Centos下装eclipse测试Hadoop
(一),安装eclipse
1,下载eclipse,点这里
2,将文件上传到Centos7,可以用WinSCP
3,解压并安装eclipse
[root@Master opt]# tar zxvf '/home/s/eclipse-jee-neon-1a-linux-gtk-x86_64.tar.gz' -C/opt ---------------> 建立文件:[root@Master opt]# mkdir /usr/bin/eclipse ------------------》添加链接,即快捷方式:[root@Master opt]# ln -s /opt/eclipse/eclipse /usr/bin/eclipse -----------》点击eclipse,即可启动了
(二),建立Hadoop项目
1,下载hadoop plugin 2.7.3 链接:http://pan.baidu.com/s/1i5yRyuh 密码:ms91
2,解压上述jar包插件,放到eclipse中plugins中,并重启eclipse
2, 在eclipse中加载dfs库,点击Windows 工具栏-------->选择show view如图:
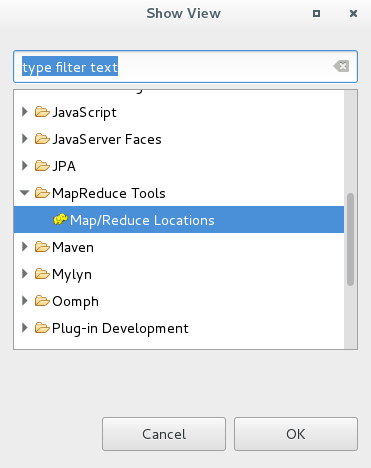
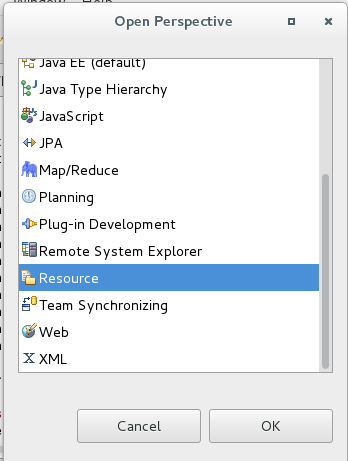
2,打开resource 点击Window ----->Perspective----------->open Perspective 选择resource:
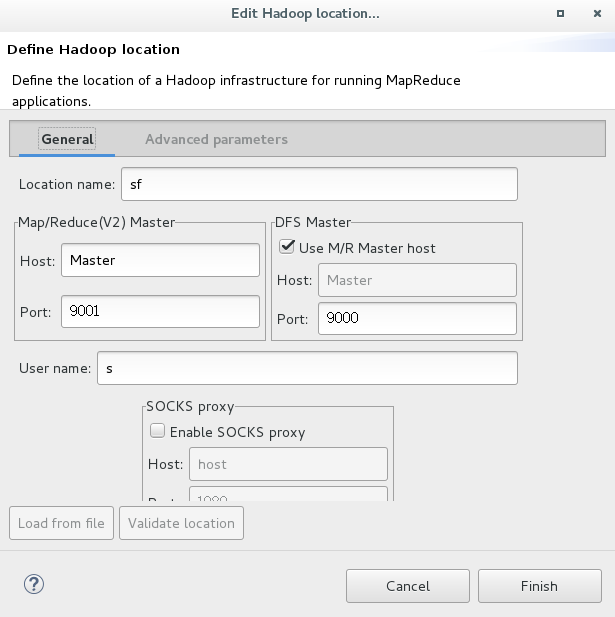
3,配置连接端口,点击eclipse下放的MapResource Location,点击添加:其中port号按照hdfs-site.xml 和core-site.xml来填写。
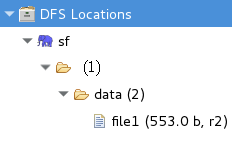
4,上传输入文件:使用hdfs dfs -put /home/file1 /data 即可在eclipse中看到如下:(要确保各个机器的防火墙都关闭,出现异常可以暂时不用关,后面跑下例子就全没了,呵呵)
(三),测试WordCount程序
1,新建项目:点击new ------------》project ----------->Map Reduce,如图:
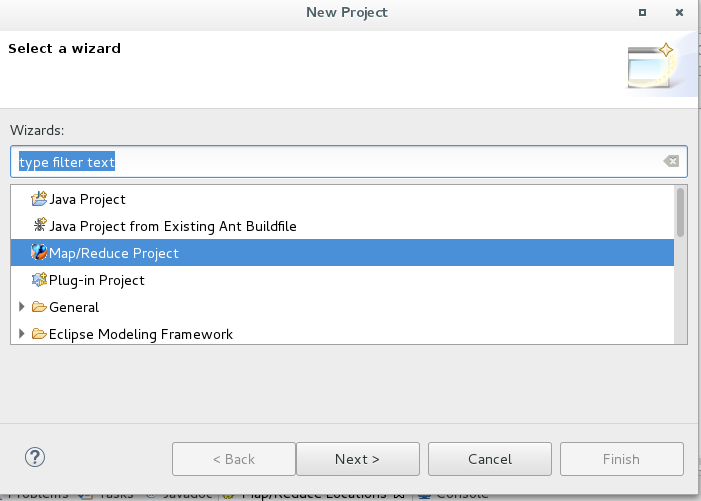
2,给项目配置本地的hadoop文件,圆圈处写本地hadoop的路径:
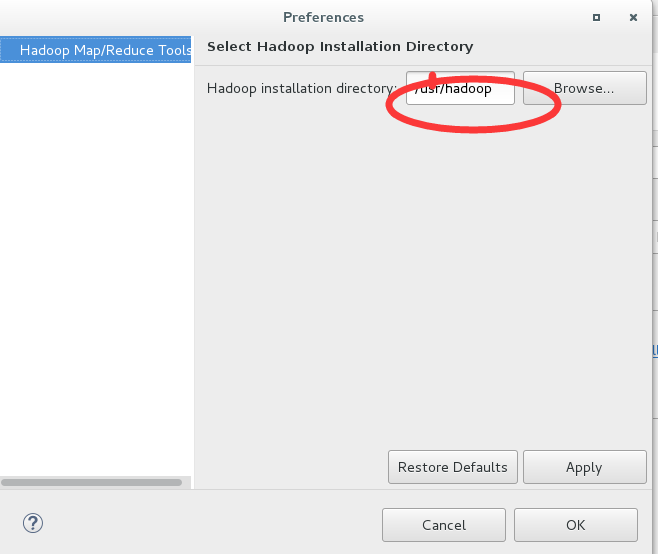
3,新建个mappert类,写如下代码:
- package word;
- import java.io.IOException;
