Python基础2 编码和逻辑运算符
字符编码
为什么要编码
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理
AscII码 :标准ASCII码是采用7位二进制码来编码的,最高为0,没有0000 0000,所以就是2**7-1=127个字符 , 当用1个字节(8位二进制码)来表示ASCII码时,就在最高位添加1个0。1个字节表示一个英文字母。扩充的ASCII码最高位为1,相应的十进制为1~255。
一个英文字母占一个字节
8位(bit)==一个字节(byte)
1024byte=1KB
1024kb==1MB
1024MB=1GB
1024GB==1TB
Unicode:当时为了解决ASCII全球化的问题,就出现了Unicode,Unicode规定一个中文用4个字节表示,一个英文用2个字节表示。python3用四个字节来表示一个字符包含英语字母和汉字。
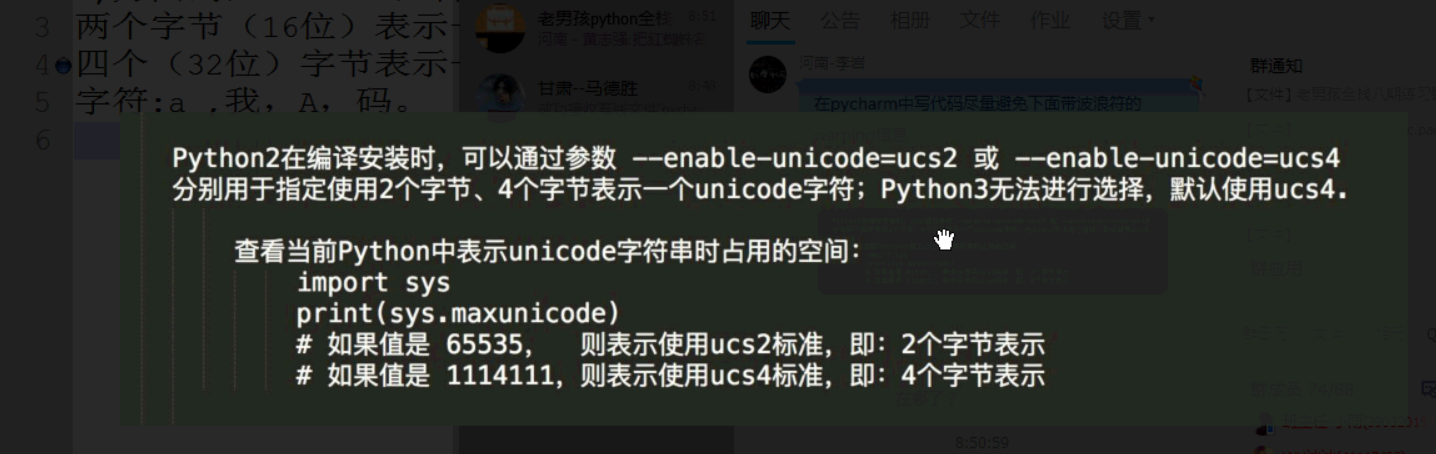
utf-8:其实就是Unicode的升级版,规定英文用1个字节表示,汉字用3个字节表示。
GBK:英文占用一个字节,汉字占用两个字节。
字符编码重点
关于字符编码困扰我好久了,今天我终于弄明白了,
编码(encode):将unicode编码的str转化为其他编码bytes类型的过程
解码:将其他编码的bytes类型转换为unicode编码的str字符串的过程
你要把gbk编码的字符串转换为utf的字符串必须这么办?
s = "你好"
print(s.encode("gbk").decode("gbk").encode("utf-8"))
结果:
b'\xe4\xbd\xa0\xe5\xa5\xbd'
问题一为什么要字符编码?
因为机器语言只能识别01010101,所以你编写的任何东西最后都要转化为bytes的类型。才能够让机器识别运行,bytes和二进制编码可以直接转换
Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分
文本在内存中是用Unicode编码方式编码而存储的.其表现形式是str类型,这里很重要,你在解释器中看到的所有的变量函数等都是unicode在解释器中的表现形式,它在内存中就是unicode的字节码
import json
s='中国'
t=json.dumps(s)
print(t)
结果:
#在内存中就是以这种格式存在的
"\u4e2d\u56fd" #\u+16进制
文本在硬盘中和网络传输中是以(utf-8(python3默认),gbk,gb2312)编码方式编码成字节串而保存在硬盘中或网络传输的.这是因为这几种方式编码占用内存小.
