改为聚集索引的语句(时间会比较久):
DROP INDEX IX_TC_1_c ON dbo.TC_1
GO
CREATE CLUSTERED INDEX IX_TC_1_c ON dbo.TC_1
(
c
) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
-- 清除缓存,每次测试前执行一下
CHECKPOINT
DBCC DROPCLEANBUFFERS
比较以下几种常见的查询形式在堆表和栈表下的表现:
SELECT * FROM dbo.TC_1 WHERE c=6940451 -- 1.一般期望索引seek
SELECT * FROM dbo.TC_1 WHERE sys_guid=N'710C4412FBA1962DAB48D66184BF62CE' -- 2.一般期望索引seek
SELECT COUNT(*) FROM dbo.TC_1 -- 3.一般期望索引scan(基本不可能seek)
SELECT avg(valueF),avg(valueN) FROM dbo.TC_1 WHERE g = 1 GROUP BY g -- 4.一般只能是scan
- 进行测试
打开实际的执行计划和客户端统计信息,开始对比测试
运行以下语句打开时间和IO统计消息:
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
- 如何对比
执行时间与计算机整体状态有关,差别不大时我们不作为可靠结果去对比。由于我们总是清除缓存后再执行查询,因此读取次数是稳定的,这是对比的重点。
逻辑读与物理读,哪个更重要呢?
参考资料1 http://www.cnblogs.com/CareySon/archive/2011/12/23/2299127.html
参考资料2 http://www.canway.net/Original/shujuku/012CE2016.html
其中有一个结论:
关于时间的对比,参考资料 http://www.cnblogs.com/xqhppt/p/4041799.html
其中有一个结论:

- 对比结果
红色√表示对比结果相对更好一点。
普通√表示可以或基本可以满足需求。
SELECT * FROM dbo.TC_1 WHERE c=6940451 -- 1.一般期望索引seek
| 堆表 | 栈表 | |
| 执行计划 | 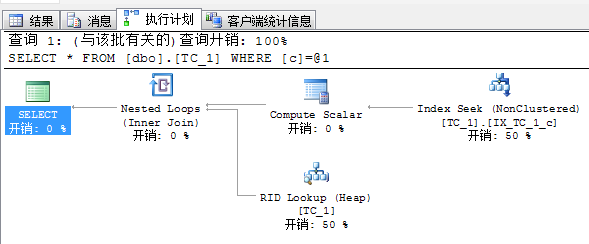 |
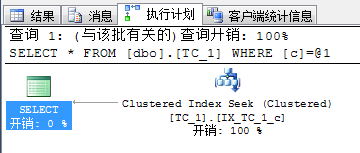 |
| 结果 |  |
 |
| 消息 |
SQL Server 分析和编译时间: SQL Server 执行时间: (1 行受影响) (1 行受影响) SQL Server 执行时间: SQL Server 执行时间: |
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 SQL Server 执行时间: (1 行受影响) (1 行受影响) SQL Server 执行时间: SQL Server 执行时间: |
| 客户端统计信息 | 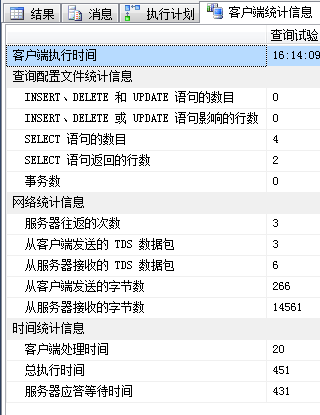 |
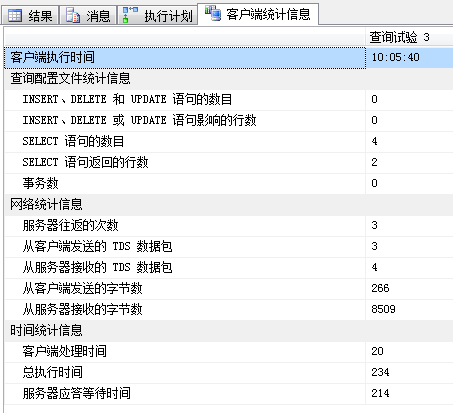 |
