node.js流复制文件
转自:http://segmentfault.com/a/1190000000519006
nodejs的fs模块并没有提供一个copy的方法,但我们可以很容易的实现一个,比如:
var source = fs.readFileSync('/path/to/source', {encoding: 'utf8'});
fs.writeFileSync('/path/to/dest', source);
这种方式是把文件内容全部读入内存,然后再写入文件,对于小型的文本文件,这没有多大问题,比如grunt-file-copy就是这样实现的。但是对于体积较大的二进制文件,比如音频、视频文件,动辄几个GB大小,如果使用这种方法,很容易使内存“爆仓”。理想的方法应该是读一部分,写一部分,不管文件有多大,只要时间允许,总会处理完成,这里就需要用到流的概念。
如上面高大上的图片所示,我们把文件比作装水的桶,而水就是文件里的内容,我们用一根管子(pipe)连接两个桶使得水从一个桶流入另一个桶,这样就慢慢的实现了大文件的复制过程。
Stream在nodejs中是EventEmitter的实现,并且有多种实现形式,例如:
- http responses request
- fs read write streams
- zlib streams
- tcp sockets
- child process stdout and stderr
上面的文件复制可以简单实现一下:
var fs = require('fs');
var readStream = fs.createReadStream('/path/to/source');
var writeStream = fs.createWriteStream('/path/to/dest');
readStream.on('data', function(chunk) { // 当有数据流出时,写入数据
writeStream.write(chunk);
});
readStream.on('end', function() { // 当没有数据时,关闭数据流
writeStream.end();
});
上面的写法有一些问题,如果写入的速度跟不上读取的速度,有可能导致数据丢失。正常的情况应该是,写完一段,再读取下一段,如果没有写完的话,就让读取流先暂停,等写完再继续,于是代码可以修改为:
var fs = require('fs');
var readStream = fs.createReadStream('/path/to/source');
var writeStream = fs.createWriteStream('/path/to/dest');
readStream.on('data', function(chunk) { // 当有数据流出时,写入数据
if (writeStream.write(chunk) === false) { // 如果没有写完,暂停读取流
readStream.pause();
}
});
writeStream.on('drain', function() { // 写完后,继续读取
readStream.resume();
});
readStream.on('end', function() { // 当没有数据时,关闭数据流
writeStream.end();
});
或者使用更直接的pipe
// pipe自动调用了data,end等事件
fs.createReadStream('/path/to/source').pipe(fs.createWriteStream('/path/to/dest'));
下面是一个更加完整的复制文件的过程
var fs = require('fs'),
path = require('path'),
out = process.stdout;
var filePath = '/Users/chen/Movies/Game.of.Thrones.S04E07.1080p.HDTV.x264-BATV.mkv';
var readStream = fs.createReadStream(filePath);
var writeStream = fs.createWriteStream('file.mkv');
var stat = fs.statSync(filePath);
var totalSize = stat.size;
var passedLength = 0;
var lastSize = 0;
var startTime = Date.now();
readStream.on('data', function(chunk) {
passedLength += chunk.length;
if (writeStream.write(chunk) === false) {
readStream.pause();
}
});
readStream.on('end', function() {
writeStream.end();
});
writeStream.on('drain', function() {
readStream.resume();
});
setTimeout(function show() {
var percent = Math.ceil((passedLength / totalSize) * 100);
var size = Math.ceil(passedLength / 1000000);
var diff = size - lastSize;
lastSize = size;
out.clearLine();
out.cursorTo(0);
out.write('已完成' + size + 'MB, ' + percent + '%, 速度:' + diff * 2 + 'MB/s');
if (passedLength < totalSize) {
setTimeout(show, 500);
} else {
var endTime = Date.now();
console.log();
console.log('共用时:' + (endTime - startTime) / 1000 + '秒。');
}
}, 500);
可以把上面的代码保存为copy.js试验一下
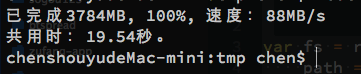
我们添加了一个递归的setTimeout(或者直接使用setInterval)来做一个旁观者,每500ms观察一次完成进度,并把已完成的大小、百分比和复制速度一并写到控制台上,当复制完成时,计算总的耗费时间,效果如图:

我们复制了一集1080p的权利的游戏第四季第7集,大概3.78G大小,由于使用了SSD,可以看到速度还是非常不错的,哈哈哈~
复制完成后,显示总花费时间
结合nodejs的readline, process.argv等模块,我们可以添加覆盖提示、强制覆盖、动态指定文件路径等完整的复制方法,有兴趣的可以实现一下,实现完成,可以
ln -s /path/to/copy.js /usr/local/bin/mycopy
这样就可以使用自己写的mycopy命令替代系统的cp命令
node.js流复制文件的更多相关文章
- node.js 递归复制文件夹(附带文件过滤功能)
1.简介: 很简单,写了一个node操作文件的小脚本,主要实现对目标文件夹中内容的复制.还顺带一个按照文件夹或者文件名过滤的功能. 2.应用场景 适合基于 node 环境的项目,项目打包的时候,配合 ...
