打造比Dictionary还要快2倍以上的字查找类
针对一个长度为n的数组。
[1,2,3,4,5,6,7,8,9]
最快的通用查找类是Dictionary其采用hashcode算法,复杂度为O(1).
而上大学时,最快的查找法为二分查找法,复杂度为O(log(n)).
因此我们得出结论,Dictionary的查找速度应该是最快的。
但是Dictionary里在查找之前必须执行GetHashCode()计算出hashCode.
因此查找效率就是计算hashCode的效率。
如果某种查找算法比计算hashCode的时间要短,也就能超越Dictionary的查找效率。
因此,我开始想办法打造这个查找函数。
//继承原生的查找类
public class FastDictionary<TValue>:Dictionary<string,TValue>{}
//自定义的查找类
public class FastSearch<TValue>{
}
首先两个字符串的对比一般情况下是
public bool compare(string strA,string strB)
{
for(int i=0;i<strA.Length;i++)
{
if(strA[i]!=strB[i])
{
return false;
}
}
return true;
}
以上的情况是对两个字符串中的每一个字符做对比,如果所有的字符都相同,则代表两个字符串相同。
很好理解。但其实还有更快的算法。
在C#中所有的字符串为utf-16格式,即两个字节代表一个字符。而一个long类型是8个字节。也就是说,一个long类型可以存储4个字符。
那么以上的对比函数可以这样写:
public bool Compare(string strA,string strB)
{
int length=;
int longLength=(length+)>>;
int remain=;
fixed(char* ptA=&strA) fixed(char* ptB=&strB)
{
for(int i=;i<longLength;i++)
{
if(i==longLength-)
{
remain=length&;
if(remain==)
{
if(*(long*)(ptA+i*)==*(long*)(ptB+i*))
{
return false;
}
}
else if(remain==)
{
if(*(short*)(ptA+i*)==*(short*)(ptB+i*))
{
return false;
}
}
else if(remain==)
{
if(*(int*)(ptA+i*)==*(int*)(ptB+i*))
{
return false;
}
}
else if(remain==)
{
if(*(long*)(ptA+i*-)==*(long*)(ptB+i*-))
{
return false;
}
}
}
if(*(long*)(ptA+i*)==*(long*)(ptB+i*))
{
return false;
}
}
return true;
}
}
当字符串中的字符为五个时。前四个字符串转为long类型。第五个字符串转为short类型,然后再转存为long类型
['a','b','c','d','e']
当字符串中的字符为六个时,前四个字符串转为long类型。第五,六个字符串转为int类型,然后再转存为long类型
['a','b','c','d','e','f']
当字符串中的字符为七个时,前四个字符串转为long类型。第四,五,六,七个字符转为long类型
['a','b','c','d','e','f','g']
当字符串中的字符为八个时,前四个字符串转为long类型。后四个字符转为long类型
['a','b','c','d','e','f','g','h']
也就是说,所有的字符串都能转为long数组。
long[] strLong=getLongArray("sdfasdfsfd");
然后再对long数组对行对比,那么效率也快多了。
再进一步,在Compare函数中,需要不断的判断length的长度,以及判断是否是最后一个字符。
其实在已经确定了字符串长度的时候,这些判断代码是不需要的。
因此,可以利用Emit生成对比函数缓存代理,然后再执行,这样的字符串对比效率应该是最快的。
当然最好是在64位操作系统下,这样处理long类型效率比32位系统快。
下面是生成字符串对比的函数的代理函数
public unsafe delegate bool CompareDelegate(char* keyChar, char* CompareKeyChar,int length);
public static CompareDelegate GetCompareDelegate(int length)
{
TypeBuilder typeBuilder = UnSafeHelper.GetDynamicType();
MethodBuilder dynamicMethod= typeBuilder.DefineMethod("Compare", MethodAttributes.Public
| MethodAttributes.Static | MethodAttributes.HideBySig, CallingConventions.Standard,
typeof(bool),new Type[]{ typeof(char*),typeof(char*),typeof(int) });
ILGenerator methodIL= dynamicMethod.GetILGenerator(); #region
var fourCount = methodIL.DeclareLocal(typeof(int));
//var position = methodIL.DeclareLocal(typeof(int));
var remain = methodIL.DeclareLocal(typeof(int)); int position = ;
var fourEnd = methodIL.DefineLabel();
var methodEnd = methodIL.DefineLabel();
