caffe训练CIFAR数据库
CIFAR-10是一个用于普适物体识别的数据集。Cifar-10由60000张32*32的RGB彩色图片构成,50000张训练图片,10000张测试图片,分为10类。cifar下载地址: http://www.cs.toronto.edu/~kriz/cifar.html

数据集分为3个版本,分别是Matlab、python和二进制格式的,这里选择二进制格式的下载。包含五个训练文件,一个测试文件:
1. cifar二进制数据库转换成lmdb文件
新建一个binToLmdb.bat的脚本文件,输入一下内容:
D:\Software\Caffe\caffe-master\Build\x64\Release\convert_cifar_data.exe
D:\TestData\cifar-10-batches-bin D:\TestData\cifar-10-batches-bin lmdb
pause第一个参数是caffe中已经编译好的cifar数据库转换文件,第二个参数是cifar数据库存放路径,第三个参数是生成的lmdb数据库文件存放路径,第四个参数是转换的目标格式。
双击inToLmdb.bat文件,生成cifar的训练和测试数据:
2.计算训练数据的均值文件
新建一个mean.bat脚本文件,输入以下内容:
D:\Software\Caffe\caffe-master\Build\x64\Release\compute_image_mean.exe
D:\TestData\cifar-10-batches-bin\cifar10_test_lmdb
D:\TestData\cifar-10-batches-bin\cifarMean.binaryproto
pause双击执行,在目标路径下生成cifar训练数据集的均值文件cifarMean.binaryproto文件。
3. 执行训练
对.\examples\cifar10下的 “cifar10_full_solver.prototxt”文件和“cifar10_full_train_test.prototxt”文件做一些修改,用于下边的训练,修改过程略了。
新建一个train.bat脚本文件,输入以下内容:
D:\Software\Caffe\caffe-master\Build\x64\Release\caffe.exe train
--solver=D:\Software\Caffe\caffe-master\examples\cifar10\cifar10_full_solver.prototxt
pause双击文件,开始训练,执行结果,训练精度大概是78%:
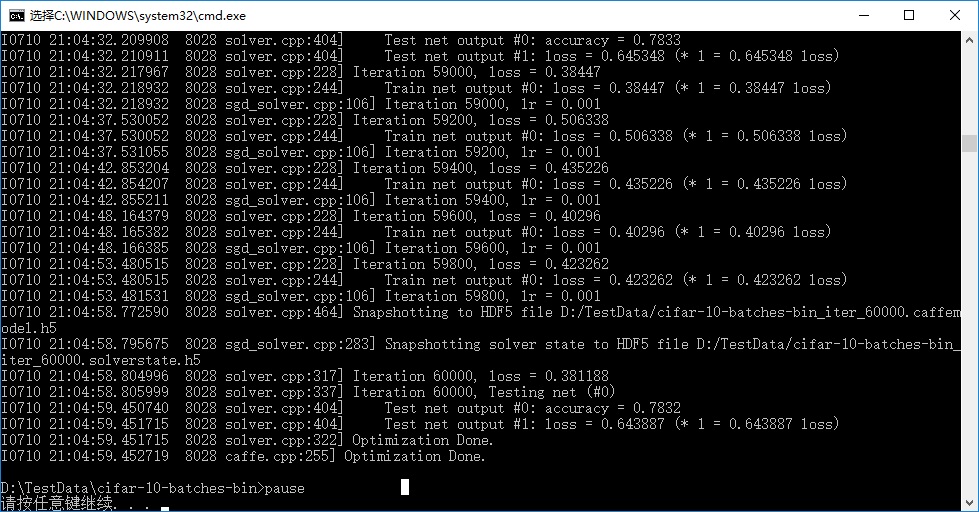
caffe训练CIFAR数据库的更多相关文章
- 实践详细篇-Windows下使用Caffe训练自己的Caffemodel数据集并进行图像分类
三:使用Caffe训练Caffemodel并进行图像分类 上一篇记录的是如何使用别人训练好的MNIST数据做训练测试.上手操作一边后大致了解了配置文件属性.这一篇记录如何使用自己准备的图片素材做图像分 ...
- caffe︱深度学习参数调优杂记+caffe训练时的问题+dropout/batch Normalization
一.深度学习中常用的调节参数 本节为笔者上课笔记(CDA深度学习实战课程第一期) 1.学习率 步长的选择:你走的距离长短,越短当然不会错过,但是耗时间.步长的选择比较麻烦.步长越小,越容易得到局部最优 ...
- 使用caffe训练mnist数据集 - caffe教程实战(一)
个人认为学习一个陌生的框架,最好从例子开始,所以我们也从一个例子开始. 学习本教程之前,你需要首先对卷积神经网络算法原理有些了解,而且安装好了caffe 卷积神经网络原理参考:http://cs231 ...
- Caffe训练AlexNet网络,精度不高或者为0的问题结果
当我们使用Caffe训练AlexNet网络时,会遇到精度一值在低精度(30%左右)升不上去,或者精度总是为0,如下图所示: 出现这种情况,可以尝试使用以下几个方法解决: 1.数据样本量是否太少,最起码 ...
- caffe训练自己的图片进行分类预测--windows平台
caffe训练自己的图片进行分类预测 标签: caffe预测 2017-03-08 21:17 273人阅读 评论(0) 收藏 举报 分类: caffe之旅(4) 版权声明:本文为博主原创文章,未 ...
- [caffe] caffe训练tricks
Tags: Caffe Categories: Tools/Wheels --- 1. 将caffe训练时将屏幕输出定向到文本文件 caffe中自带可以画图的工具,在caffe路径下: ./tools ...
- 实践详细篇-Windows下使用VS2015编译的Caffe训练mnist数据集
上一篇记录的是学习caffe前的环境准备以及如何创建好自己需要的caffe版本.这一篇记录的是如何使用编译好的caffe做训练mnist数据集,步骤编号延用上一篇 <实践详细篇-Windows下 ...
- ubuntu16.04+caffe训练mnist数据集
1. caffe-master文件夹权限修改 下载的caffe源码编译的caffe-master文件夹貌似没有写入权限,输入以下命令修改: sudo chmod -R 777 ~/caffe-ma ...
- python+caffe训练自己的图片数据流程
1. 准备自己的图片数据 选用部分的Caltech数据库作为训练和测试样本.Caltech是加州理工学院的图像数据库,包含Caltech101和Caltech256两个数据集.该数据集是由Fei-Fe ...
随机推荐
- Spring《八-一》CGLIB代理和自动代理
CGLIB代理 配置文档 <bean id="logProxy" class="org.springframework.aop.framework.ProxyFac ...
- WEBGL学习笔记(七):实践练手1-飞行类小游戏之游戏控制
接上一节,游戏控制首先要解决的就是碰撞检测了 这里用到了学习笔记(三)射线检测的内容了 以鸟为射线原点,向前.上.下分别发射3个射线,射线的长度较短大概为10~30. 根据上一节场景的建设,我把y轴设 ...
- NPOI导出功能
利用NPOI组件将数据中想要的数据导出到excel表格中. demo如下 using System; using System.Collections.Generic; using System.Li ...
- 01--[转]C++强大背后
[转]C++强大背后 2014-01-22 分类:互联网 阅读(9295) 评论(6) 在31年前(1979年),一名刚获得博士学位的研究员,为了开发一个软件项目发明了一门新编程语言,该研究员名为Bj ...
- MVC传值前台
ViewBag.model = bLL.GetModel((int)id); ViewBag.RecruitmentTime = ViewBag.model.RecruitmentTime.ToStr ...
- Java中数组遍历
就是将数组中的每个元素分别获取出来,就是遍历.遍历也是数组操作中的基石. 数组的索引是 0 到 lenght-1 ,可以作为循环的条件出现 public class ArrayDemo4 { publ ...
- 路飞学城Python-Day117
jango用户登录界面 """ Django settings for cnblog project. Generated by 'django-admin startp ...
- "SetDestination" can only be called on an active agent that has been placed on a NavMesh. 解决办法
1.设置了 navmesh之后 要bake 也就是烘焙之后 才有效果 2.在unity 中 window->navigation 4.基本上问题应该得以解决:
- C++基础 (8) 第八天 数组指针 模板指针 C语言中的多态 模板函数
1昨日回顾 2 多态的练习-圆的图形 3多态的练习-程序员薪资 4员工管理案例-抽象类和技术员工的实现 employee.h: employee.cpp: technician.h: technici ...
- Ubuntu安装Docker 适合Ubuntu17.04版本
Docker介绍 Docker是一个开源的容器引擎,它有助于更快地交付产品.Docker可将应用程序和基础设施层隔离,并且将基础设施当作程序一样进行管理.使用Docker,可以更快地打包,测试以及部署 ...