| 对比 | √ | √ |
| 栈表具有非常微弱的优势,这类查询一般只会返回很少的行,因此也可以认为差别不大。 | ||
SELECT * FROM dbo.TC_1 WHERE sys_guid=N'710C4412FBA1962DAB48D66184BF62CE' -- 2.一般期望索引seek
| 堆表 | 栈表 | |
| 执行计划 | 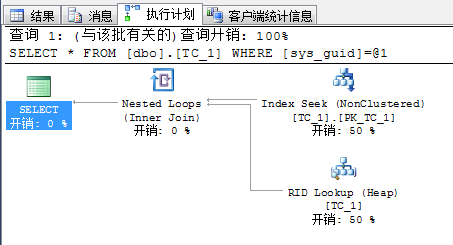 |
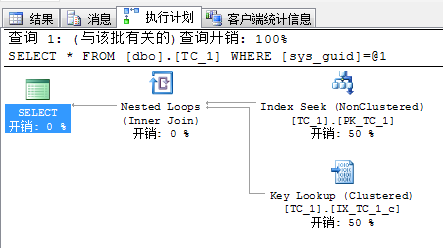 |
| 结果 |  |
 |
| 消息 |
SQL Server 分析和编译时间: SQL Server 执行时间: (1 行受影响) (1 行受影响) SQL Server 执行时间: SQL Server 执行时间: |
SQL Server 分析和编译时间: SQL Server 执行时间: (1 行受影响) (1 行受影响) SQL Server 执行时间: SQL Server 执行时间: |
| 客户端统计信息 |  |
 |
| 对比 | √ | √ |
| 两者几乎一样。也可以认为堆表具有非常微弱的优势,因为栈表的逻辑读取次数略高于堆表。 | ||
SELECT COUNT(*) FROM dbo.TC_1 -- 3.一般期望索引scan(基本不可能seek)
| 堆表 | 栈表 | |
| 执行计划 |  |
 |
| 结果 | 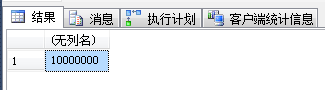 |
 |
| 消息 |
SQL Server 分析和编译时间: SQL Server 执行时间: (1 行受影响) (1 行受影响) SQL Server 执行时间: SQL Server 执行时间: |
SQL Server 分析和编译时间: SQL Server 执行时间: (1 行受影响) (1 行受影响) SQL Server 执行时间: SQL Server 执行时间: |
| 客户端统计信息 |  |
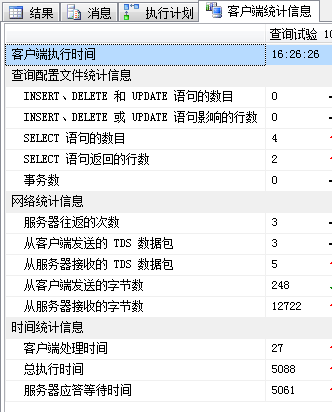 |
| 对比 | √ | √ |
| 可以认为基本没差别。 | ||
SELECT avg(valueF),avg(valueN) FROM dbo.TC_1 WHERE g = 1 GROUP BY g -- 4.一般只能是scan
| 堆表 | 栈表 | |
| 执行计划 |  |
 |
| 结果 | 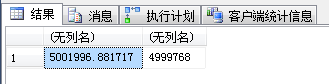 |
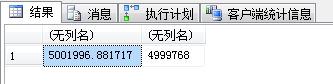 |
| 消息 |
SQL Server 分析和编译时间: SQL Server 执行时间: (1 行受影响) (1 行受影响) SQL Server 执行时间: SQL Server 执行时间: |
SQL Server 分析和编译时间: SQL Server 执行时间: (1 行受影响) (1 行受影响) SQL Server 执行时间: SQL Server 执行时间: |
| 客户端统计信息 | 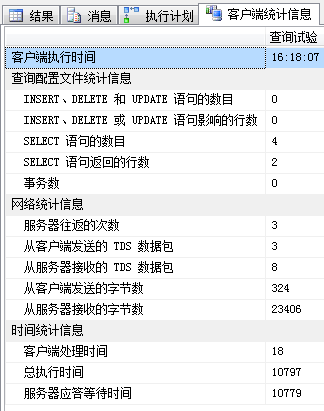 |
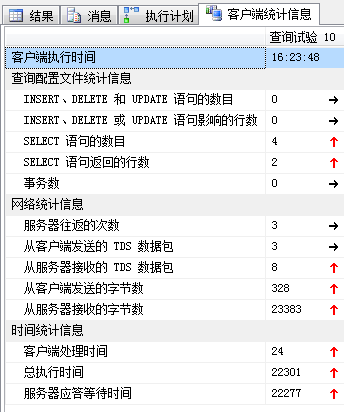 |
| 对比 | √ | √ |
