常用排序算法java实现
写在前面:纸上得来终觉浅。基本排序算法的思想,可能很多人都说的头头是到,但能说和能写出来,真的还是有很大区别的。
今天整理了一下各种常用排序算法,当然还不全,后面会继续补充。代码中可能有累赘或错误的地方,欢迎指正。
1、冒泡排序
冒泡排序是最简单的排序算法之一,其具体思想就是将相邻两个元素进行比较,大的元素交换到最后面(升序),最大的元素移动的过程就像水冒泡一样。冒泡排序中,需要对n个元素进行冒泡,每次冒泡又需要进行n的数量级次比较,所以冒泡排序的时间复杂度为O(n^2)
/**
* 冒泡排序
*/
public void bubbleSort(int[] array) {
if(array == null || array.length <= 0) {
return ;
}
for(int i = 0; i < array.length - 1; i++) {
for(int j = 0; j < array.length - i - 1; j++) {
if(array[j] > array[j + 1]) {
int temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
}
}
}
}
当然,比较理想的状态下,我们想,如果在待排序数组已经是有序的情况下,我们冒泡一次,发现交换次数为零,那么后面的比较与交换就不必再进行,所以,这种情况下,冒泡排序的最好情况时间复杂度是O(n),我们所需要做的就是在每次冒泡过程中添加一个记录交换次数的计数器。 如下:
/**
* 冒泡排序2
*/
public void bubbleSort2(int[] array) {
if(array == null || array.length <= 0) {
return ;
}
int swapCount = 0; //天加计数器记录每趟交换次数
for(int i = 0; i < array.length - 1; i++) {
swapCount = 0; //清零
for(int j = 0; j < array.length - i - 1; j++) {
if(array[j] > array[j + 1]) {
int temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
swapCount++;
}
}
if(swapCount == 0) { //这一趟冒泡过程没有发生交换,待排数组已经有序,直接退出循环
break;
}
}
}
2、选择排序
选择排序集本思想和冒牌排序相似,都是通过一次遍历比较后得到最值。与冒泡排序不同的是,冒泡排序需要相邻元素每次比较然后交换。而选择排序是经过一次遍历比较记录下最值,也就是经过整体选择,然后将选出的元素放在合适的位置。选择排序对冒泡排序进行了一定的优化,比较的次数没有发生变化,但省去了相邻元素频繁的交换。在时间复杂度上,依然是O(n^2);
public void selectSort(int[] array) {
if(array == null || array.length <= 0) {
return;
}
for(int i = 0; i < array.length - 1; i++) {
int minIndex = i;
int minNum = array[i];
for(int j = i; j < array.length; j++) {
if(array[j] < minNum) {
minNum = array[j];
minIndex = j; //记录最小值的下标
}
}
if(minIndex != i) { //若最小值不是在i处,将最小值交换到前面
int temp = array[i];
array[i] = array[minIndex];
array[minIndex] = temp;
}
}
}
3、插入排序
插入排序与冒泡,选择排序不同。冒泡与选择都是通过一次遍历比较确定出一个最值,然后放在合适的位置。而插入排序是通过比较来找到合适的位置进行插入,例如待排数组:3,2,6,4,8;第一个数3,已经有序,然后是2,与3比较,发现比3小,插到3前面:2,3,6,4,8,然后是6,6比3大,插到3后面,2,3,6,4,8,然后是4,4比6小并且比3大,则插到3后面6前面:2,3,4,6,8,最后是8,比6大,插到6的后面,完成插入排序。冒泡排序和选择排序在进行一次排序后,就能唯一确定一个元素的位置,而插入排序却不行。最好情况,若待排序列已经有序,则插入排序的时间复杂度为O(n)。插入排序的平均时间复杂度依然是O(n^2)。
/**
*插入排序
*/ public void insertSort(int[] array) {
if(array == null || array.length <= 0) {
return;
}
for(int i = 0; i < array.length; i++) {
int temp = array[i];
int j = i;
while(j > 0 && temp < array[j - 1]) { //向后移动
array[j] = array[j - 1];
j--;
}
array[j] = temp;
}
}
4、希尔排序
