caffe 参数介绍 solver.prototxt
转载自 http://blog.csdn.net/cyh_24/article/details/51537709
solver.prototxt
net: "models/bvlc_alexnet/train_val.prototxt"
test_iter: 1000 #
test_interval: 1000 #
base_lr: 0.01 # 开始的学习率
lr_policy: "step" # 学习率的drop是以gamma在每一次迭代中
gamma: 0.1
stepsize: 100000 # 每stepsize的迭代降低学习率:乘以gamma
display: 20 # 每display次打印显示loss
max_iter: 450000 # train 最大迭代max_iter
momentum: 0.9 #
weight_decay: 0.0005 #
snapshot: 10000 # 没迭代snapshot次,保存一次快照
snapshot_prefix: "models/bvlc_reference_caffenet/caffenet_train"
solver_mode: GPU # 使用的模式是GPU test_iter
在测试的时候,需要迭代的次数,即test_iter* batchsize(测试集的)=测试集的大小,测试集的 batchsize可以在prototx文件里设置。test_interval
训练的时候,每迭代test_interval次就进行一次测试。momentum
灵感来自于牛顿第一定律,基本思路是为寻优加入了“惯性”的影响,这样一来,当误差曲面中存在平坦区的时候,SGD可以更快的速度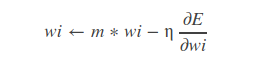
train_val.prototxt
layer { # 数据层
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN # 表明这是在训练阶段才包括进去
}
transform_param { # 对数据进行预处理
mirror: true # 是否做镜像
crop_size: 227
# 减去均值文件
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
}
data_param { # 设定数据的来源
source: "examples/imagenet/ilsvrc12_train_lmdb"
batch_size: 256
backend: LMDB
}
}layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST # 测试阶段
}
transform_param {
mirror: false # 是否做镜像
crop_size: 227
# 减去均值文件
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
}
data_param {
source: "examples/imagenet/ilsvrc12_val_lmdb"
batch_size: 50
backend: LMDB
}
}lr_mult
学习率,但是最终的学习率需要乘以 solver.prototxt 配置文件中的 base_lr .如果有两个 lr_mult, 则第一个表示 weight 的学习率,第二个表示 bias 的学习率
一般 bias 的学习率是 weight 学习率的2倍’decay_mult
权值衰减,为了避免模型的over-fitting,需要对cost function加入规范项。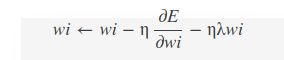
num_output
卷积核(filter)的个数kernel_size
卷积核的大小。如果卷积核的长和宽不等,需要用 kernel_h 和 kernel_w 分别设定
stride
卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。pad
扩充边缘,默认为0,不扩充。扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。
也可以通过pad_h和pad_w来分别设定。weight_filler
权值初始化。 默认为“constant”,值全为0.
很多时候我们用”xavier”算法来进行初始化,也可以设置为”gaussian”
weight_filler {
type: "gaussian"
std: 0.01
}- bias_filler
偏置项的初始化。一般设置为”constant”, 值全为0。
bias_filler {
type: "constant"
value: 0
}bias_term
是否开启偏置项,默认为true, 开启
group
分组,默认为1组。如果大于1,我们限制卷积的连接操作在一个子集内。
卷积分组可以减少网络的参数,至于是否还有其他的作用就不清楚了。每个input是需要和每一个kernel都进行连接的,但是由于分组的原因其只是与部分的kernel进行连接的
如: 我们根据图像的通道来分组,那么第i个输出分组只能与第i个输入分组进行连接。pool
池化方法,默认为MAX。目前可用的方法有 MAX, AVE, 或 STOCHASTICdropout_ratio
丢弃数据的概率
caffe 参数介绍 solver.prototxt的更多相关文章
- Caffe solver.prototxt学习
在solver解决下面的四个问题: a.训练的记录(bookkeeping),创建用于training以及test的网络结构: b.使用前向以及反向过程对training网络参数学习的过程: c.对t ...