while (position < (length & ~))
{ methodIL.Emit(OpCodes.Ldarg_0);
methodIL.Emit(OpCodes.Ldc_I4, position*);
methodIL.Emit(OpCodes.Add);
methodIL.Emit(OpCodes.Ldind_I8); methodIL.Emit(OpCodes.Ldarg_1);
methodIL.Emit(OpCodes.Ldc_I4, position * );
methodIL.Emit(OpCodes.Add);
methodIL.Emit(OpCodes.Ldind_I8); methodIL.Emit(OpCodes.Beq_S, fourEnd);
methodIL.Emit(OpCodes.Ldc_I4_0);//false
methodIL.Emit(OpCodes.Ret);
position += ;
}
methodIL.MarkLabel(fourEnd);
switch (length & )
{
case : {
methodIL.Emit(OpCodes.Ldarg_0);
methodIL.Emit(OpCodes.Ldc_I4, position*);
methodIL.Emit(OpCodes.Add);
methodIL.Emit(OpCodes.Ldind_I2); methodIL.Emit(OpCodes.Ldarg_1);
methodIL.Emit(OpCodes.Ldc_I4, position*);
methodIL.Emit(OpCodes.Add);
methodIL.Emit(OpCodes.Ldind_I2); methodIL.Emit(OpCodes.Beq_S, methodEnd);
methodIL.Emit(OpCodes.Ldc_I4_0);
methodIL.Emit(OpCodes.Ret);
} break;
case : {
methodIL.Emit(OpCodes.Ldarg_0);
methodIL.Emit(OpCodes.Ldc_I4, position * );
methodIL.Emit(OpCodes.Add);
methodIL.Emit(OpCodes.Ldind_I4); methodIL.Emit(OpCodes.Ldarg_1);
methodIL.Emit(OpCodes.Ldc_I4, position * );
methodIL.Emit(OpCodes.Add);
methodIL.Emit(OpCodes.Ldind_I4); methodIL.Emit(OpCodes.Beq_S, methodEnd);
methodIL.Emit(OpCodes.Ldc_I4_0);
methodIL.Emit(OpCodes.Ret);
} break;
case : {
position--;
methodIL.Emit(OpCodes.Ldarg_0);
methodIL.Emit(OpCodes.Ldc_I4, position * );
methodIL.Emit(OpCodes.Add);
methodIL.Emit(OpCodes.Ldind_I8); methodIL.Emit(OpCodes.Ldarg_1);
methodIL.Emit(OpCodes.Ldc_I4, position * );
methodIL.Emit(OpCodes.Add);
methodIL.Emit(OpCodes.Ldind_I8); methodIL.Emit(OpCodes.Beq_S, methodEnd);
methodIL.Emit(OpCodes.Ldc_I4_0);
methodIL.Emit(OpCodes.Ret);
} break;
}
#endregion
methodIL.MarkLabel(methodEnd);
methodIL.Emit(OpCodes.Ldc_I4_1);
methodIL.Emit(OpCodes.Ret);
Type t= typeBuilder.CreateType();
MethodInfo method= t.GetMethod("Compare"); Delegate delete = Delegate.CreateDelegate(typeof(CompareDelegate), method);
return (CompareDelegate)delete;
}
那么基于对以上函数的认识,有两个是需要明确的。
1.利用Emit可以省略掉一部分判断代码。
2.利用long类型可以一次判断4个字符,加快字符串的对比速度。
那么字符串的查找问题就能转换为long类型的查找问题。这时候很容易就能想到二分查找。
假如有以下字符串。
string[] keys={“aa”,"bb","ccc","dddd"};
从中查出"bb"字符串所在的索引。
先根据字符串中的字符转为byte整型
['a','a']=>[97,97,0,0]
['b','b']=>[98,98,0,0]
['c','c','c']=>[99,99,99,0]
['d','d','d','d']=>[100,100,100,100]
那么整体的二维数组为:
[097,097,000,000]
[098,098,000,000]
[099,099,099,000]
[100,100,100,100]
是不是很像高数中的矩阵?
那么这个二维数组共四行四列。
在第一列中有97,98,99,100四个值。
这四个值先进行排序。然后再选出中间值。利用二分法。进行代码生成。
即:if(str[0]<99){}else{}
或:if(str[0]>98{}else{}.
这样的话,就可以把以上四组分为两组。
即组A:
[097,097,000,000]
[098,098,000,000]
与组B:
[099,099,099,000]
[100,100,100,100]
在组A中。再利用二分法。
if(str[0]<98){
return 0;//数组下标
}else{
return 1;
}
在组B中。利用二分法.