我这里讲希尔排序放在直接插入排序算法后面,是因为希尔排序是插入排序的一种高效实现方法。希尔排序将整个待排序列通过划分成若干子序列来分别进行插入,分割子序列的方法是通过一个增量来达到。在插入排序中,如果待排序数组是有序的,那么,插入排序的只需要遍历一次数组,不用移动任何元素,就能完成排序,且时间复杂度为O(n)。所以利用插入排序,若数组是基本有序的,那么直接插入排序效率将会提高。希尔排序就是利用这个特点。希尔排序由于前面的插入排序中记录的关键字是和同一子序列中的前一个记录的关键字进行比较,因此关键字较小的记录就不是一步一步地向前挪动,而是跳跃式地往前移,从而使得进行最后一趟排序时,增量为1,相当于直接插入排序,但是这个时候,数组已经基本有序,只要作记录的少量比较和移动即可。因此希尔排序的效率要比直接插入排序高。希尔排序的时间复杂度取决于初始增量的选取,导致其时间复杂度很难计算,合理的选取n,时间复杂度可以达到O(n^1.3)
/**
* 一次增量为n的插入排序,可以对比直接插入排序
* @param array 待排序数组
* @param n 增量
*/ public void oneShellSort(int[] array,int n) {
if(array == null || array.length <= 0 || n <1) {
return;
}
for(int i = n; i < array.length; i++) {
int temp = array[i];
int j = i;
while(j >= n && temp < array[j - n]) {
array[j] = array[j - n];
j = j - n;
}
array[j] = temp;
}
}
/**
* 希尔排序,n递减
* @param array待排数组
* @param n 初始增量
*/
public void shellSort(int[] array,int n) {
if(array == null || array.length <= 0 || n <1) {
return;
}
for(int i = n; i >=1; i--) {
oneShellSort(array,i); //i等于1的时候相当于直接插入排序,不过这时已经基本有序了,所以快
}
}
5、快速排序
快速排序可能是排序中经典排序了,我们平时经常会看到快速排序的字眼,不管是你刚学习的考试中, 还是面试题中。那么,快速排序到底是什么样?一种思想其实是这样,快速排序是取一个基数作为对比基准,在把大的数向后移的同时将比较小的数向前移。快速排序经过一次排序后就能唯一确定一个元素的位置,这个元素将待排序序列分为两个部分,一部分所有元素小于等于该数,另一部分所有元素大于等于该数。这两部分的元素又可以递归进行快速排序。快速排序不是一种稳定的排序,时间复杂度和待排序列的初始情况有很大关系。最坏情况下(待排序数组已经有序),时间复杂度为O(n^2);平均时间复杂度为O(nlog2n)。
快速排序分为两个步骤,一是要实现将待排序数组按照基数分为两部分,二是要递归实现排序。
/**
* 快速排序每次得到一个确定的位置,再根据这个位置将数组分为两部分
* @param array 待排序数组
* @param left 左边界
* @param right 右边界
* @return 确定位置的元素的下标
*/
public int getMiddleIndex(int[] array,int left,int right) {
if(array == null || array.length <= 0) {
return 0;
}
if(left >= right) {
return 0;
}
int pivotNum = array[left]; //选取最左边的值为基准值
while(left < right) {
while(left < right && array[right] >= pivotNum) { //从后开始找到小于基准值的数移到前面
right--;
}
array[left] = array[right];
while(left < right && array[left] <= pivotNum) { //从前开始找到大于基准值的数移到后面
left++;
}
array[right] = array[left];
}
array[left] = pivotNum;//基准值的确定位置
return left;
}
/**
* 快速排序
*/
public void quickSort(int[] array, int left, int right) {
if(array == null || array.length <= 0 || left >= right) {
return;
}
int minIndex = getMiddleIndex(array,left,right); //将待排序数组分为两部分
quickSort(array,left, minIndex - 1);//左边递归
quickSort(array,minIndex + 1,right);//右边递归
}
6、堆排序
堆排序实质上是借助堆这一结构来实现排序,堆其实是一种完全二叉树结构,父亲节值点大于子节点的堆称为大顶堆,父节点值小于子节点的值称为小顶堆,很形象的名字。那么,对于待排序数组,如何通过堆来进行排序呢? 这里用大顶堆来举例。满足大顶堆的结构,那么堆的根肯定就是最大值,假如我们要按照升序排列,当我们将最大值和最后一个值交换后,剩余元素如何重新构建一个新的大顶堆?只要又能构建出一个大顶堆,就可以将堆顶元素和倒数第二个元素进行交换,接下来就是迭代的过程了。所以,我们需要
解决的问题就有两个:
1、如何将给的待排序数组构建成一个满足条件的堆?