| 堆表具有微弱优势(聚集索引扫描,实际上就等于表扫描了) | ||
- 结论
现实中大表的使用往往不可能只经过聚集索引去查找或统计,也往往会有多个索引,有些甚至高达20个以上的索引(这里不讨论其合理性)。
分两种情况讨论:
1.OLTP:一般认为以1、2、3三类语句为主,再考虑到高并发特点,还必须尽可能避免死锁,并提供一个可以接受的性能,从中找到一个比较满意的平衡点。由于若有修改聚集索引键会引起的所有非聚集索引更新,因此,可以认为栈表比堆表更有可能发生死锁(相同的写入操作涉及的索引可能更多),除非聚集索引是采用单向递增且永不更改的列,否则这将可能引起噩梦般的死锁频发。而堆表不存在某一个索引键修改就能引起其它所有索引的更新,可以认为其写入操作涉及的资源都是直接所需(相同的写入操作涉及的索引只是必需的范围),因此死锁的可能性相对更低。再看两者的性能表现差距,对于人类体验来说,大多数时候是感觉不到的。因此在OLTP系统中,为了减少死锁可能性,可以认为堆表更具有广泛适用性。
那么,栈表是否就没用了呢?答案当然是否定的。
如果能选择出一些单向递增且永不更改(或基本不会更改)的列,并且大部分查询也必须使用这些列作为条件(至少有一个必须的列),在这种情况下,使用满足这些条件的列作为聚集索引,并且选择这些列中使用率最高的一列作为聚集索引的第一列,这通常是会比堆表更好的。
只不过OLTP系统往往查询(包括读和写)是多样化的,避免死锁往往会更重要,因此,在不确定聚集索引是否合理时,使用堆表系统会更稳定;当然,性能上相应的可能会有所降低,只要在能接受的范围内,堆表可以说是更稳妥的选择。
2.OLAP:一般认为3、4两类语句的性能表现更重要,且不存在高并发写入操作(多是夜间定时批量更新)。在表扫描上,堆表反而具有微弱优势,这可能比较出人意料。我认为这应该是由于聚集索引扫描过程中需要访问更多的磁盘,因为聚集索引本身除了叶结点,还有B+树非叶结点的数据,而堆表相当于只有聚集索引的叶结点的数据,这导栈表扫描的致逻辑读和物理读比堆表扫描更高。但是除了扫描,更多的查询也一样是只需要索引seek就能查到结果,因此在OLAP系统,可以认为栈表更具有广泛适用性。
- 题外话
OLTP中的小表由于行数少,无论是栈表还是堆表,对于人类体验来说,区别一般都不会太大,往往是不可能感觉到的,因此不会成为关注的焦点,所以大多数小表可以认为无所谓;但如果存在频繁更新聚集索引键值且表上的索引总数也不少,同时还存在高并发,并且切实的导致了不少的死锁,则建议重新选择合适的聚集索引或使用堆表吧。
以上均以个人经验和测试结果得出的结论,欢迎大家拍砖指正!
SQL Server 堆表与栈表的对比(大表)的更多相关文章
- SQL Server ->> 深入探讨SQL Server 2016新特性之 --- Temporal Table(历史表)
原文:SQL Server ->> 深入探讨SQL Server 2016新特性之 --- Temporal Table(历史表) 作为SQL Server 2016(CTP3.x)的另一 ...
- 【SQL Server高可用性】数据库复制:SQL Server 2008R2中通过数据库复制,把A表的数据复制到B表
原文:[SQL Server高可用性]数据库复制:SQL Server 2008R2中通过数据库复制,把A表的数据复制到B表 经常在论坛中看到有人问数据同步的技术,如果只是同步少量的表,那么可以考虑使 ...