if(str[0]<100){
return 2;
}else{
return 3;
}
这种近似的二分查找法,应该是查找速度非常快的。下面整理一下思路。
1.首先把数组转换为整数数组。
2.对二维数组中的第一列进行排序,找出中间值。
3.如果第一列中没有找到中间值,就查找第二列。直到找到最优的中间值为止。
4.根据最优中间值生成if...else...代码。并把二维数据分为二组。
5.再根据以上思路继续分组,直到不能分为止。
6.返回所在字符串的数组索引。
但是以上思路存在一个问题。如果字符串的长度不固定。其中长度较短的字符串需要用0补位。
也就是说在取值的时候需要判断字符串的长度。
也就是说,整体思路,应该是这样。
首先,把一组字符串中相同长度的字符串进行分组。
然后再利用以上的方法生成近似的二分查找函数。
那么相同长度的字符串分组需要一个函数进行查找。
分组数据为:
public class GroupData<TValue>
{
//字符串长度
public int length;
//优化的二分查找函数,长度固定
public FindDelegate findDelegate;
//优化过的字符串比较函数
public CompareDelegate compareDelegate;
public List<KV<TValue>> list;
}
其中List<KV<TValue>> list是存储字符串的列表。KV是一个存储key以及value的泛型体。key为string类型:
public struct KV<TValue>
{
public KV(string key, TValue value,int index)
{
this.key = key;
this.length = key.Length;
this.value = value;
this.index = index;
}
public string key;
public int length;
public int index;
public TValue value;
}
整体的搜索类如下:
public unsafe delegate int FindDelegate(char* keyChar);
public unsafe delegate bool CompareDelegate(char* keyChar, char* CompareKeyChar,int length);
public delegate int FindGroupIndexDelegate(int length); public class FastSearch<TValue> where TValue : class
{
GroupData<TValue>[] groupArray;
public FindGroupIndexDelegate findGroupIndexDelegate;
public unsafe FastSearch(Dictionary<string, TValue> originalDictionary)
{
GroupData<TValue> groupData;
int index = ;
SortedList<int, GroupData<TValue>> groupList = new SortedList<int, GroupData<TValue>>();
foreach (var kv in originalDictionary)
{
if (groupList.TryGetValue(kv.Key.Length, out groupData))
{
index = groupList.Count;
groupData.list.Add(new KV<TValue>(kv.Key, kv.Value, index));
}
else
{
groupData = new GroupData<TValue>();
//快速比较函数,应用long指针,一次比较4个字符
groupData.compareDelegate = CompareDelegateHelper.GetCompareDelegate(kv.Key.Length);
groupData.length = kv.Key.Length;
groupData.list = new List<KV<TValue>>();
groupData.list.Add(new KV<TValue>(kv.Key, kv.Value, index));
groupList.Add(kv.Key.Length, groupData);
}
}
groupArray = groupList.Values.ToArray();
groupList.Clear();
//二分查长相同长度的字符串组下标
findGroupIndexDelegate = FindGroupIndexDelegateHelper.GetFindGroupIndexDelegate(groupArray);
for (int i = ; i < groupArray.Length; i++)
{
//生成在长度相同的字符串中快速查找的函数
groupArray[i].findDelegate = FastFindSameLengthStringHelper.GetFastFindSameLengthStringDelegate(groupArray[i].list, groupArray[i].length);
}
//originalDictionary.Clear();
}
public unsafe bool TryGetValue(string key, int length,out TValue value)
{
GroupData<TValue> group = groupArray[findGroupIndexDelegate(length)];
int index;
fixed (char* keyChar = key)
{
index = group.findDelegate(keyChar);
value = group.list[index].value;
string comparekey = group.list[index].key;
fixed (char* complareKeyChar = comparekey)
{
return group.compareDelegate(keyChar, complareKeyChar, length);
}
}
}
}
最前面三个是代理
public unsafe delegate int FindDelegate(char* keyChar);
public unsafe delegate bool CompareDelegate(char* keyChar, char* CompareKeyChar,int length);
public delegate int FindGroupIndexDelegate(int length);
FindDelegate是查找函数。参数为字符串指针。返回为相同长度字符串列表中的字符串下标。
CompareDelegate是字符串比较函数。参数为两字符串指针,以及两字符串长度。
FindGroupIndexDelegate是查找分组的代理函数。
以上三个代理会在FastSearch初始化的时候初始化。而在查找的时候直接调用。
其中CompareDelegate的Emit代码前面已经给出。
FindDelegate的Emit代码为:
public class FindGroupIndexDelegateHelper
{
public static FindGroupIndexDelegate GetFindGroupIndexDelegate<TValue>(GroupData<TValue>[] groupDataArray)
{
TypeBuilder typeBuilder = UnSafeHelper.GetDynamicType();
MethodBuilder dynamicMethod = typeBuilder.DefineMethod("FindGroupIndexDelegate", MethodAttributes.Public
| MethodAttributes.Static | MethodAttributes.HideBySig, CallingConventions.Standard,