2、将堆顶元素和最后一个元素交换后,如何调整成一个新的满足条件的堆。
堆排序实例过程,参考:http://blog.csdn.net/xiaoxiaoxuewen/article/details/7570621/
我们可以直接使用线性数组来表示一个堆,由初始的无序序列建成一个堆就需要自底向上从第一个非叶元素开始挨个调整成一个堆。比较当前堆顶元素的左右孩子节点,因为除了当前的堆顶元素,左右孩子堆均满足条件,这时需要选择当前堆顶元素与左右孩子节点的较大者(大顶堆)交换,直至叶子节点。我们称这个自堆顶自叶子的调整成为筛选。每次调整堆的时间为logn,一共n个数,需要n次调整,所以堆排序的时间复杂度为:O(nlogn)
/**
* 调整一个节点,使自该节点以后满足堆的要求
* 经过对构建后,若一个节点有左右子树,则其左右子树已经满足堆的要求
* @param array
* @param begin
* @param end
*/
public void headAdjust(int[] array, int begin, int end) {
if(array == null || array.length <= 0 || begin >= end || begin >= array.length) {
return;
}
int temp = array[begin];
for(int i = 2 * begin + 1; i <= end; i = i * 2 + 1) {
if(i < end && array[i] < array[i + 1]) {
i++;
}
if(temp > array[i]) {
break;
}
array[begin] = array[i];
begin = i;
}
array[begin] = temp;
}
/**
* 利用大顶堆,实现数组升序排序
* @param array
*/ public void heapSort(int[] array) {
if(array == null || array.length <= 0) {
return;
}
//第一次构建堆,从第一个非叶子节点开始调整,一直到根节点(数组中第一个数)
for(int i = array.length / 2; i >= 0; i--) {
headAdjust(array,i,array.length - 1);
}
//每次交换堆顶元素到数组后面,前面剩余数组以堆顶元素进行一次调整堆
for(int i = 1; i <= array.length - 1; i++) {
int temp = array[0];
array[0] = array[array.length - i];
array[array.length - i] = temp;
headAdjust(array,0,array.length - 1 - i);
} }
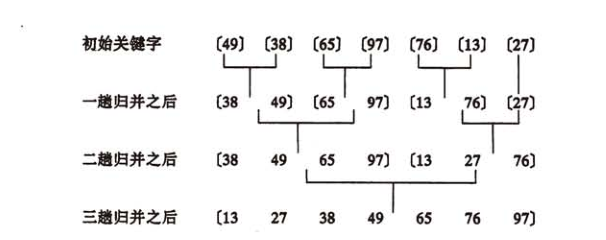
7、归并排序
归并排序使用了递归分治的思想,其基本思想是,先递归划分子问题,然后合并结果。把待排序列看成由两个有序的子序列,然后合并两个子序列,然后把子序列看成由两个有序序列。倒着来看,其实就是先两两合并,然后四四合并。最终形成有序序列。归并排序需要额外的空间来存储合并时的中间数组,空间复杂度为O(n),时间复杂度为O(nlogn)
归并排序过程:
/**
* 归并排序
* @param array
* @param left
* @param right
*/
public void mergeSort(int[] array, int left, int right) {
if(array == null || array.length == 0 || right >= array.length ) {
return ;
}
if(left >= right) {
return;
}
int mid = (left + right) / 2; //分成两部分
mergeSort(array, left, mid); //左右递归
mergeSort(array, mid + 1, right);
merge(array,mid,left,right);//在原数组上进行合并
}
/**
* 归并排序的合并操作
* @param array
* @param mid
* @param left
* @param right
*/
public void merge(int[] array, int mid, int left, int right) {
if(array == null || array.length == 0) {
return;
}
int[] temp = new int[right - left + 1]; int i = left;
int j = mid + 1;
int k = 0;
while(i <= mid && j <= right) {
if(array[i] < array[j]) {
temp[k] = array[i];
i++;
} else {
temp[k] = array[j];
j++;
}
k++;
}
while(i <= mid) {//若左边有剩余
temp[k++] = array[i++];
}
while(j <= right) {//若右边有剩余
temp[k++] = array[j++];
}
