(5)pyspark----共享变量
如果想在节点之间共享一份变量,spark提供了两种特定的共享变量,来完成节点之间的变量共享。
(1)广播变量(2)累加器
二、广播变量
概念:
广播变量允许程序员缓存一个只读的变量在每台机器上,而不是每个任务保存一个拷贝。例如,利用广播变量,我们能够以一种更有效率的方式将一个大数据量输入集合的副本分配给每个节点。
一个广播变量可以通过调用SparkContext.broadcast(v)方法从一个初始变量v中创建。广播变量是v的一个包装变量,它的值可以通过value方法访问。
用途:比如一个配置文件,可以共享给所有节点。比如一个Node的计算结果需要共享给其他节点。
声明:broadcast
调用broadcast,Scala中一切可序列化的对象都可以进行广播。
sc.broadcast(xxx)
引用广播变量数据:value
可在各个计算节点中通过 bc.value来引用广播的数据。

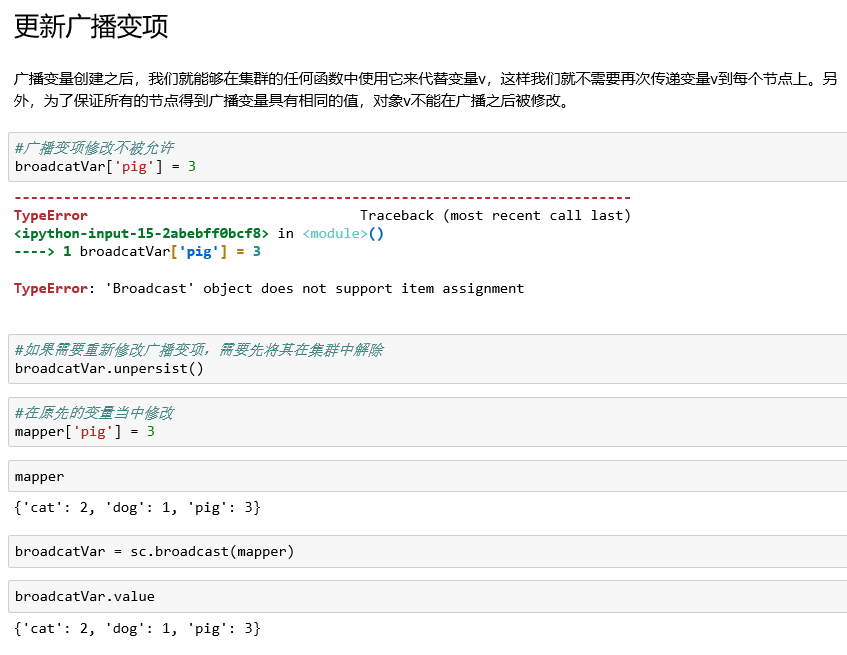
更新广播变量:unpersist
由于广播变量是只读的,即广播出去的变量没法再修改,
利用unpersist函数将老的广播变量删除,然后重新广播一遍新的广播变量。