- import java.util.StringTokenizer;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
- public class mapper {
- public static class TokenizerMapper
- extends Mapper<Object, Text, Text, IntWritable>{
- private final static IntWritable one = new IntWritable(1);
- private Text word = new Text();
- public void map(Object key, Text value, Context context
- ) throws IOException, InterruptedException {
- StringTokenizer itr = new StringTokenizer(value.toString());
- while (itr.hasMoreTokens()) {
- word.set(itr.nextToken());
- context.write(word, one);
- }
- }
- }
- public static class IntSumReducer
- extends Reducer<Text,IntWritable,Text,IntWritable> {
- private IntWritable result = new IntWritable();
- public void reduce(Text key, Iterable<IntWritable> values,
- Context context
- ) throws IOException, InterruptedException {
- int sum = 0;
- for (IntWritable val : values) {
- sum += val.get();
- }
- result.set(sum);
- context.write(key, result);
- }
- }
- public static void main(String[] args) throws Exception {
- Configuration conf = new Configuration();
- String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
- if (otherArgs.length != 2) {
- System.err.println(otherArgs.length);
- System.err.println("Usage: wordcount <in> <out>");
- System.exit(2);
- }
- Job job = new Job(conf, "word count");
- job.setJarByClass(mapper.class);
- job.setMapperClass(TokenizerMapper.class);
- job.setCombinerClass(IntSumReducer.class);
- job.setReducerClass(IntSumReducer.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
- FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
- FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
- System.out.print("ok");
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
- }
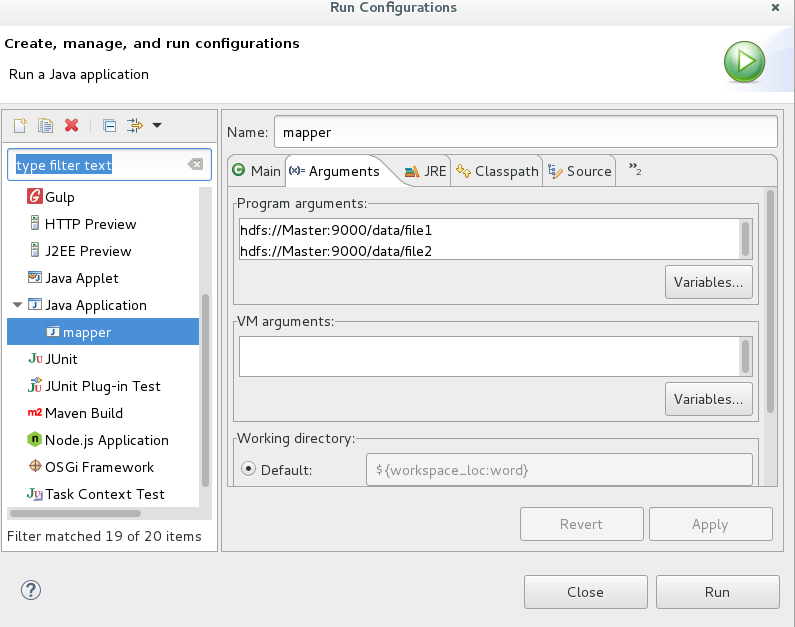
2,点击run as ------------>RunConfigurations ---------->设置input和output文件参数
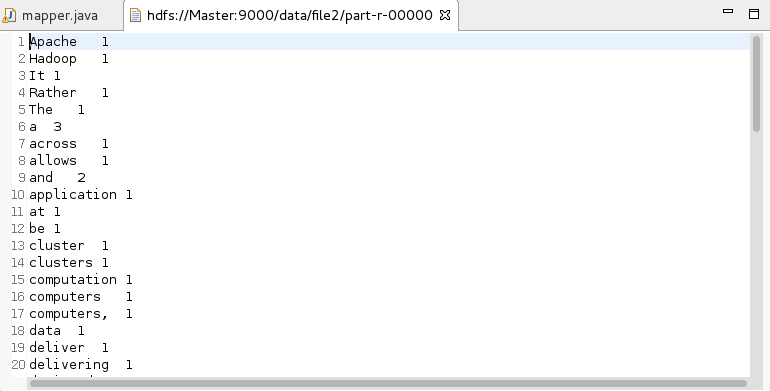
3,点击run,查看结果
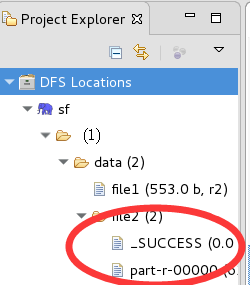
文件的内容:
Centos下装eclipse测试Hadoop的更多相关文章
- 基于CentOS与VmwareStation10搭建hadoop环境
基于CentOS与VmwareStation10搭建hadoop环境 目 录 1. 概述.... 1 1.1. 软件准备.... 1 1.2. 硬件准备.... 1 2. 安装与配置虚拟机.. ...
- 基于Eclipse搭建Hadoop源码环境
Hadoop使用ant+ivy组织工程,无法直接导入Eclipse中.本文将介绍如何基于Eclipse搭建Hadoop源码环境. 准备工作 本文使用的操作系统为CentOS.需要的软件版本:hadoo ...
- Eclipse导入Hadoop源码项目及编写Hadoop程序
一 Eclipse导入Hadoop源码项目 基本步骤: 1)在Eclipse新建一个java项目[hadoop-1.2.1] 2)将Hadoop压缩包解压目录src下的core,hdfs,mapred ...
- Centos 7 配置单机Hadoop
Centos 7 配置单机Hadoop 2018年10月11日 09:48:13 GT_Stone 阅读数:82 系统镜像:CentuOS-7-x86_64-Everything-1708 Jav ...