k = 0;
while(left <= right) {//有序数组复制到原数组相应位置
array[left++] = temp[k++];
}
}
8、计数排序
计数排序是利用空间换时间的一种排序方式,一般来说,基于比较的排序方式(前面的冒泡排序,选择排序,直接插入排序,快速排序,归并排序等)时间复杂度最低是O(n^2)。但是计数排序在利用较多空间后的时间复杂度可以达到O(n);
计数排序基本思想:
将待排序列的数字作为排序数组的下标,遍历一次待排序列,排序数组统计每个位置出现的次数。然后一次输出即可。当然,因为是待排数据作为数组下标,若待排序列存在负数,则需要找到最小的负数,所有数加上一个值转换成正数,最后的输出再转换回去。
/**
* 计数排序
* @param array
*/
public void countSort(int[] array) {
if(array == null || array.length == 0) {
return;
}
int maxNum = array[0];
for(int i = 0; i < array.length; i++) { //找出待排序列的最大值
if(array[i] > maxNum) {
maxNum = array[i];
}
}
int[] sortArray = new int[maxNum + 1]; //新建一个排序数组,加1 为了让最大值下标能放排序数组
for(int i = 0; i < array.length; i++) { //按照下标放入排序数组中
sortArray[array[i]] += 1;
}
int k = 0;
for(int i = 0; i < sortArray.length; i++) {
if(sortArray[i] == 0) {
continue;
}
while(sortArray[i] > 0) {
array[k++] = i; //sortArray[i]>0的情况是存在相同的值
sortArray[i]--;
}
}
}
这里其实计数排序可以有一个小的改进,就是,我们其实不需要创建maxNum长的排序数组,而只需要创建(maxNum - minNum + 1)长的数组就足够。
例如给定无序数组 { 2, 6, 3, 4, 5, 10, 9 },处理过程如下:


实现代码如下:
/**
* 计数排序小改进
* @param array
*/
public void countSort2(int[] array) {
if(array == null || array.length == 0) {
return;
}
int maxNum = array[0];
int minNum = array[0];
for(int i = 0; i < array.length; i++) { //找出待排序列的最大和最小值
if(array[i] > maxNum) {
maxNum = array[i];
}
if(array[i] < minNum) {
minNum = array[i];
}
}
//新建一个排序数组,最大值减去最小值加1,节省了一定的空间
int[] sortArray = new int[maxNum - minNum + 1];
for(int i = 0; i < array.length; i++) { //按照下标放入排序数组中,注意减去minNum
sortArray[array[i] - minNum] += 1;
}
int k = 0;
for(int i = 0; i < sortArray.length; i++) {
if(sortArray[i] == 0) {
continue;
}
while(sortArray[i] > 0) {
array[k++] = i + minNum; //sortArray[i]>0的情况是存在相同的值,注意加上minNum
sortArray[i]--;
}
}
}
9、桶排序
上面说到计数排序的小改进,真的只是小改进,因为如果出现:3,4,100,10000。这样的待排序序列,依然会消耗大量的空间。那么有没有更进一步的改进呢? 那就是桶排序啦。。
桶排序比较复杂,但核心思路来自计数排序,将待排序数组的maxNum - minNum按区间分成n个桶,以下分析来自:http并按照一定的映射函数将待排序序列每个值映射到相应的桶中,然后对每个桶排序,最后一次输出桶中的数据。以下分析来自:http://hxraid.iteye.com/blog/647759。
桶排序基本思想: 假设有一组长度为N的待排关键字序列K[1....n]。首先将这个序列划分成M个的子区间(桶) 。然后基于某种映射函数 ,将待排序列的关键字k映射到第i个桶中(即桶数组B的下标 i) ,那么该关键字k就作为B[i]中的元素(每个桶B[i]都是一组大小为N/M的序列)。接着对每个桶B[i]中的所有元素进行比较排序(可以使用快排)。然后依次枚举输出B[0]....B[M]中的全部内容即是一个有序序列。
桶排序的映射:
bindex=f(key) 其中,bindex 为桶数组B的下标(即第bindex个桶), k为待排序列的关键字。桶排序之所以能够高效,其关键在于这个映射函数,它必须做到:如果关键字k1<k2,那么f(k1)<=f(k2)。