bc.unpersist()
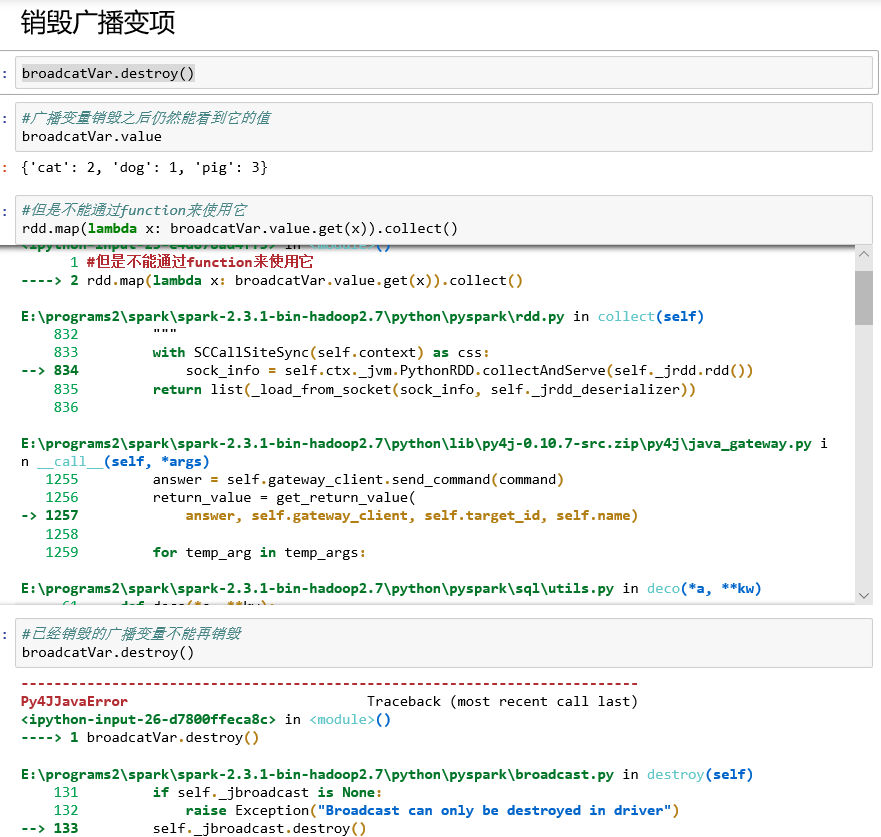
销毁广播变量:destroy
bc.destroy()可将广播变量的数据和元数据一同销毁,销毁之后就不能再使用了。
三、累加器
概念:
累加器是一种只能利用关联操作做“加”操作的变数,因此他能够快速执行并行操作。而且其能够操作counters和sums。Spark原本支援数值类型的累加器,程序员可以自行增加可被支援的类型。如果建立一个具体的累加器,其可在spark UI上显示。
用途:
对信息进行聚合,累加器的一个常见的用途是在调试时对作业的执行过程中事件进行计数。
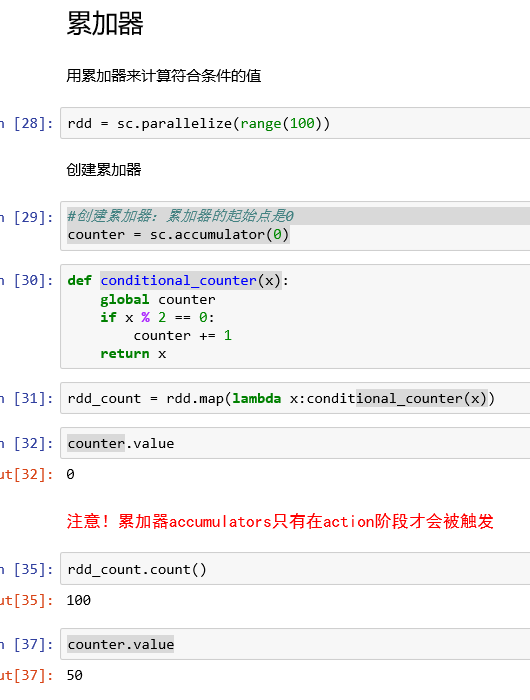
创建累加器:accumulator
调用SparkContext.accumulator(v)方法从一个初始变量v中创建。
运行在集群上的任务可以通过add方法或者使用+=操作来给它加值。然而,它们无法读取这个值。和广播变量相反,累加器是一种add only的变项。
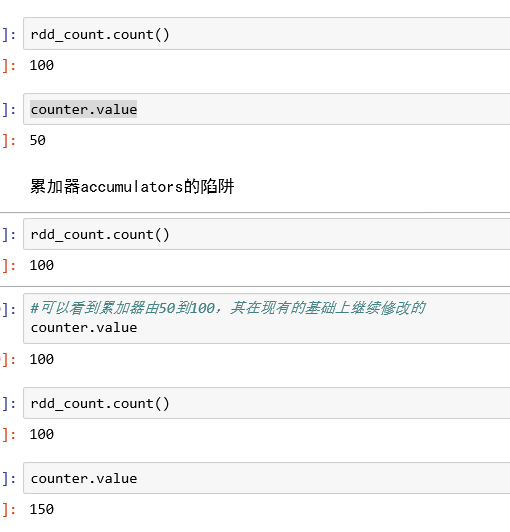
累加器的陷阱
打破累加器陷阱:persist函数