typeof(int), new Type[] { typeof(int) });
var methodIL = dynamicMethod.GetILGenerator();
GenerateFindGroupIndexDelegate(methodIL, groupDataArray, , groupDataArray.Length - );
Type t = typeBuilder.CreateType();
MethodInfo method = t.GetMethod("FindGroupIndexDelegate");
return (FindGroupIndexDelegate)Delegate.CreateDelegate(typeof(FindGroupIndexDelegate), method);
}
public static void GenerateFindGroupIndexDelegate<TValue>(ILGenerator methodIL,GroupData<TValue>[] groupDataArray, int left, int right)
{
int middle = (right + left + ) >> ;
int lessThanValue = groupDataArray[middle].length;
var elseStatement = methodIL.DefineLabel();
methodIL.Emit(OpCodes.Ldarg_0);
methodIL.Emit(OpCodes.Ldc_I4,lessThanValue);
methodIL.Emit(OpCodes.Bge_S, elseStatement);
//if
if (middle == left + )
{
methodIL.Emit(OpCodes.Ldc_I4, left);
methodIL.Emit(OpCodes.Ret);
}
else
{
GenerateFindGroupIndexDelegate(methodIL, groupDataArray, left, middle - );
}
//else
methodIL.MarkLabel(elseStatement);
if (middle == right)
{
methodIL.Emit(OpCodes.Ldc_I4, right);
methodIL.Emit(OpCodes.Ret);
}
else
{
GenerateFindGroupIndexDelegate(methodIL,groupDataArray,middle,right);
}
}
}
FindGroupIndexDelegate的Emit代码为:
public class FastFindSameLengthStringHelper
{
public class Node
{
/// <summary>
/// 对比的数字
/// </summary>
public long compareValue;
/// <summary>
/// if 语句节点
/// </summary>
public Node ifCase;
/// <summary>
/// else语句节点
/// </summary>
public Node elseCase;
/// <summary>
/// 节点的类型
/// </summary>
public NodeType nodeType;
/// <summary>
/// 对比的列数
/// </summary>
public int charIndex;
/// <summary>
/// 当只有一个元素时,返回该元素的索引
/// </summary>
public int arrayIndex;
}
public enum NodeType
{
CompareCreaterThan,
CompareLessThan,
SetIndex
}
public struct ColumnCompareData
{
public int[] ColumnSort;
public bool hasMidValue;
public long midValue;
public int midValueIndex;
public int midIndex;
public LongCompare compare;
public int[] ColumnBig;
public int[] ColumnSmall;
public int midDistance;
}
public enum LongCompare
{
LessThan,
CreaterThan
}
public unsafe static FindDelegate GetFastFindSameLengthStringDelegate<TValue>(List<KV<TValue>> list, int length)
{
int rowCount = list.Count;
int columnLength = (length + ) >> ;
long[][] KeyLongArray = new long[rowCount][];
for (int row = ; row < rowCount; row++)
{
fixed (char* pKey = list[row].key)
{
KeyLongArray[row] = new long[columnLength];
for (int col = ; col < columnLength; col++)
{
if (col == columnLength - )
{
int remain = length & ;
if (remain == )
{
KeyLongArray[row][col] = *(long*)(pKey + col * );
}
else if (remain == )
{
KeyLongArray[row][col] = *(short*)(pKey + col * );
}
else if (remain == )
{
KeyLongArray[row][col] = *(int*)(pKey + col * );
}
else if (remain == )
{
KeyLongArray[row][col] = *(long*)(pKey + col * - );
}
}
else
{
KeyLongArray[row][col] = *(long*)(pKey + col * );
}
}
}
}
// 列排序索引,用于对Long二维数组列进行排序
int[][] ColumnSortArray = new int[columnLength][];
//初始化列索引数组
for (int column = ; column < columnLength; column++)
{
ColumnSortArray[column] = new int[rowCount];
for (int row = ; row < rowCount; row++)
{
ColumnSortArray[column][row] = row;
}
}
Node rootNode = new Node();
Init(KeyLongArray,KeyLongArray,columnLength, ColumnSortArray, ref rootNode);
ILWriter iLWriter = new ILWriter();
return iLWriter.Generate(rootNode, length, columnLength);
}
public static void Init(long[][] FullKeyLongArray, long[][] KeyLongArray,int columnLength, int[][] ColumnSortArray, ref Node codeNode)
{
if (KeyLongArray == null) return;
if (FullKeyLongArray.Length == )
{
codeNode.nodeType = NodeType.SetIndex;
codeNode.arrayIndex = ;
return;
}
// KeyValue数组长度
int arrayLength = KeyLongArray.Length;
