jsoup抓取网页内容
java项目有时候我们需要别人网页上的数据,怎么办?我们可以借助第三方架包jsou来实现,jsoup的中文文档,那怎么具体的实现呢?那就跟我一步一步来吧
最先肯定是要准备好这个第三方架包啦,下载地址,得到这个jar后在需要怎么做呢?别急,我们慢慢来
将jsoup.jar拷贝到项目的WebRoot—>WEB-INF—>lib文件夹
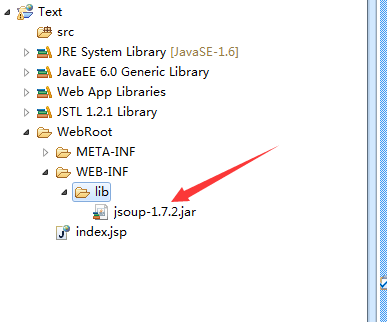 之后我们需要将这个架包引入一下哦!
之后我们需要将这个架包引入一下哦!
右键项目选择build path—>configure build path—>libraries—>add jars—>找到刚刚放入的目录下的jsoup



准备工作完成了,接下来就是我们的编码部分了,加油哦!
既然是抓取网页的内容那肯定首要有被抓的网站的地址,这里就以我其中一篇博客为准吧http://www.cnblogs.com/luhan/p/5953387.html
 这个是我这篇文章的截图,比如我要抓取Android零碎知识点,之后会一直更新哦这一段文字
这个是我这篇文章的截图,比如我要抓取Android零碎知识点,之后会一直更新哦这一段文字
//获取整个网站的根节点,也就是html开头部分一直到结束,这里get方式,post方式是一样的
Document document = Jsoup.connect(url).get();
//输出一下我们会看到整个字符串如下
System.out.println(document);
这里只是截图了一部分

我们会看到我们需要抓的那一段文字在a标签包裹在,而且还有一个重要的就是id=cb_post_title_url,看过文档的应该知道,jsoup里面有getElementById这个方法,其实跟js里面获取元素是一样的,这里我们就可以用
getElementById的方法来获取这个a标签,获取到后我们就可以获取里面的内容了不是吗?而正好jsou也给我们提供了这样的一个方法text()方法,就是获取标签的文本内容,记得是文本而不是html形式的
如下我们通过getElementById这个方法来获取到我们想要的a标签
Element a = document.getElementById("cb_post_title_url");
这时候我们输出的内容如下
System.out.println(a.text());
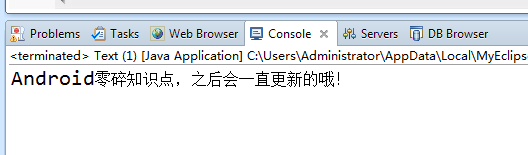
是不是得到了我们想要的了?当然啦,这只是jsoup的最简单的抓取而已,如果需要获取到的是个列表形式的啊,jsoup也一样可以的,我们都知道id是唯一的,不可以重复的,所以我们通过id获取到的只能是一行标签
但是一般列表比如ul-li我们就可以用getElementsByTag这个方法,通过标签名获取,然后再通过for循环的方式一个一个的去抓就完事啦,接下来附上代码
package com.luhan.text; import java.io.IOException; import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element; public class Text {
private static final String url = "http://www.cnblogs.com/luhan/p/5953387.html"; public static void main(String[] args) {
try {
//获取整个网站的根节点,也就是html开头部分一直到结束
Document document = Jsoup.connect(url).post();
Element a = document.getElementById("cb_post_title_url");
System.out.println(a.text());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
jsoup里面的方法我就不一一介绍啦,不懂的小伙伴可以去看jsoup的中文文档哦,我就说说比较重要的方法吧
Jsoup.connect(url).post();获取网页的跟目录
getElementById通过id来获取
getElementsByClass通过class来获取
getElementsByTag通过标签名称来获取
text()获取标签的文本,再次强调一下是文本
html()获取标签里面的所有字符串包括html标签
attr(attributeKey)获取属性里面的值,参数是属性名称
注意
jsoup获取网页的根目录可能跟源代码不一样,所以需要小伙伴们细心哦
至此jsoup抓取网页的数据就告一段落啦,说的不太好,欢迎大家多指点,这个我用java控制台的,javaweb以及Android用法是一样的,先要导入框架,然后调用方法就ok了
jsoup抓取网页内容的更多相关文章
- 使用Jsoup函数包抓取网页内容
之前写过一篇用Java抓取网页内容的文章,当时是用url.openStream()函数创建一个流,然后用BufferedReader把这个inputstream读取进来.抓取的结果是一整个字符串.如果 ...
