用python 抓取B站视频评论,制作词云
python 作为爬虫利器,与其有很多强大的第三方库是分不开的,今天说的爬取B站的视频评论,其实重点在分析得到的评论化作嵌套的字典,在其中取出想要的内容。层层嵌套,眼花缭乱,分析时应细致!步骤分为以下几点:
- F12进入开发者选项
进入B站你想观看的视频页面,例如我看的是咬人猫的一个视频,进入开发者选项后,向下拉取视频评论,这时评论内容才被加载出来,此刻在开发者选项中网络那里就可以看到从网站获取的很多信息,仔细查找,发现我们想要的如下图: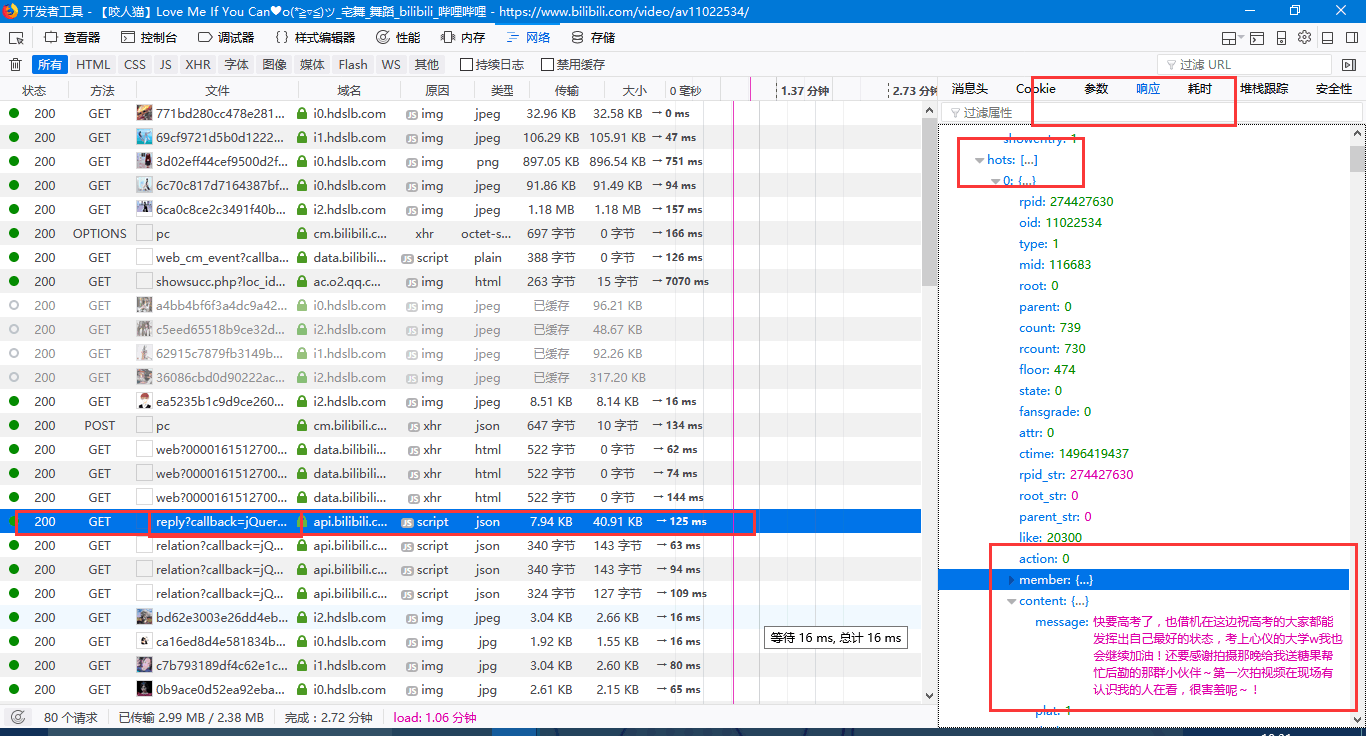
可以看到评论区的内容,点开消息头中的请求网址(https://api.bilibili.com/x/v2/reply?callback=jQuery172048896660782015544_1512700122908&jsonp=jsonp&pn=1&type=1&oid=11022534&sort=0&_=1512700148066),复制粘贴到浏览器中查看,可看到一页的评论内容,取出不必要的网址内容,剩余为:https://api.bilibili.com/x/v2/reply?pn=1&type=1&oid=11022534 ,其中pn即为第几页的评论,oid为视频的av号。 - 分析获取内容字典格式,嵌套内容的包含关系
- 代码获取内容,写入本地文件
import requests
import json
def getHTML(html):
count=1
fi=open('bilibili.txt','w',encoding='utf-8')
while(True):
url=html+str(count)
url=requests.get(url)
if url.status_code==200:
cont=json.loads(url.text)
else:
break
lengthRpy = len(cont['data']['replies'])
if count==1:
try:
lengthHot=len(cont['data']['hots'])
for i in range(lengthHot):
# 热门评论内容
hotMsg=cont['data']['hots'][i]['content']['message']
fi.write(hotMsg + '\n')
leng=len(cont['data']['hots'][i]['replies'])
for j in range(leng):
# 热门评论回复内容
hotMsgRp=cont['data']['hots'][i]['replies'][j]['content']['message']
fi.write(hotMsgRp+'\n')
except:
pass
if lengthRpy!=0:
for i in range(lengthRpy):
comMsg=cont['data']['replies'][i]['content']['message']
fi.write(comMsg + '\n')
# print('评论:',cont['data']['replies'][i]['content']['message'])
leng=len(cont['data']['replies'][i]['replies'])
for j in range(leng):