s='中国'
t=s.encode()#默认utf-8
print(t)
结果:
b'\xe4\xb8\xad\xe5\x9b\xbd'
字符编码的补充版本:
新添加一个数据类型:
bytes 类型其表现形式为 s= b"alex" 内部储存是以(UTF-8,GBK,GB2312)编码方式编码的,Bytes 对象是由单个字节作为基本元素(8位,取值范围 0-255)组成的序列,为不可变对象。
str类型 其表现形式为s="alex" 内部存储是以Unicode编码方式编码的。
汉字如果在python2中显示要注释#-*-coding:utf-8-*-,python 2 中默认编码方式为ASCII,python3中默认为utf-8
encode: 方法以 encoding 指定的编码格式编码字符串(用unicode编码)。把字符串编码成bytes类型(utf-8),编码其实就是加密的意思 返回bytes
decode: 以encdoing指定的编码格式解码,解码为对应的字符串
内存中字符串是以Unicode的编码方式,占用内存大,但是可以兼容更多的编码方式
硬盘中字符串是以utf-8的编码方式编码的,
关于字符编码我又想了很长时间,得到了一些新的体会,继续补充说明。
a='你好'
a_b=a.encode('utf-8')
print(a_b) #得到a的二进制形式
for i in a_b: #这步的主要作用是把16进制转换为十进制
print(i)
for i in a_b:
print(bin(i)) #这步主要的作用是把十进制转化为二进制
结果:
b'\xe4\xbd\xa0\xe5\xa5\xbd' #这里a的二进制数据类是用十六进制数字表示的,因为这样看起来比较清晰,其中\xe4代表1个字节,a总共有6个字节,这也印证了在uft-8中每个汉字用3个字节表示
228 #原来十六进制中的xe4就是十进制中的228
189
160
229
165
189
0b11100100 #这就是为什么a的二进制数据类型不用二进制表示的原因,这样太乱了,完全懵逼
0b10111101
0b10100000
0b11100101
0b10100101
0b10111101
bin(number):一个整数转换为一个二进制字符串。注意这个二进制是str类型的并不是bytes类型。
范例:
b=bin(100)
print(b,type(b))
结果:
0b1100100 <class 'str'>
范例
s="你好"
b=bytes(s,encoding="gbk")
print(b)
print(s.encode("utf-8")) #告诉python解释器你要把这个字符串汉字以什么方式编码,如果你要以utf-8我就3个字节(24位二进制)来表示每个汉字,如果你是要以GBK方式编码来编码字符,我就用2个字节(16位二进制来表示每个汉字)
结果:
b'\xc4\xe3\xba\xc3' #印证了GBK2个字节表示一个汉字
b'\xe4\xbd\xa0\xe5\xa5\xbd'
bytes():将字符串str类型转换成bytes类型,和字符串中的encode一样。
范例
s="你好"
b=bytes(s,encoding="gbk")
print(b)
print(s.encode("utf-8"))
结果:
b'\xc4\xe3\xba\xc3'
b'\xe4\xbd\xa0\xe5\xa5\xbd'
python2和python3编码区别
总结一下:
在python3中 文件默认编码方式是utf-8,字符串默认编码方式是unicode,以utf-8和gbk编码的代码加载到内存中会自动转化为unicode编码,window默认编码方式是gbk,unicode可以和gbk之间互相转化,这就是为什么你可以在显示屏中看到正常的字符了
在python 2中文件的默认编码方式是ascii,字符串默认编码方式也是ascii,但是ascii和unicode编码并不能互相转化,所以我们在文件头声明了utf-8,文件默认编码也会变成utf-8,这样中文也就能够在window的显示瓶中显示了.
默认编码改成unicode的话是不现实的, 因为很多软件就是基于之前的默认编码ASCII开发的,编码一换,那些软件的编码就都乱了。所以Python 2
就直接 搞了一个新的字符类型,就叫unicode类型,比如你想让你的中文在全球所有电脑上正常显示,在内存里就得把字符串存成unicode类型。

>>> s = "路飞"
>>> s
'\xe8\xb7\xaf\xe9\xa3\x9e'
>>> s2 = s.decode("utf-8")
>>> s2
u'\u8def\u98de'
>>> type(s2)
<type 'unicode'>
比较运算符和逻辑运算符
比较运算符的级别比逻辑运算符高。
逻辑运算符有not,or, and.
这几个逻辑运算符的运算优先级为:()>not>and>or
同等优先级从左到右开始运算
print(7>4==4) #the same as 7>4 and 4==4
True #其实这个表达式有多个隐形的式子组成。
例如:
A=(1 > 2 and 3 < 4 or 4 > 5 and 2 > 1 or 9 < 8)
print(a)
结果:
False
int与bool之间的转换:除了0,都是True
A=int(True)
B=int(False) print(a,b)
结果:
1,0
print(bool(1))
print(bool(3))
print(bool(0))
结果:
True
True
False
bool和str之间的转换:bool()非空字符都是true,空格也是True,空字符为False
例子
s="sdfa"
s1="a"
s2=""
s3=" "
结果:
s True
s1 True
s2 False
s3 True
例子:
print(str(2>1))
结果:
True
例子:
name=""
if name:
print("输入正确")
else:
print("请输入内容")
结果:
请输入内容
此题关键空字符串就是false,接着就运行到了else。注意“”表示的是空字符串,而不是空格。空格就是True。
面试题:
1. print( x or y) ,如果bool(x)为True,则结果为x。否则结果为Y。
例题:
print(3 or 5)
print(0 or 8)
print(-1or 0)
结果为:
3
8
-1
2. print(X and y),如果bool(x)为True,则结果为y,如果bool(x)为False,则结果为X。
例子:
print(3 and 5)
print(0 and 8)
print(-1 and 0)
结果为:
5
0
0
例子:
print(3 or 4 or 0 and 1 or 2)
结果为:
3
in 和 not in 的运用:
例子
sl="abcdefg"
print("a"in sl)
print("ad" in sl) #"ad" 作为一个整体相当于一个元素,而不是像这样"a""b"拆开。
结果:
True
False
题目要求:评论的内容不能有敏感词如“习大大”,“国民党”,“蒋介石”
答案:
comment=input("请输入评论")
if ("习大大"in comment )or ("国民党" in comment )or ("蒋介石"in comment):
print("评论中包含敏感词")
else:
print("评论成功")
稍微高级的解法:
list_1=["习大大","蒋介石","国民党"]
conment=input("请输入内容")
for i in list_1:
if i in conment:
print("涉及非法字符")
break
else:
print(conment) #不知道是不是新方法:for else 方法
注意:此题的关键在于敏感词要in 评论而不是commet in 敏感词。
Python基础2 编码和逻辑运算符的更多相关文章
- python基础之编码问题
python基础之编码问题 本节内容 字符串编码问题由来 字符串编码解决方案 1.字符串编码问题由来 由于字符串编码是从ascii--->unicode--->utf-8(utf-16和u ...