- Caffe的solver参数介绍
版权声明:转载请注明出处,谢谢! https://blog.csdn.net/Quincuntial/article/details/59109447 1. Parameters solver.p ...
- [转]caffe中solver.prototxt参数说明
https://www.cnblogs.com/denny402/p/5074049.html solver算是caffe的核心的核心,它协调着整个模型的运作.caffe程序运行必带的一个参数就是so ...
- 4.caffe:train_val.prototxt、 solver.prototxt 、 deploy.prototxt( 创建模型与编写配置文件)
一,train_val.prototxt name: "CIFAR10_quick" layer { name: "cifar" type: "Dat ...
- caffe 中的一些参数介绍
转自:http://blog.csdn.net/cyh_24/article/details/51537709 solver.prototxt net: "models/bvlc_alexn ...
- caffe solver.prototxt 生成
from caffe.proto import caffe_pb2 s = caffe_pb2.SolverParameter() path='/home/xxx/data/' solver_file ...
- 人工智能深度学习Caffe框架介绍,优秀的深度学习架构
人工智能深度学习Caffe框架介绍,优秀的深度学习架构 在深度学习领域,Caffe框架是人们无法绕过的一座山.这不仅是因为它无论在结构.性能上,还是在代码质量上,都称得上一款十分出色的开源框架.更重要 ...
- caffe简单介绍
从四个层次来理解caffe:Blob.Layer.Net.Solver. 1.BlobBlob是caffe基本的数据结构,用四维矩阵 Batch×Channel×Height×Weight表示,存储了 ...
- Caffe源代码中Solver文件分析
Caffe源代码(caffe version commit: 09868ac , date: 2015.08.15)中有一些重要的头文件,这里介绍下include/caffe/solver.hpp文件 ...
随机推荐
- 安卓代码迁移:ActionBarActivity: cannot be resolved to a type
参考链接:http://stackoverflow.com/questions/18830736/actionbaractivity-cannot-be-resolved-to-a-type in e ...
- MVC返回400 /404/...
return new HttpStatusCodeResult(HttpStatusCode.BadRequest); //HttpStatusCode statusCode 枚举 // HttpSt ...
- mysql1064问题完美解决
1.mysql报错code代表具体意思 1005:创建表失败 1006:创建数据库失败 1007:数据库已存在,创建数据库失败 1008:数据库不存在,删除数据库失败 1009:不能删除数据库文件导致 ...
- vue-router 懒加载
懒加载:也叫延迟加载,即在需要的时候进行加载,按需加载. 那vue 为什么需要懒加载呢? 使用 vue-cli构建的项目,在默认情况下,执行 npm run build 会将所有的 js代码打包为一 ...
- top问题
1. 从10万个数中找10个最大的数 对于这种题目,最普通的想法是先对这10万个数进行排序,然后再选取数组中前10个数,即为最后的答案,排序算法的时间复杂度不下于O(N lgN).最好的方法是建立一个 ...
- centos7关闭防火墙以及查看防火墙状态
1.关闭firewall:systemctl stop firewalld.service #停止firewall systemctl disable firewalld.service #禁止fir ...
- [Ynoi2015]即便看不到未来
题目大意: 给定一个序列,每次询问,给出一个区间$[l,r]$. 设将区间内的元素去重后重排的数组为$p$,求$p$中长度为$1\sim 10$的极长值域连续段个数. 长度为$L$的极长值域连续段的定 ...
- Linux之部署虚拟环境、安装系统
本章涵盖了Linux的优势和哲学思想,零基础详细记录了部署虚拟环境安装Linux系统,完整演示了VM虚拟机的安装与配置过程,以及Centos 7系统的安装.配置过程和初始化方法. Linux优势分析: ...
- mongodb分片集群开启安全认证
原文地址:https://blog.csdn.net/uncle_david/article/details/78713551 对于搭建好的mongodb副本集加分片集群,为了安全,启动安全认证,使用 ...
- Mysql学习总结(39)——30条MySql语句优化技巧
1.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描. 2.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉 ...