python爬虫框架(1)--框架概述
框架概述
其中比较好用的是 Scrapy 和PySpider。pyspider上手更简单,操作更加简便,因为它增加了 WEB 界面,写爬虫迅速,集成了phantomjs,可以用来抓取js渲染的页面。Scrapy自定义程度高,比 PySpider更底层一些,适合学习研究,需要学习的相关知识多,不过自己拿来研究分布式和多线程等等是非常合适的。
PySpider
PySpider是binux做的一个爬虫架构的开源化实现。主要的功能需求是:
- 抓取、更新调度多站点的特定的页面
- 需要对页面进行结构化信息提取
- 灵活可扩展,稳定可监控
pyspider的设计基础是:以python脚本驱动的抓取环模型爬虫
- 通过python脚本进行结构化信息的提取,follow链接调度抓取控制,实现最大的灵活性
- 通过web化的脚本编写、调试环境。web展现调度状态
- 抓取环模型成熟稳定,模块间相互独立,通过消息队列连接,从单进程到多机分布式灵活拓展
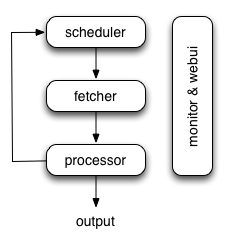
pyspider的架构主要分为 scheduler(调度器), fetcher(抓取器), processor(脚本执行):
- 各个组件间使用消息队列连接,除了scheduler是单点的,fetcher 和 processor 都是可以多实例分布式部署的。 scheduler 负责整体的调度控制
- 任务由 scheduler 发起调度,fetcher 抓取网页内容, processor 执行预先编写的python脚本,输出结果或产生新的提链任务(发往 scheduler),形成闭环。
- 每个脚本可以灵活使用各种python库对页面进行解析,使用框架API控制下一步抓取动作,通过设置回调控制解析动作。
Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试
Scrapy主要包括了以下组件:
- 引擎(Scrapy): 用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler): 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader): 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares): 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middewares): 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 首先,引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器,下载器把资源下载下来,并封装成应答包(Response)
- 然后,爬虫解析Response
- 若是解析出实体(Item),则交给实体管道进行进一步的处理。
- 若是解析出的是链接(URL),则把URL交给Scheduler等待抓取
python爬虫框架(1)--框架概述的更多相关文章
- Python爬虫之PySpider框架
概述 pyspider 是一个支持任务监控.项目管理.多种数据库,具有 WebUI 的爬虫框架,它采用 Python 语言编写,分布式架构.详细特性如下: 拥有 Web 脚本编辑界面,任务监控器,项目 ...
- python爬虫之scrapy框架
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
- 【转】Python爬虫(6)_scrapy框架
官网链接:https://docs.scrapy.org/en/latest/topics/architecture.html 性能相关 在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下 ...
- 适合新手练习的Python项目有哪些?Python爬虫用什么框架比较好?
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. Python爬虫一般用什么框架比较好?一般来讲,只有在遇到比较大型的需求时 ...
- (转)python爬虫----(scrapy框架提高(1),自定义Request爬取)
摘要 之前一直使用默认的parse入口,以及SgmlLinkExtractor自动抓取url.但是一般使用的时候都是需要自己写具体的url抓取函数的. python 爬虫 scrapy scrapy提 ...
- Python爬虫进阶(Scrapy框架爬虫)
准备工作: 配置环境问题什么的我昨天已经写了,那么今天直接安装三个库 首先第一步: ...
- python爬虫随笔-scrapy框架(1)——scrapy框架的安装和结构介绍
scrapy框架简介 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
- python爬虫之scrapy框架介绍
一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等) ...
- python爬虫中scrapy框架是否安装成功及简单创建
判断框架是否安装成功,在新建的爬虫文件夹下打开盘符中框输入cmd,在命令中输入scrapy,若显示如下图所示,则说明成功安装爬虫框架: 查看当前版本:在刚刚打开的命令框内输入scrapy versio ...
- python爬虫之Scrapy框架(CrawlSpider)
提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬去进行实现的(Request模块回调) 方法二:基于CrawlSpi ...
随机推荐
- MVC。
mvc 开启客户端 和 远程验证 <appSettings> <add key="ClientValidationEnabled" value="tru ...
- Ubuntu下使用tmux实现分屏,以及tmux快捷键
最近用到了终端的复用,使用了tmux,写一下自己的使用和一些快捷键. tmux是指通过一个终端登录远程主机并运行后,在其中可以开启多个控制台的终端复用软件. 来个效果图: 截图我使用的命令是 gno ...
- 15-THREE.JS 方向光
<!DOCTYPE html> <html> <head> <title></title> <script src="htt ...
- 【WCF】利用WCF实现上传下载文件服务
引言 前段时间,用WCF做了一个小项目,其中涉及到文件的上传下载.出于复习巩固的目的,今天简单梳理了一下,整理出来,下面展示如何一步步实现一个上传下载的WCF服务. 服务端 1.首先新建一个名 ...
- Git学习--版本回退
现在,你已经学会了修改文件,然后把修改提交到Git版本库,现在,再练习一次,修改readme.txt文件如下: Git is a distributed version control system. ...
- H5实现登录
1.主要就是获取cookie并每次发送请求时都带着:登录请求 2.添加HTTP Cookie管理器 3.登录请求时,加正则表达式提取器 取出返回的cookie ①使用charles抓包查看cookie ...
- BZOJ5302: [Haoi2018]奇怪的背包
BZOJ5302: [Haoi2018]奇怪的背包 https://lydsy.com/JudgeOnline/problem.php?id=5302 分析: 方程\(\sum\limits_{i=1 ...
- 西瓜书概念整理(chapter 1-2)熟悉机器学习术语
括号表示概念出现的其他页码, 如有兴趣协同整理,请到issue中认领章节 完整版见我的github:ahangchen 觉得还不错的话可以点个star ^_^ 第一章 绪论 Page2: 标记(lab ...
- NOIp2018集训test-10-24(am&pm)
李巨连续AK三场了,我跟南瓜打赌李巨连续AK七场,南瓜赌李巨连续AK五场. DAY1 T1 qu 按题意拿stack,queue和priority_que模拟即可.特判没有元素却要取出的情况. T2 ...
- RabbitMQ用户角色及权限控制(不错)
########################用户角色####################### RabbitMQ的用户角色分类:none.management.policymaker.moni ...