- paip.抓取网页内容--java php python
paip.抓取网页内容--java php python.txt 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://blog ...
- Asp.Net 之 抓取网页内容
一.获取网页内容——html ASP.NET 中抓取网页内容是非常方便的,而其中更是解决了 ASP 中困扰我们的编码问题. 需要三个类:WebRequest.WebResponse.StreamRea ...
- ASP.NET抓取网页内容的实现方法
这篇文章主要介绍了ASP.NET抓取网页内容的实现方法,涉及使用HttpWebRequest及WebResponse抓取网页内容的技巧,需要的朋友可以参考下 一.ASP.NET 使用HttpWebRe ...
- ASP.NET抓取网页内容
原文:ASP.NET抓取网页内容 一.ASP.NET 使用HttpWebRequest抓取网页内容 这种方式抓取某些页面会失败 不过,有时候我们会发现,这个程序在抓取某些页面时,是获不到所需的内容的, ...
- c#抓取网页内容乱码的解决方案
写过爬虫的同学都知道,这是个很常见的问题了,一般处理思路是: 使用HttpWebRequest发送请求,HttpWebResponse来接收,判断HttpWebResponse中”Content-Ty ...
- C# 抓取网页内容的方法
1.抓取一般内容 需要三个类:WebRequest.WebResponse.StreamReader 所需命名空间:System.Net.System.IO 核心代码: view plaincopy ...
- ASP.NET 抓取网页内容
(转)ASP.NET 抓取网页内容 ASP.NET 抓取网页内容-文字 ASP.NET 中抓取网页内容是非常方便的,而其中更是解决了 ASP 中困扰我们的编码问题. 需要三个类:WebRequest. ...
- 爬虫学习一系列:urllib2抓取网页内容
爬虫学习一系列:urllib2抓取网页内容 所谓网页抓取,就是把URL地址中指定的网络资源从网络中读取出来,保存到本地.我们平时在浏览器中通过网址浏览网页,只不过我们看到的是解析过的页面效果,而通过程 ...
随机推荐
- 搭建属于你的家庭网络实时监控–HTML5在嵌入式系统中的应用·高级篇
*本文已刊登在<无线电>2014年第6期 <搭建属于你的在线实时採集系统>中已经对HTML5平台有了初步的认识,并基于此向大家展示了怎样将採集到的数据上传至网络.实现实时观測. ...
- idea各种设置和学习
1. 去掉方法中的参数名提示 idea在Review时候的编码设置 idea在review代码的时候会会出现中文乱码,文件是GBK的,但是idea的字符集和项目的字符集都是UTF-8, 这时可以通过把 ...
- windows 下 Rabbitmq 配置远程访问
1.运行-->CMD 2.定位到Rabbitmq 安装路径下的 sbin目录,执行 :rabbitmq-plugins enable rabbitmq_management 3.登录web控制台 ...
- RabbitMQ集群安装配置+HAproxy+Keepalived高可用
RabbitMQ集群安装配置+HAproxy+Keepalived高可用 转自:https://www.linuxidc.com/Linux/2016-10/136492.htm rabbitmq 集 ...
- java心跳发送
java心跳发送: 大家都知道.如果你在互联网公司,并且开发的是产品那你一定接触不到.心跳机制.心跳包 那什么是心跳机制呢? 心跳机制就是定时发送一个自定义的结构体(心跳包).确保连接的有效的机制. ...
- Python中使用 Selenium 实现网页截图实例
Selenium 是一个可以让浏览器自动化地执行一系列任务的工具,常用于自动化测试.不过,也可以用来给网页截图.目前,它支持 Java.C#.Ruby 以及 Python 四种客户端语言.如果你使用 ...
- java 经典范例
使用for 循环输出空心菱形 package 开阳; import java.util.Scanner; public class image { public static void main(St ...
- 让WebRTC支持H264编解码
近期实验了下怎样让WebRTC支持H264编码.记录下,供有须要的人參考. 说明一下,我是在 Ubuntu Server 14.04 下编译的 WebRTC ,使用 native(C++) api 开 ...
- obj-c学习笔记
本文转载至 http://blog.csdn.net/c395565746c/article/details/7573793 当对象经过在dealloc方法处理时,该对象就已经处于已销毁状态,其它 ...
- ios推送服务,php服务端
本文转载至http://my.oschina.net/AStar/blog/176531 生成证书 证书生成参考:https://parse.com/tutorials/ios-push-noti ...