- SQL Server 堆表行存储大小(Record Size)
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 堆表行记录存储格式(Heap) 案例分析(Case) 参考文献(References) 二.背 ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- SQL Server时间粒度系列----第7节日历数据表详解
本文目录列表: 1.时间粒度有关描述 2.时间维度有关功能函数3.日历数据表 4.日历数据表数据填充 5.总结语 6.参考清单列表 时间粒度有关描述 将该系列涉及到的时间粒度以及分钟以下的粒度 ...
- (转)SQL server 容易让人误解的问题之 聚集表的物理顺序问题
对于MS SQL server 数据库,有几个容易让人产生误解的问题,对于这几个问题,即使很多 SQL server DBA 都有错误认识或者认识不充分,所以我想撰文几篇,把这些容易理解错误的问题前前 ...
- SQL SERVER 中 实现主表1行记录,子表多行记录 整合成一条虚拟列
表中有这样的记录,简单的主子表,现要想通过left join 语句把两表关联起来 select * from tbl_diary_reback a left join tbl_diary_reback ...
- SQL SERVER 判断是否存在并删除某个数据库、表、视图、触发器、储存过程、函数
-- SQL SERVER 判断是否存在某个触发器.储存过程 -- 判断储存过程,如果存在则删除IF (EXISTS(SELECT * FROM sysobjects WHERE name='proc ...
- SQL Server 2012 “阻止保存要求又一次创建表”的更改问题的设置方法
我们在用SQL Server 2012 建完表后,插入或改动随意列时,提示:当用户在在SQL Server 2012企业管理器中更改表结构时.必需要先删除原来的表.然后又一次创建新表,才干完毕表的更改 ...
随机推荐
- php验证身份证号码正确性
发布:JB01 来源:脚本学堂 [大 中 小] 分享一例php代码,用于验证身份证号码的正确性,用到了preg_match.preg_replace函数,有需要的朋友可以参考学习下.本文转 ...
- phpcms v9后台多表查询分页代码
phpcms v9里面自带的listinfo分页函数蛮好用的,可惜啊.不支持多表查询并分页. 看了一下前台模板层支持get标签,支持多表查询,支持分页.刚好可以把这个功能搬到后台来使用. 我们现在对g ...
- 字符编码笔记:ASCII,Unicode和UTF-8【转载】
作者: 阮一峰 日期: 2007年10月28日 今天中午,我突然想搞清楚Unicode和UTF-8之间的关系,于是就开始在网上查资料. 结果,这个问题比我想象的复杂,从午饭后一直看到晚上9点,才算初步 ...
- VM 启动时报错:Failed to lock the file
http://www.cnblogs.com/kristain/articles/2491966.html Reason: Failed to lock the fileGoogle 了一下, 在網路 ...
- ios阻止锁屏 --老代码,供参考
// Disable the idle timer [[UIApplication sharedApplication] setIdleTimerDisabled: YES]; // Or fo ...
- Memcached(四)Memcached的CAS协议
1. 什么是CAS协议很多中文的资料都不会告诉大家CAS的全称是什么,不过一定不要把CAS当作中国科学院(China Academy of Sciences)的缩写.Google.com一下,CAS是 ...
- Nhibernate 一对多,多对一配置
先来分析下问题,这里有两张表:Users(用户表) U和PersonalDynamic(用户动态表) PD,其中PD表的UserId对应U表的Id 如图: 现在映射这两张表: 如图: User.hbm ...
- javascript 闭包暴露句柄和命名冲突的解决方案
暴露 最近在琢磨前端Js开源项目的东西,然后就一直好奇他们是怎么句柄暴露出来的,特整理一下两种方法. 将对象悬挂到window下面. 不使用var进行变量声明.下面上代码: (function(win ...
- UVA 12647 Balloon
这是一个线段树的题目: 我记得一个月前在cf上也做过一个类似的题目: #include<cstdio> #include<cstring> #include<algori ...
- IgnoreRoute——注册路由
routes.IgnoreRoute("home/about"); 这句话,当Route遇到Home/About的Url时,这段URL将被忽略. 效果图 需要注意的是这里route ...