comMsgRp=cont['data']['replies'][i]['replies'][j]['content']['message']
fi.write(comMsgRp + '\n')
else:
break
print("第%d页写入成功!"%count)
count += 1
fi.close()
print(count-1,'页评论写入成功!') url="https://api.bilibili.com/x/v2/reply?type=1&oid="
av=input("input your url:")
html=url+av+'&pn='
getHTML(html)获取评论内容
- 绘制词云
绘制词云过程分为:读取绘制词云文本,用结巴(第三方库jieba)将文本中高频词汇分出,为词云设置背景图片(可省略),查看及保存绘制词云图
代码如下:from wordcloud import WordCloud,ImageColorGenerator
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
from os import path
import jieba lj=path.dirname(__file__) #当前文件路径
text=open(path.join(lj,'bilibili.txt'),encoding='utf-8').read() #读取的文本
jieba.add_word('咬人猫')
jieba.add_word('喵酱') #添加结巴分辨不了的词汇
jbText=' '.join(jieba.cut(text))
imgMask=np.array(Image.open(path.join(lj,'msk.png'))) #读入背景图片
wc=WordCloud(
background_color='white',
max_words=500,
font_path='msyh.ttc', #默认不支持中文
mask=imgMask, #设置背景图片
random_state=30 #生成多少种配色方案
).generate(jbText)
ImageColorGenerator(imgMask) #根据图片生成词云颜色
# plt.imshow(wc)
# plt.axis('off')
# plt.show()
wc.to_file(path.join(lj,'biliDM.png'))
print('成功保存词云图片!')词云绘制


在代码极少的情况下,python就能做出如此惊人的工作,只能是 人生苦短,我用python 了。
原创不易,尊重版权。转载请注明出处:http://www.cnblogs.com/xsmile/
用python 抓取B站视频评论,制作词云的更多相关文章
- 爬取B站弹幕并且制作词云
目录 爬取弹幕 1. 从手机端口进入网页爬取找到接口 2.代码 制作词云 1.文件读取 2.代码 爬取弹幕 1. 从手机端口进入网页爬取找到接口 2.代码 import requests from l ...
- 【Python3 爬虫】16_抓取腾讯视频评论内容
上一节我们已经知道如何使用Fiddler进行抓包分析,那么接下来我们开始完成一个简单的小例子 抓取腾讯视频的评论内容 首先我们打开腾讯视频的官网https://v.qq.com/ 我们打开[电视剧]这 ...