也就是说B(i)中的最小数据都要大于B(i-1)中最大数据。很显然,映射函数的确定与数据本身的特点有很大的关系,我们下面举个例子:假如待排序列K= {49、 38 、 35、 97 、 76、 73 、 27、 49 }。这些数据全部在1—100之间。因此我们定制10个桶,然后确定映射函数f(k)=k/10。则第一个关键字49将定位到第4个桶中(49/10=4)。依次将所有关键字全部堆入桶中,并在每个非空的桶中进行快速排序后得到如下图所示:

/**
* 桶排序
* @param array
*/
public void bucketSort(int[] array) {
if(array == null || array.length <= 0) {
return;
} int maxNum = array[0];
int minNum = array[0];
for(int i = 0; i < array.length; i++) { //找出待排序列的最大和最小值
if(array[i] > maxNum) {
maxNum = array[i];
}
if(array[i] < minNum) {
minNum = array[i];
}
} int bucketNum = (maxNum - minNum) / array.length; //bucketNum是桶的个数
ArrayList<List<Integer>> buckets = new ArrayList<>(); //桶的链表,每个节点使一个桶 for(int i = 0; i <= bucketNum; i++) {
buckets.add(new ArrayList<Integer>()); //初始化桶
} for(int i = 0; i < array.length; i++) {
int num = (array[i] - minNum) / array.length;
buckets.get(num).add(array[i]);
} for(int i = 0; i <= bucketNum; i++) {
Collections.sort(buckets.get(i)); //偷个懒,jdk1.8该方法采用二分插入法排序
} int k = 0;
for(int i = 0; i <= bucketNum; i++) {//所有桶的元素顺序输出
for(int num: buckets.get(i)) {
array[k++] = num;
}
}
}
10、总结
又到了分析各种算法时间复杂度,空间复杂度的时候了,万能的表格出来!-------……&……&……>>>>>>>:
| 排序方法 | 最好时间复杂度 | 最坏时间复杂度 | 平均时间复杂度 | 需要的辅助存储 | 算法的稳定性 |
| 冒泡排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 不稳定 |
| 插入排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 希尔排序 | O(n^1.3) | -- | -- | O(1) | 不稳定 |
| 快速排序 | O(nlogn) | O(n^2) | O(nlogn) | O(logn) | 不稳定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不稳定 |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 稳定 |
| 计数排序 | O(n) | O(n) | O(n) | O(n) | |
| 桶排序 |
0(n) |
只有一个桶,取决 于桶内排序算法 |
O(N+C),其中C=N*(logN-logM) M是桶的个数 |
O(N+M) m为桶的个数 |
另外,关于算法的稳定性:
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,ri=rj,且ri在rj之前,而在排序后的序列中,ri仍在rj之前,则称这种排序算法是稳定的;否则称为不稳定的。
其中直接插入排序是比较简单的,在序列基本有序或者n较小时,直接插入排序是好的方法,因此常将它和其他的排序方法,如快速排序、归并排序等结合在一起使用。
参考链接:
http://www.cnblogs.com/wxisme/ 桶排序分析:http://hxraid.iteye.com/blog/647759
2017-03-14 17:25:07 Gonjan
常用排序算法java实现的更多相关文章
- 常用排序算法--java版
package com.whw.sortPractice; import java.util.Arrays; public class Sort { /** * 遍历一个数组 * @param sor ...
- Java常用排序算法+程序员必须掌握的8大排序算法+二分法查找法
Java 常用排序算法/程序员必须掌握的 8大排序算法 本文由网络资料整理转载而来,如有问题,欢迎指正! 分类: 1)插入排序(直接插入排序.希尔排序) 2)交换排序(冒泡排序.快速排序) 3)选择排 ...
- Java 常用排序算法/程序员必须掌握的 8大排序算法
Java 常用排序算法/程序员必须掌握的 8大排序算法 分类: 1)插入排序(直接插入排序.希尔排序) 2)交换排序(冒泡排序.快速排序) 3)选择排序(直接选择排序.堆排序) 4)归并排序 5)分配 ...