- Python基础-字符编码与转码
***了解计算机的底层原理*** Python全栈开发之Python基础-字符编码与转码 需知: 1.在python2默认编码是ASCII, python3里默认是utf-8 2.unicode 分为 ...
- 第三篇:python基础之编码问题
python基础之编码问题 python基础之编码问题 本节内容 字符串编码问题由来 字符串编码解决方案 1.字符串编码问题由来 由于字符串编码是从ascii--->unicode---&g ...
- 【Python】python基础语法 编码
编码 默认情况下,python以UTF-8编码,所有的字符串都是Unicode字符串,可以为代码定义不同的的编码. #coding:UTF-8 #OR #-*- coding:UTF-8 -*- p ...
- Python基础(字符编码与文件处理)
一.了解字符编码的知识储备 1.计算机基础知识(三副图) 2.文本编辑器存取文件的原理(notepad++,Pycharm,word) 打开编辑器就启动了一个进程,是在内存中运行的,所以在编辑器写的内 ...
- python基础(三)编码,深浅copy
编码,深浅copy encode,decode在python2中使用的一些迷糊,python3中更容易理解 要理解encode和decode,首先我们要明白编码,字符和二进制的相关概念,简单来说,计算 ...
- python基础-----字符编码
1.ASCII ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现 ...
- python基础之 编码进阶,文件操作和深浅copy
1.编码的进阶 字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码.即先将其他编码的字符串解码(decode)成unicode,再从unic ...
- 第2章 Python基础-字符编码&数据类型 列表&元祖 练习题
1.创建一个空列表,命名为names,往里面添加old_driver,rain,jack,shanshan,peiqi,black_girl元素 names = ["old_driver&q ...
随机推荐
- Java课程设计+购物车WEB页面
1. 团队名称(keke) 徐婉萍:网络1511 201521123006 2. 项目git地址 3. 项目git提交记录截图 4. 项目功能架构图与主要功能流程图 项目功能架构图 项目主要功能流程图 ...
- 201521123040《Java程序设计》第14周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多数据库相关内容. 2. 书面作业 1. MySQL数据库基本操作 建立数据库,将自己的姓名.学号作为一条记录插入.(截图,需出现自 ...
- 201521123057《Java程序设计》第14周学习总结
0. 本周课程设计发布 Java课程设计 1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多数据库相关内容. 数据库基本操作(目前为止主要介绍了表的基本操作) 创建表 CREATE ...
- 201521123012 《Java程序设计》第十二周学习总结
作业参考文件 1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多线程相关内容. 2. 书面作业 将Student对象(属性:int id, String name,int ag ...
- eclipse里index.jsp头部报错的原因和解决方法
index.jsp的头<%@这句报错的话,是因为没有引入Tomcat的原因.解决:A:Window---Preferences---server---RuntimeEnviroments--Ad ...
- informix服务端口和oralce服务端口
查找informix的服务端口1>>more .profile 找到: INFORMIXDIR=/home/informix INFORMIXSERVER=aaaa2>>cd ...
- shell脚本之算术运算和逻辑运算
目录 算术运算 赋值运算 逻辑运算 短路运算和异或 条件测试 数值测试 字符串测试 文件及其属性测试 存在性测试 存在性及类别测试 文件权限测试 文件特殊权限测试 文件大小测试 文件是否打开 双目测试 ...
- Spring - bean的依赖关系(depends-on属性)
depends-on是bean标签的属性之一,表示一个bean对其他bean的依赖关系.乍一想,不是有ref吗?其实还是有区别的,<ref/>标签是一个bean对其他bean的引用,而de ...
- Oracle函数之chr
chr()函数将ASCII码转换为字符:字符 –> ASCII码:ascii()函数将字符转换为ASCII码:ASCII码 –> 字符: 在oracle中chr()函数和ascii()是一 ...
- PHP获取文件的绝对路径
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 ===========PH ...