- python爬取B站视频弹幕分析并制作词云
1.分析网页 视频地址: www.bilibili.com/video/BV19E… 本身博主同时也是一名up主,虽然已经断更好久了,但是不妨碍我爬取弹幕信息来分析呀. 这次我选取的是自己 唯一的爆款 ...
- python 爬取B站视频弹幕信息
获取B站视频弹幕,相对来说很简单,需要用到的知识点有requests.re两个库.requests用来获得网页信息,re正则匹配获取你需要的信息,当然还有其他的方法,例如Xpath.进入你所观看的视频 ...
- Python爬取B站视频信息
该文内容已失效,现已实现scrapy+scrapy-splash来爬取该网站视频及用户信息,由于B站的反爬封IP,以及网上的免费代理IP绝大部分失效,无法实现一个可靠的IP代理池,免费代理网站又是各种 ...
- python抓取知识星球精选帖,制作为pdf文件
版权声明:本文为xing_star原创文章,转载请注明出处! 本文同步自http://javaexception.com/archives/90 背景: 这两年知识付费越来越热,我也加入了不少知识星球 ...
- python抓取某学院视频
视频抓取原理:获取所有的知识类别id->然后获取其子项->根据子项链接分析获取该类课程数->循环获取链接指向的视频.需要安装python库:requestspython解析xml使用 ...
- python 爬取腾讯视频评论
import urllib.request import re import urllib.error headers=('user-agent','Mozilla/5.0 (Windows NT 1 ...
- 用Python爬取B站、腾讯视频、爱奇艺和芒果TV视频弹幕!
众所周知,弹幕,即在网络上观看视频时弹出的评论性字幕.不知道大家看视频的时候会不会点开弹幕,于我而言,弹幕是视频内容的良好补充,是一个组织良好的评论序列.通过分析弹幕,我们可以快速洞察广大观众对于视频 ...
随机推荐
- Unix时代的开创者Ken Thompson
自图灵奖诞生以来,其获得者一直都是计算机领域的科学家与学者,而在所有这些界的图灵奖中只有唯一的一届有个例外,那就是Ken Thompson与Dennis M. Ritchie,他们都是计算机软件工程师 ...
- onclick事件触发 input type=“file” 上传文件
添加按钮: <input type="button" name="button" value="浏览" onclick="j ...
- PHP常用配置
Php配置文件:php.ini(使用‘;’表示注释) Php的配置项可以在配置文件中配置,也可以在脚本中使用ini_set()函数临时配置. 语言相关配置: 1. engine:设置PHP引擎是否可用 ...
- 编译错误:expected an indented block
python 对缩进要求非常严格,当运行时出现以下几种情况时,就需要修改缩进: 1.expected an indented block 直接缩进4个space空格或者一个tab.
- swift 之 namespace
场景: 项目中类名过长,造成不能根据文件名区分出来,并且如果一个模块的类较多时,很难取一个比较优雅的名字.为了使模块名可读, 我们一般的做法就是添加模块前缀.但是如果模块中还有个子模块,如果还继续按 ...
- angular之scope详解
AngularJS的一些指令会创建子作用域,而子作用域会继承自父作用域,大致可分为以下3种 1.创建子作用域并继承父作用域的指令 ng-repeat ng-include ng-switch ng-c ...
- Surround the Trees(凸包)
Surround the Trees Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Other ...
- Flex布局语法
flexbox 弹性盒布局和布局原理 新版的flexbox规范分两部分:一部分是container,一部分是 items. flexbox是一整套布局规范,包含了多个css属性,所以学习起来比`flo ...
- 启动Apache出现问题:一直停留在启动界面
问题描述: 由于需要php_curl模块,因此直接在php.ini文件将前面的分号去掉 ,但是重启Apache时出现:一直停留在启动界面,Apache无法正常启动,查看错误日志,显示如下: 解决方 ...
- 《天书夜读:从汇编语言到windows内核编程》三 练习反汇编C语言程序
1) Debug版本算法反汇编,现有如下3×3矩阵相乘的程序: #define SIZE 3 int MyFunction(int a[SIZE][SIZE],int b[SIZE][SIZE],in ...