- 我们一起来排序——使用Java语言优雅地实现常用排序算法
破阵子·春景 燕子来时新社,梨花落后清明. 池上碧苔三四点,叶底黄鹂一两声.日长飞絮轻. 巧笑同桌伙伴,上学径里逢迎. 疑怪昨宵春梦好,元是今朝Offer拿.笑从双脸生. 排序算法--最基础的算法,互 ...
- Java常用排序算法及性能测试集合
测试报告: Array length: 20000 bubbleSort : 573 ms bubbleSortAdvanced : 596 ms bubbleSortAdvanced2 : 583 ...
- 常用排序算法的总结以及编码(Java实现)
常用排序算法的总结以及编码(Java实现) 本篇主要是总结了常用算法的思路以及相应的编码实现,供复习的时候使用.如果需要深入进行学习,可以使用以下两个网站: GeeksForGeeks网站用于学习相应 ...
- 面试中常用排序算法实现(Java)
当我们进行数据处理的时候,往往需要对数据进行查找操作,一个有序的数据集往往能够在高效的查找算法下快速得到结果.所以排序的效率就会显的十分重要,本篇我们将着重的介绍几个常见的排序算法,涉及如下内容: 排 ...
- 排序算法(Java实现)
这几天一直在看严蔚敏老师的那本<数据结构>那本书.之前第一次学懵懵逼逼,当再次看的时候,发觉写的是非常详细,非常的好. 那就把相关的排序算法用我熟悉的Java语言记录下来了.以下排序算法是 ...
- 6种基础排序算法java源码+图文解析[面试宝典]
一.概述 作为一个合格的程序员,算法是必备技能,特此总结6大基础算法.java版强烈推荐<算法第四版>非常适合入手,所有算法网上可以找到源码下载. PS:本文讲解算法分三步:1.思想2.图 ...
随机推荐
- 盗版SQL Server的性能限制
盗版SQL Server的性能限制 微软的SQL Server产品分为两种卖法1.盒装 :Server+CAL授权方式(SQL2017取消了Server+CAL授权方式,盗版序列号,一般电脑城有卖光盘 ...
- java构造器执行顺序一个有趣的简单实例
一 Animal为父类,构造器中调用public(default.protected) say方法,Dog继承了Animal,并重载了say方法.新建Dog对象,查看运行结果,若将Animal中say ...
- Linux 使用 cp 命令强制覆盖功能
Q:我们平常在Linux中使用 cp 命令时,会发现将一个目录中文件复制到另一个目录具有相同文件名称时, 即使添加了 -rf 参数强制覆盖复制时,系统仍然会提示让你一个个的手工输入 y 确认复制,令人 ...
- CSS Sprites使用
CSS Sprites在国内很多人叫css精灵,是一种网页图片应用处理方式.它允许你将一个页面涉及到的所有零星图片都包含到一张大图中去,这样一来,当访问该页面时,载入的图片就不会像以前那样一幅一幅地慢 ...
- linux无密码连接
先确保所有主机的防火墙处于关闭状态. 在主机A上执行如下: 1. $cd ~/.ssh 2. $ssh-keygen -t rsa -----然后一直按回车键,就会按照默认的选项将生成的密钥保存在. ...
- 5.For loops
for 循环语句 在需要重复执行代码的时候,for循环常常被用到.我们可以让一行代码执行10次: for i in range(1,11): print(i) 最后一个数字11是不包含在内 ...
- js 的数学处理方法
1.javascript取整方法floor.round.ceil floor向下取整: Math.floor(0.20); Math.floor(0.90); Math.floor(-0.90); / ...
- Django之路由分发系统
web的基本工作流程 首先,我们先来思考一下我们平常在上网浏览网页时候的场景,大致就是打开一个web浏览器,输入某一个网站的地址,然后转到该网址,在浏览器中得到该网址的页面.从这个场景中我们可以抽象出 ...
- strace命令【转】
strace命令使用: strace常用来跟踪进程执行时的系统调用和所接收的信号. 在Linux世界,进程不能直接访问硬件设备,当进程需要访问硬件设备(比如读取磁盘文件,接收网络数据等等)时,必须由用 ...
- Python日志监控系统处理日志(pyinotify)
前言 最近项目中遇到一个用于监控日志文件的Python包pyinotify,结合自己的项目经验和网上的一些资料总结一下,总的原理是利用pyinotify模块监控日志文件夹,当日志到来的情况下,触发相应 ...