存累加器初始值:

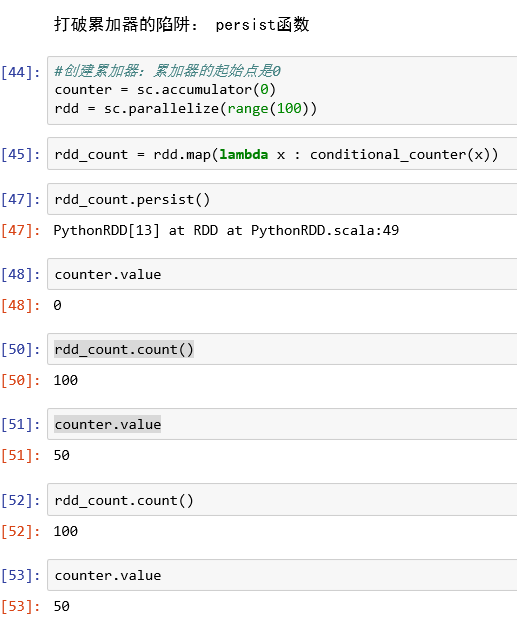
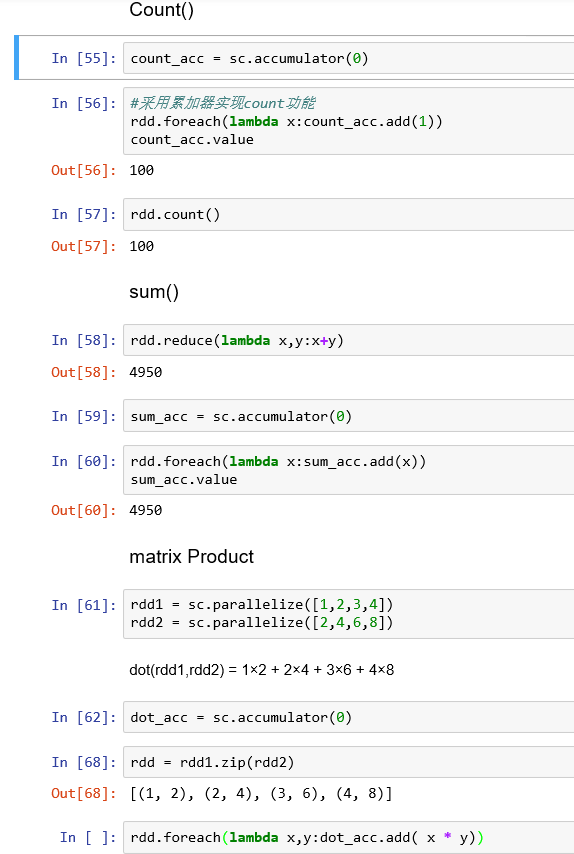
累加器实现一些基本的功能:
(5)pyspark----共享变量的更多相关文章
- pyspark 内容介绍(一)
pyspark 包介绍 子包 pyspark.sql module pyspark.streaming module pyspark.ml package pyspark.mllib package ...
- 5 pyspark学习---Broadcast&Accumulator&sparkConf
1 对于并行处理,Apache Spark使用共享变量.当驱动程序将任务发送给集群上的执行者时,集群中的每个节点上都有一个共享变量的副本,这样就可以用于执行任务了. 2 两种支持得类型 (1)Broa ...
- spark教程(14)-共享变量
spark 使用的架构是无共享的,数据分布在不同节点,每个节点有独立的 CPU.内存,不存在全局的内存使得变量能够共享,驱动程序和任务之间通过消息共享数据 举例来说,如果一个 RDD 操作使用了驱动程 ...
