[1] first day
一、几个工具包
【1】pandas(数据分析工具)
https://zhuanlan.zhihu.com/p/33230331
https://zhuanlan.zhihu.com/p/25013519
【2】lightbgm(梯度boosting框架,使用基于学习算法的决策树)
XGBOOST与LightGBM的区别: https://zhuanlan.zhihu.com/p/25308051 https://www.msra.cn/zh-cn/news/features/lightgbm-20170105
XGBOOST/LightGBM/CatBoost: https://www.jiqizhixin.com/articles/2018-03-18-4
二、遇到的问题
1. ['nunique'] 表示有多少个种类
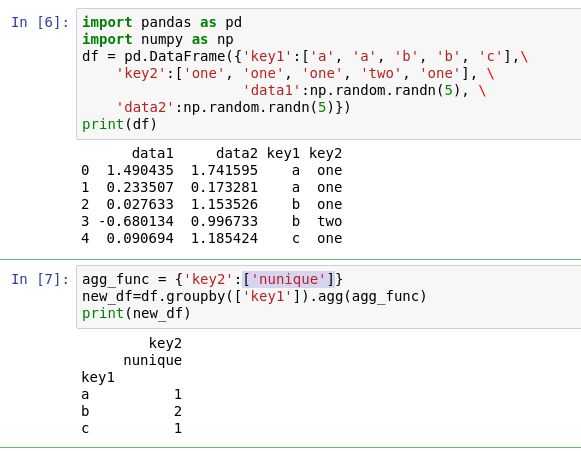
对a来说只有一个种类one,对b来说有两个种类one/two,对c来说有一个种类one。
2. ('_'.join(col))

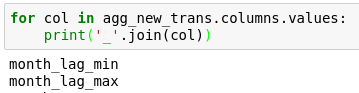
在两个字符串之间添加连接符 _
3. agg_new_trans.columns.values与agg_new_trans.columns
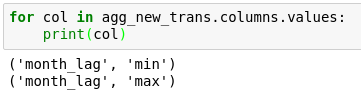

两者在for迭代取值的时候一样
4. groupby+agg(np.ptp) 群体中最大值和最小值之间的差异
结合 pd.DatetimeIndex
5. 日期相关的类型区别
df['first_active_month'] = pd.to_datetime(df['first_active_month']) #经过函数 pd.to_datetime,dtype: datetime64[ns]
df['year'] = df['first_active_month'].dt.year (或者.dt.month/.dt.days)int64类型
df['first_active_month'].dt.date #dtype: object date可以做减法,获取两个日期之间有多少days
6. pandas中.value_counts()的用法
value_counts()是一种查看表格某列中有多少个不同值的快捷方法,并计算每个不同值有在该列中有多少重复值。(返回两个结果)
value_counts()是Series拥有的方法,一般在DataFrame中使用时,需要指定对哪一列或行使用

7. LabelEncoder 将Label标准化,用来对分类型特征值进行编码,即对不连续的数值或文本进行编码。
https://blog.csdn.net/u010412858/article/details/78386407
https://blog.csdn.net/quintind/article/details/79850455
8. pd.concat: 使用pd.concat[train,test]时,当train与test有相同的列名称的时候,如feature,会自动区分两个feature,并命名为feature_1与feature_2。
9. set(df['class label']) python中set表示集合,元素只出现一次
list:链表,有序的项目, 通过索引进行查找,使用方括号”[]”;
tuple:元组,元组将多样的对象集合到一起,不能修改,通过索引进行查找, 使用括号”()”;
dict:字典,字典是一组键(key)和值(value)的组合,通过键(key)进行查找,没有顺序, 使用大括号”{}”;
set:集合,无序,元素只出现一次, 自动去重,使用”set([])”
10. pandas使用get_dummies进行one-hot编码
离散特征的编码分为两种情况:
1]、离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码
2]、离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}
https://blog.csdn.net/lujiandong1/article/details/52836051
11. KFold Stratified k-fold:实现了分层交叉切分
https://blog.csdn.net/FontThrone/article/details/79220127
K折交叉验证:sklearn.model_selection.KFold(n_splits=3, shuffle=False, random_state=None)
思路:将训练/测试数据集划分n_splits个互斥子集,每次用其中一个子集当作验证集,剩下的n_splits-1个作为训练集,进行n_splits次训练和测试,得到n_splits个结果 https://blog.csdn.net/kancy110/article/details/74910185
使用:
FOLDs = KFold(n_splits=5, shuffle=True, random_state=1989)
for fold_, (trn_idx, val_idx) in enumerate(FOLDs.split(train)):
其中: fold_为第几个n_splits的索引,从0开始
随机推荐
- Cloud Foundry中DEA与warden通信完毕应用port监听
在Cloud Foundry v2版本号中,DEA为一个用户应用执行的控制模块,而应用的真正执行都是依附于warden. 更详细的来说,是DEA接收到Cloud Controller的请求:DEA发送 ...
- 支付宝钱包手势password破解实战(root过的手机可直接绕过手势password)
/* 本文章由 莫灰灰 编写,转载请注明出处. 作者:莫灰灰 邮箱: minzhenfei@163.com */ 背景 随着移动互联网的普及以及手机屏幕越做越大等特点,在移动设备上购物.消费已是 ...
- 基于Torndb的简易ORM
============================================================================ 原创作品,同意转载. 转载时请务必以超链接形式 ...
- Windows 10彻底关闭自动更新
关键点:把流量计费开启.
- JavaScript --晋级--优
https://zhuanlan.zhihu.com/p/23412169 总计划 JavaScript 教程 http://www.w3school.com.cn/js/ JavaScr ...
- day63-webservice 04.JaxWsServerFactoryBean和SOAP1.2
<wsdl:definitions xmlns:ns1="http://schemas.xmlsoap.org/soap/http" xmlns:soap12="h ...
- 【NOIP2011 Day 1】选择客栈
[问题描述] 丽江河边有n家客栈,客栈按照其位置顺序从1到n编号.每家客栈都按照某一种色调进行装饰(总共k种,用整数0 ~ k-1表示),且每家客栈都设有一家咖啡店,每家咖啡店均有各自的最低消费.两位 ...
- html页面、canvas导出图片
背景:项目现场提出将一个html做的图形页面导出为一张图片的需求,在网上搜了一下,发现都不是很全面,所以综合了很多大神的帖子,自己再次封装,以适用项目需求. 所需js库:html2canvas.js( ...
- java+appium+安卓模拟器实现app自动化Demo
网上有比较多相关教程,自己写一遍,加深下印象. 环境搭建 据说,很多人都被繁琐的环境搭建给吓到了. 是的,确实,繁琐. node.js 网址 cmd输入node -v,出现下图说明成功. JDK 网址 ...
- CTF-Mayday
打开下载的Mayday.txt文件: 温柔 知足突然好想你 拥抱突然好想你 拥抱温柔 知足温柔 知足突然好想你 拥抱突然好想你 拥抱温柔 知足温柔 知足突然好想你 拥抱突然好想你 拥抱温柔 ...