//是否为奇数数组
bool isEvenArray = (arrayLength & ) == ;
//找到的最好中分的那个列
int BestColumnCompareDataIndex = ;
//数组为奇数长度时,最中间的索引值
int midIndex = ;
//数组为偶数长度时,中间左右两边的值
int midLeftIndex, midRightIndex = ;
//距中间值的距离
int midDistance = ;
//距中间值的最长距离
int midDistanceLength = ;
//是否具有中间值,如果一个列中所有元素均相同,则无中间值
bool hasMidValue = false;
//是否找到了直接二分值
bool hasFindBestColumnCompareDataIndex = false;
//数组中每列比较的结果
ColumnCompareData[] columnCompareData = new ColumnCompareData[columnLength]; ;
//一列一列的解析出比较结果,如二分值,索引等
for (int column = ; column < columnLength; column++)
{
//对列索引数组进行排序
Array.Sort<int>(ColumnSortArray[column], new KeyLongArrayCompare(FullKeyLongArray, column));
//是否有二分值
hasMidValue = false;
//如果数组长度为偶数
if (isEvenArray)
{
//中间距两边的距离
midDistanceLength = arrayLength >> ;
//中间靠左边的索引值
midLeftIndex = (arrayLength >> ) - ;
//中间靠右边的索引值
midRightIndex = midLeftIndex + ;
//找到与中间值值不同的行,并记录下来。
long LeftValue = GetKeyLong(FullKeyLongArray, ColumnSortArray[column][midLeftIndex], column);
long RightValue = GetKeyLong(FullKeyLongArray, ColumnSortArray[column][midRightIndex], column);
//[1][2][3][4]
//[1][Left]|[Right][4]
if (LeftValue != RightValue)
{
BestColumnCompareDataIndex = column;
hasFindBestColumnCompareDataIndex = true;
hasMidValue = true;
columnCompareData[column].hasMidValue = hasMidValue;
columnCompareData[column].midValue = RightValue;
columnCompareData[column].midValueIndex = ColumnSortArray[column][midRightIndex];
columnCompareData[column].compare = LongCompare.LessThan;
columnCompareData[column].midIndex = midRightIndex;
columnCompareData[column].midDistance = ;
break;
}
else
{
//[1][2][3][4]
for (midDistance = ; midDistance < midDistanceLength; midDistance++)
{
//[1]|[Left][3][4],2
if (LeftValue != GetKeyLong(FullKeyLongArray, ColumnSortArray[column][midLeftIndex - midDistance], column))
{
hasMidValue = true;
columnCompareData[column].hasMidValue = hasMidValue;
columnCompareData[column].midValue = LeftValue;
columnCompareData[column].midValueIndex = ColumnSortArray[column][midLeftIndex];
columnCompareData[column].compare = LongCompare.LessThan;
columnCompareData[column].midIndex = midLeftIndex;
columnCompareData[column].midDistance = midDistance;
}
//[1][2][Right]|[4]
if (RightValue != GetKeyLong(FullKeyLongArray, ColumnSortArray[column][midRightIndex + midDistance], column))
{
hasMidValue = true;
columnCompareData[column].hasMidValue = hasMidValue;
columnCompareData[column].midValue = RightValue;
columnCompareData[column].midValueIndex = ColumnSortArray[column][midRightIndex];
columnCompareData[column].compare = LongCompare.CreaterThan;
columnCompareData[column].midIndex = midRightIndex;
columnCompareData[column].midDistance = midDistance;
}
}
}
}
//如果数组长度为奇数
else
{
//中间到两边的距离
midDistanceLength = arrayLength >> ;
//中间值的索引
midIndex = (arrayLength >> );
//找出与中间值不同的行
//[1][2][mid][3][4]
long midValue = GetKeyLong(FullKeyLongArray, ColumnSortArray[column][midIndex], column);
for (midDistance = ; midDistance < midDistanceLength; midDistance++)
{
//[1][2]|[mid][3][4]
if (midValue != GetKeyLong(FullKeyLongArray, ColumnSortArray[column][midIndex - midDistance - ], column))
{
hasMidValue = true;
columnCompareData[column].hasMidValue = hasMidValue;
columnCompareData[column].midValue = midValue;
columnCompareData[column].midValueIndex = ColumnSortArray[column][midIndex - midDistance - ];
columnCompareData[column].compare = LongCompare.LessThan;
columnCompareData[column].midIndex = midIndex;
columnCompareData[column].midDistance = midDistance;
if (midDistance == )
{
BestColumnCompareDataIndex = column;
hasFindBestColumnCompareDataIndex = true;
break;
}
}
//[1][2][mid]|[3][4]