- Spark——共享变量
Spark执行不少操作时都依赖于闭包函数的调用,此时如果闭包函数使用到了外部变量驱动程序在使用行动操作时传递到集群中各worker节点任务时就会进行一系列操作: 1.驱动程序使将闭包中使用变量封装成对 ...
- spark 2.0 中 pyspark 对接 Ipython
pyspark 2.0 对接 ipython 在安装spark2.0 后,以往的对接ipython方法失效,会报如下错错误: 因为在spark2.0后对接ipython的方法进行了变更我们只需要在py ...
- sparksql---通过pyspark实现
上次在spark的一个群里面,众大神议论:dataset会取代rdd么? 大神1:听说之后的mlib都会用dataset来实现,呜呜,rdd要狗带 大神2:dataset主要是用来实现sql的,跟ml ...
- 动手学servlet(五) 共享变量
1. 无论对象的作用域如何,设置和读取共享变量的方法是一致的 -setAttribute("varName",obj); -getAttribute("varName&q ...
- Win7 单机Spark和PySpark安装
欢呼一下先.软件环境菜鸟的我终于把单机Spark 和 Pyspark 安装成功了.加油加油!!! 1. 安装方法参考: 已安装Pycharm 和 Intellij IDEA. win7 PySpark ...
- Java多线程——线程范围内共享变量
多个线程访问共享对象和数据的方式 1.如果每个线程执行的代码相同,可以使用同一个Runnable对象,这个Runnable对象中有那个共享数据,例如,买票系统就可以这么做. package java_ ...
- jupyter notebook + pyspark 环境搭建
安装并启动jupyter 安装 Anaconda 后, 再安装 jupyter pip install jupyter 设置环境 ipython --ipython-dir= # override t ...
随机推荐
- 「BZOJ3339」Rmq Problem(5366)
题目描述 输入 输出 样例输入 7 5 0 2 1 0 1 3 2 1 3 2 3 1 4 3 6 2 7 提示 这个题说来也挺有意思的 当时集训的时候遇到了一道类似的题,但是题意与此不同,我太菜了, ...
- 如何在sublime上运行php
这个问题虽然随便一搜都能有很多答案,但是我当时都没有顺利解决我会详细地写出较为容易理解和操作的步骤第一步,配置PHP环境变量如图一所示1.找到 我的电脑 -属性2.高级系统设置3.环境变量4.找到“系 ...
- sql修改字段值
update dfw_USER_ACCOUNTS set USER_INTEGRAL="20" where USER_INTEGRAL="17"
- MVC架构之delegate
Qt的MVC架构可以实现很多数据显示的功能,本次主要对代理进行一个总结: 重实现QStyledItemDelegate类,实现自定义类. (1)ComboxDelegate.h #ifndef COM ...
- C# 常用字符串加密解密方法
using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Sec ...
- String与StringBuffer与StringBuilder
package test; public class Test { public static void main(String[] args) { StringBuffer sb = new Str ...
- iOS富文本(一)属性化字符串
概述 iOS一些复杂的文本布局一般都是由底层的Core Text来实现的,直到iOS7苹果发布了Text Kit框架,Text Kit能够很简单实现一些复杂的文本样式以及布局,而Text Kit富文本 ...
- Mysql 奇怪的连接错误
今天,碰到了一个数据库连接问题: 不像之前在linux上mysql连接问题,那是权限设置.而这次问题的起源是: 我想要往mysql导入csv文件,可是因为文件比較大.有88M数据:使用navicatc ...
- Zookeeper源代码编译为Eclipseproject(win7下Ant编译)
为了深入学习ZooKeeper源代码,首先就想到将其导入到Eclispe中,所以要先将其编译为Eclispeproject. 1.什么是Ant??? Apache Ant™ Apache Ant is ...
- BEGINNING SHAREPOINT® 2013 DEVELOPMENT 第11章节--为Office和SP解决方式开发集成Apps 集成SP和Office App
BEGINNING SHAREPOINT® 2013 DEVELOPMENT 第11章节--为Office和SP解决方式开发集成Apps 集成SP和Office App 你能够用两种 ...