- Node.js流
什么是流? 流是可以从一个源读取或写入数据到连续的目标对象.在Node.js,有四种类型的数据流. Readable - 其是用于读操作. Writable - 用在写操作. Duplex - 其可以 ...
- Java IO流之【缓冲流和文件流复制文件对比】
与文件流相比,缓冲流复制文件更快 代码: package Homework; import java.io.BufferedOutputStream; import java.io.File; imp ...
- JAVA通过I/O流复制文件
JAVA通过I/O流复制文件 本文是对字节流操作,可以多音频视频文件进行操作,亲测有效. 个人感觉这个东西就是靠记的, 没什么好解释的,,,, import java.io.File; import ...
- Java基础小知识1——分别使用字节流和字符流复制文件
在日常使用计算机过程中经常会涉及文件的复制,今天我们就从Java代码的角度,看看在Java程序中文件复制的过程是如何实现的. 1.使用字节流缓冲区复制文件 示例代码如下: import java.io ...
- 使用Node.JS监听文件夹变化
使用Node.JS监听文件夹改变有许多应用场合,比如: 构建自动编绎工具 当源文件改变时,自动运行build过程,比如当你写CoffeeScript文件或SASS CSS文件时,保存之后可即时生成对应 ...
- Java中字节流和字符流复制文件
字节流和字符流复制文件的过程: 1.建立两个流对象 绑定数据源和目的地 2.遍历出需复制的文件写入复制过后的新文件中(只不过是遍历的时候是区分字节和字符的) 3.访问结束后关闭资源 字节流复制文件: ...
- node.js编译less文件
大多数文章对于到底怎样编译less文件并没有一个详细的说明,清一色的grunt命令,看得也是晕晕的,所以也就有了这篇手记的存在. 步入正题 1.安装配置好sublime text3(包括各种实用插件) ...
- Java I/O流 复制文件速度对比
Java I/O流 复制文件速度对比 首先来说明如何使用Java的IO流实现文件的复制: 第一步肯定是要获取文件 这里使用字节流,一会我们会对视频进行复制(视频为非文本文件,故使用之) FileInp ...
随机推荐
- VS Code中编写html(4) 标签的宽高颜色背景设置
1 <!+Tab键--> <!--有两个div标签时,分别设置style,有两种方法--> <div id="div1">第一个div标签:& ...
- 路飞学城Python-Day113
107-HTTP协议的无状态保存 什么是无状态保存? HTTP无状态请求就是客户端每次发送的请求都是单独的新请求,每一次请求都是独立的,这样的特点在网站上就是服务器登录的时候记录浏览器的信息,建立 ...
- 序列模型(4)----门控循环单元(GRU)
一.GRU 其中, rt表示重置门,zt表示更新门. 重置门决定是否将之前的状态忘记.(作用相当于合并了 LSTM 中的遗忘门和传入门) 当rt趋于0的时候,前一个时刻的状态信息ht−1会被忘掉,隐藏 ...
- IOS:兼容ios6和低版本
viewDidUnload在ios6开始被弃用了,所以我们在这里处理内存警告的这类问题,这个时候我们就要把相应的处理放在 didReceiveMemoryWarning中. - (void)didRe ...
- 《黑白团团队》第八次团队作业:Alpha冲刺 第五天
项目 内容 作业课程地址 任课教师首页链接 作业要求 团队项目 填写团队名称 黑白团团队 填写具体目标 认真负责,完成项目 团队项目Github仓库地址链接. 第五天 日期:2019/6/19 成员 ...
- IIS部署ASP.NET网站后提示只有在配置文件或 Page 指令中将 enableSessionState 设置为 true 时,才能使用会话状态...
今天,在IIS上部署网站后,出现了下面错误: 只有在配置文件或 Page 指令中将 enableSessionState 设置为 true 时,才能使用会话状态.还请确保在应用程序配置的 <sy ...
- JavaScript(DOM编程三)
节点的移动,insertBefore <body> <p>你喜欢哪个城市?</p> <ul id="city"><li id= ...
- Jdk和Cglib 的区别
一.原理区别: java动态代理是利用反射机制生成一个实现代理接口的代理类,在调用具体方法前调用InvokeHandler来处理. 而cglib动态代理是利用asm开源包,对代理对象类的class文件 ...
- (0)前言【从零开始学Spring Boot】
在此对整体技术简单说明下. 开发工具和开发环境: Win7 64位操作 Eclipse-jee-mars-2-win32-x86_64 Jdk 1.8 Maven管理项目 如果要学习Spring Bo ...
- 多播 & multicast
参考: http://blog.csdn.net/herbert5069/article/details/31358641