if (midValue != GetKeyLong(FullKeyLongArray, ColumnSortArray[column][midIndex + midDistance + ], column))
{
hasMidValue = true;
columnCompareData[column].hasMidValue = hasMidValue;
columnCompareData[column].midValue = midValue;
columnCompareData[column].compare = LongCompare.CreaterThan;
columnCompareData[column].midValueIndex = ColumnSortArray[column][midIndex + midDistance + ];
columnCompareData[column].midIndex = midIndex;
columnCompareData[column].midDistance = midDistance;
if (midDistance == )
{
BestColumnCompareDataIndex = column;
hasFindBestColumnCompareDataIndex = true;
break;
}
}
}
}
}
//如果没有直接找到了二分索引
if (!hasFindBestColumnCompareDataIndex)
{
//距离中间最小的距离
int minMidDistance = midDistanceLength;
//找到最合适的二分索引,即距两边距离最短的
for (int column = ; column < columnLength; column++)
{
if (columnCompareData[column].midDistance < minMidDistance)
{
minMidDistance = columnCompareData[column].midDistance;
BestColumnCompareDataIndex = column;
}
}
}
//两个数组Big和Small
long[][] KeyLongArrayBig = null;
long[][] KeyLongArraySmall = null;
int[][] ColumnSortArrayBig = null;
int[][] ColumnSortArraySmall = null;
int KeyLongArrayBigLength = ;
int KeyLongArraySmallLength = ;
//[1][2][midValue]|[3][4]
if (columnCompareData[BestColumnCompareDataIndex].compare == LongCompare.CreaterThan)
{
KeyLongArraySmallLength = columnCompareData[BestColumnCompareDataIndex].midIndex + ;
if (KeyLongArraySmallLength > )
{
KeyLongArraySmall = new long[KeyLongArraySmallLength][];
//初始化排序数组
ColumnSortArraySmall = new int[columnLength][];
for (int column = ; column < columnLength; column++)
{
ColumnSortArraySmall[column] = new int[KeyLongArraySmallLength];
}
}
KeyLongArrayBigLength = arrayLength - columnCompareData[BestColumnCompareDataIndex].midIndex - ;
if (KeyLongArrayBigLength > )
{
KeyLongArrayBig = new long[KeyLongArrayBigLength][];
ColumnSortArrayBig = new int[columnLength][];
for (int column = ; column < columnLength; column++)
{
ColumnSortArrayBig[column] = new int[KeyLongArrayBigLength];
}
}
int smallIndex = ;
int bigIndex = ;
for (int row = ; row < arrayLength; row++)
{
if (row > columnCompareData[BestColumnCompareDataIndex].midIndex)
{
KeyLongArrayBig[bigIndex] = FullKeyLongArray[ColumnSortArray[BestColumnCompareDataIndex][row]];
for (int column = ; column < columnLength; column++)
{
ColumnSortArrayBig[column][bigIndex] = ColumnSortArray[BestColumnCompareDataIndex][row];
}
bigIndex++;
}
else
{
KeyLongArraySmall[smallIndex] = FullKeyLongArray[ColumnSortArray[BestColumnCompareDataIndex][row]];
for (int column = ; column < columnLength; column++)
{
ColumnSortArraySmall[column][smallIndex] = ColumnSortArray[BestColumnCompareDataIndex][row];
}
smallIndex++;
}
}
}
//[1][2]|[midValue][3][4]
else if (columnCompareData[BestColumnCompareDataIndex].compare == LongCompare.LessThan)
{
KeyLongArraySmallLength = columnCompareData[BestColumnCompareDataIndex].midIndex;
if (KeyLongArraySmallLength > )
{
KeyLongArraySmall = new long[KeyLongArraySmallLength][];
ColumnSortArraySmall = new int[columnLength][];
for (int column = ; column < columnLength; column++)
{
ColumnSortArraySmall[column] = new int[KeyLongArraySmallLength];
}
}
KeyLongArrayBigLength = arrayLength - columnCompareData[BestColumnCompareDataIndex].midIndex;
if (KeyLongArrayBigLength > )
{
KeyLongArrayBig = new long[KeyLongArrayBigLength][];
ColumnSortArrayBig = new int[columnLength][];
for (int column = ; column < columnLength; column++)
{
ColumnSortArrayBig[column] = new int[KeyLongArrayBigLength];
}
}
int smallIndex = ;
int bigIndex = ;
for (int row = ; row < arrayLength; row++)
{
if (row < columnCompareData[BestColumnCompareDataIndex].midIndex)
{
KeyLongArraySmall[smallIndex] = FullKeyLongArray[ColumnSortArray[BestColumnCompareDataIndex][row]];
for (int column = ; column < columnLength; column++)
{
ColumnSortArraySmall[column][smallIndex] = ColumnSortArray[BestColumnCompareDataIndex][row];
}
smallIndex++;
}
else
{
KeyLongArrayBig[bigIndex] = FullKeyLongArray[ColumnSortArray[BestColumnCompareDataIndex][row]];
for (int column = ; column < columnLength; column++)
{
ColumnSortArrayBig[column][bigIndex] = ColumnSortArray[BestColumnCompareDataIndex][row];
}
bigIndex++;
}
}
}
//解析最终结果到CodeNode节点中,用于生成代码用
if (columnCompareData[BestColumnCompareDataIndex].compare == LongCompare.CreaterThan)
{
codeNode.nodeType = NodeType.CompareCreaterThan;
codeNode.compareValue = columnCompareData[BestColumnCompareDataIndex].midValue;
}
if(columnCompareData[BestColumnCompareDataIndex].compare==LongCompare.LessThan)
{
codeNode.nodeType = NodeType.CompareLessThan;
codeNode.compareValue = columnCompareData[BestColumnCompareDataIndex].midValue;
}
//codeNode.ifCase = new Node();
//codeNode.elseCase = new Node();
codeNode.charIndex = BestColumnCompareDataIndex << ;
//[1][2][mid]|[4] if(x>mid){ i=3}else{i=4}
//[1][2][mid]|[4][5]
if (codeNode.nodeType == NodeType.CompareCreaterThan)
{
if (KeyLongArrayBigLength == )
{
codeNode.ifCase = null;
}
else
{
codeNode = new Node();
}
if (KeyLongArrayBigLength == )
{
codeNode.ifCase.nodeType = NodeType.SetIndex;
codeNode.ifCase.arrayIndex = ColumnSortArray[BestColumnCompareDataIndex][columnCompareData[BestColumnCompareDataIndex].midIndex + ];
codeNode.ifCase.charIndex = codeNode.charIndex;
}
else
{
Init(FullKeyLongArray, KeyLongArrayBig,columnLength, ColumnSortArrayBig, ref codeNode.ifCase);
}
if (KeyLongArraySmallLength == )
{
codeNode.elseCase = null;
}
else
{
codeNode.elseCase = new Node();
}
if (KeyLongArraySmallLength == )
{
codeNode.elseCase.nodeType = NodeType.SetIndex;
codeNode.elseCase.arrayIndex = ColumnSortArray[BestColumnCompareDataIndex][columnCompareData[BestColumnCompareDataIndex].midIndex];
codeNode.elseCase.charIndex = codeNode.charIndex; }
else
{
Init(FullKeyLongArray, KeyLongArraySmall,columnLength, ColumnSortArraySmall, ref codeNode.elseCase);
}
}
//[1][2]|[mid][4][5] if(x<mid){}else{}
else if (codeNode.nodeType == NodeType.CompareLessThan)
{
if (KeyLongArraySmallLength == )
{
codeNode.ifCase = null;
}
else
{
codeNode.ifCase = new Node();
}
if (KeyLongArraySmallLength == )
{
codeNode.ifCase.nodeType = NodeType.SetIndex;
codeNode.ifCase.arrayIndex = ColumnSortArray[BestColumnCompareDataIndex][columnCompareData[BestColumnCompareDataIndex].midIndex - ];
codeNode.ifCase.charIndex = codeNode.charIndex;
}
else
{
Init(FullKeyLongArray, KeyLongArraySmall,columnLength, ColumnSortArraySmall, ref codeNode.ifCase);
}
if (KeyLongArrayBigLength == )
{
codeNode.elseCase = null;
}
else
{
codeNode.elseCase = new Node();
}
if (KeyLongArrayBigLength == )
{
codeNode.elseCase.nodeType = NodeType.SetIndex;
codeNode.elseCase.arrayIndex = ColumnSortArray[BestColumnCompareDataIndex][columnCompareData[BestColumnCompareDataIndex].midIndex];
codeNode.elseCase.charIndex = codeNode.charIndex;
}
else
{
Init(FullKeyLongArray, KeyLongArrayBig,columnLength, ColumnSortArrayBig, ref codeNode.elseCase);
}
}
}
public static long GetKeyLong(long[][] KeyLongArray, int RowIndex, int ColumnIndex)
{
if (ColumnIndex < KeyLongArray[RowIndex].Length)
{
return KeyLongArray[RowIndex][ColumnIndex];
}
else
{
return ;
}
}
}
其运行效率如下:
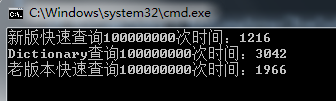
查询效率基本是传统字典的2倍以上。而且数量越多。字符串越长,其查询效率越高。
打造比Dictionary还要快2倍以上的字查找类的更多相关文章
- 分享Pos函数(比FastPos还要快)
): Integer; ): Integer; 主要用途是搜索字符串中第n个Substr. 经过测试,这2个函数的速度比直接用Pos+Copy快好几倍(如果字符串够长,可能10几倍) 比Pos+Del ...
- 16位图像Alpha混合的实现(用汇编写的,比MMX还要快)
Alpha 混合的算法很简单,基于下面的公式就可以实现: D := A * (S - D) / 255 + D D 是目标图像的像素, S 是源图像的像素 A 是 Alpha 值, 0 为全透明, 2 ...
- 树莓派安装OSMC打造家庭影院,还可以看优酷和CCTV
1.OSMC是什么? OSMC是树莓派官方推荐的影音系统,是一款开源的操作系统,是Openelec的升级版,同样是基于Kodi的开源项目.OSMC,使用它可以将树莓派打造成一款全功能的家庭影院系统,它 ...
- 比JSONKit还要快的第三方JSON解析器NextiveJson
这款比JSONKit还好用,效率跟iOS5原生的差不多,不过解析后对内存的释放比原生的要多.所以推荐 https://github.com/nextive/NextiveJson 顺便提一下解析XML ...
- php 自定义求数组差集,效率比自带的array_diff函数还要快(转)
<?phpfunction array_different($array_1, $array_2) { $array_2 = array_flip($array_2); //将数组键值调换 fo ...
- 还能这么玩?用VsCode画类图、流程图、时序图、状态图...不要太爽!
文章每周持续更新,各位的「三连」是对我最大的肯定.可以微信搜索公众号「 后端技术学堂 」第一时间阅读(一般比博客早更新一到两篇) 软件设计中,有好几种图需要画,比如流程图.类图.组件图等,我知道大部分 ...
- UML类图还不懂?来看看这版乡村爱情类图,一把学会!
作者:小傅哥 博客:https://bugstack.cn 沉淀.分享.成长,让自己和他人都能有所收获! 一.码场心得
- Nodejs 模块查找机制还不错(从当前目录开始逐级向上查找node_modules)
比如 m.js是能够调用a.js的, 这样子目录就可以避免重复安装node_modules. 够用了.
- 在 CSS 预编译器之后:PostCSS
提到css预编译器(css preprocessor),你可能想到Sass.Less以及Stylus.而本文要介绍的PostCSS,正是一个这样的工具:css预编译器可以做到的事,它同样可以做到. “ ...
随机推荐
- Jsp注册界面——request对象
1. Reg.jsp <%@ page language="java" contentType="text/html; charset=UTF-8" pa ...
- call by value or reference ?
Java中参数传递是传值还是传引用呢?很多人遇到这个问题都会马上给你抛出这个例子: class Entry{ Integer value; public Entry(Integer v){ this. ...
- Java工程师:四个月小白变大咖,你能做到吗?
你眼中的Java工程师是什么样子? 技术大牛?闷骚男?IT民工?没有女朋友?全是汉子?很邋遢?贼眉鼠眼? 今天,中软国际卓越工程师,Java精英班正式开课啦.你想看看他们都是一群怎样的人吗? 今天的武 ...
- 9 个用于移动APP开发的顶级 JavaScript 框架
顶级 Java 框架 对于Web开发而言,Java是一个有前途的编程语言,并且在不久的将来它将依然在这个领域大放光彩.Java在移动app开发上也有同样的影响吗?让我们一起来看看ValueCoders ...
- request.RequestContextListener
由于是使用spring mvc来做项目,因此脱离了HttpServletRequest作为参数,不能够直接使用request,要想使用request可以使用下面的方法: 在web点xml中配置一个监听 ...
- UI设计学习路线图
文章转载自「开发者圆桌」一个关于开发者入门.进阶.踩坑的微信公众号 这里整理的UI设计学习路线图包含初中高三个部分,你可以通过百度云盘下载观看对应的视频 链接: http://pan.baidu.co ...
- Java面试10|数据库相关
1.ID分配单点问题 系统使用一张表的自增来得到订单号,所有的订单生成必须先在这里insert一条数据,得到订单号.分库后,库的数量变多,相应的故障次数变多,但由于单点的存在,故障影响范围并未相应的减 ...
- Python 之 json 模块
引言 对于做web开发的人来说,json文本必须要熟知与熟练使用的.大部分网站的API接口调用返回的数据,就是json格式的.如果看json对象所包含的内容,相信对熟悉Python的人开说,很快就能把 ...
- Hibernate二级缓存原理
缓存:缓存是什么,解决什么问题? 位于速度相差较大的两种硬件/软件之间的,用于协调两者数据传输速度差异的结构,均可称之为缓存Cache.缓存目的:让数据更接近于应用程序,协调速度不匹配,使访问速度更快 ...
- virtualBox,webstorm,开虚拟机传代码
一起git一个新技能 利用virtualBOX在本地开一个虚拟机,然后设置webstorm连接到虚拟机,将代码传到虚拟机里. 以下详细讲解: 第一步: 第二步:管理虚拟机的设置(我是用的是Xshell ...