- MapReduce编程入门实例之WordCount:分别在Eclipse和Hadoop集群上运行
上一篇博文如何在Eclipse下搭建Hadoop开发环境,今天给大家介绍一下如何分别分别在Eclipse和Hadoop集群上运行我们的MapReduce程序! 1. 在Eclipse环境下运行MapR ...
- 基于Eclipse的Hadoop应用开发环境配置
基于Eclipse的Hadoop应用开发环境配置 我的开发环境: 操作系统ubuntu11.10 单机模式 Hadoop版本:hadoop-0.20.1 Eclipse版本:eclipse-java- ...
- Linux下使用Eclipse开发Hadoop应用程序
在前面一篇文章中介绍了如果在完全分布式的环境下搭建Hadoop0.20.2,现在就再利用这个环境完成开发. 首先用hadoop这个用户登录linux系统(hadoop用户在前面一篇文章中创建的),然后 ...
- 获取hadoop的源码和通过eclipse关联hadoop的源码
一.获取hadoop的源码 首先通过官网下载hadoop-2.5.2-src.tar.gz的软件包,下载好之后解压发现出现了一些错误,无法解压缩, 因此有部分源码我们无法解压 ,因此在这里我讲述一下如 ...
- 【Hadoop测试程序】编写MapReduce测试Hadoop环境
我们使用之前搭建好的Hadoop环境,可参见: <[Hadoop环境搭建]Centos6.8搭建hadoop伪分布模式>http://www.cnblogs.com/ssslinppp/p ...
随机推荐
- Vue学习之路---No.2(分享心得,欢迎批评指正)
昨天我们大致了解了有关Vue的基础知识和语法:今天我们继续在大V这条路上前进. 首先,我们回忆一下昨天提到的相关知识点: 1.了解Vue的核心理念------"数据驱动视图" 2. ...
- 【杂】poj2482 Stars in Your Windows 题面的翻译
原地址:http://poj.org/problem?id=2482 神题,被誉为最浪漫的题目,一位acmer以自己独特的方式写下的殷殷情语 你窗前的星星 纵时光飞逝如梭,也我对你的回忆也永不黯然.从 ...
- 强大的健身软件——Keep
Keep是一款具有社交属性的健身工具类产品.用户可利用碎片化的时间,随时随地选择适合自己的视频健身课程,进行真人同步训练.完成后还可以"打卡"晒成就. 你可根据器械.部位.难度 ...
- SQL server 数据库——数学函数、字符串函数、转换函数、时间日期函数
数学函数.字符串函数.转换函数.时间日期函数 1.数学函数 ceiling()--取上限 select ceiling(oil) as 油耗上限 from car floor()--取下限 sele ...
- 1622: [Usaco2008 Open]Word Power 名字的能量
1622: [Usaco2008 Open]Word Power 名字的能量 Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 370 Solved: 18 ...
- solr 分词词库管理思路
solr 分词词库管理思路 大概有以下几种思路: 1. 自定义 SolrRequestHandler 由 SolrRequestHandler 来进行对分词器,进行A)词库加载B)动态添 ...
- UWP--数据绑定的几种方式
1.后台代码: 2.后台定义属性,前台XAML 中绑定: 3.XAML 中定义资源并应用(资源中自定义对象): 4.用元素值绑定:
- windows python flask上传文件出现IOError: [Errno 13] Permission denied: 'E:\\git\\test\\static\\uploads'的解决方法
在浏览器中输入时,出现IOError: [Errno 13] Permission denied: 'E:\\git\\test\\static\\uploads' http://127.0.0.1: ...
- nginx反向代理与负载均衡
一:nginx反向代理与负载均衡配置思路与用法 1.nginx反向代理:就是你去相亲时,媒婆就是这里的代理,让媒婆带你去见姑娘 2.nginx负载均衡:就是有很多的媒婆经过商量给你选出最适合你的姑娘, ...
- iwebshop两表联查
$tb_goods = new IQuery('goods as g'); $tb_goods->join='left join miao as m on m.goods_id=g.id'; $ ...