[Math Review] Statistics Basic: Estimation
Two Types of Estimation
- Point Estimate: the value of sample statistics
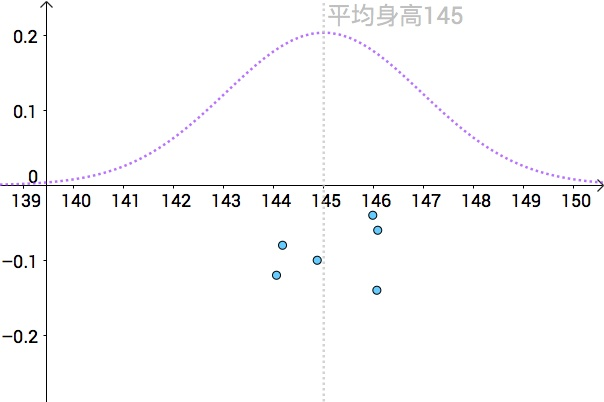
Point estimates of average height with multiple samples (Source: Zhihu)
- Confidence Intervals: intervals constructed using a method that contains the population parameter a specified proportion of the time.
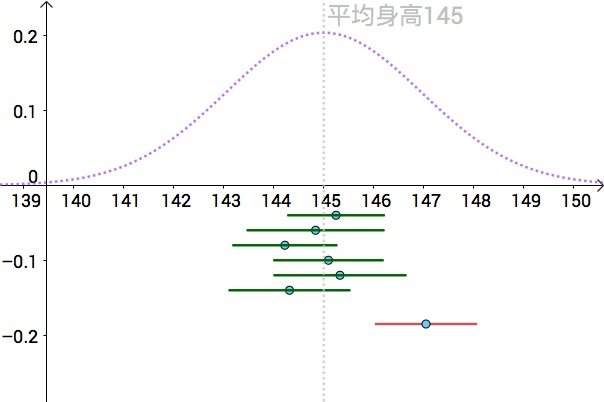
95% confidence interval of average height with multiple samples (Source: Zhihu)
Confidence Interval for the Mean
Population Variance is known
Suppose that M is the mean of N samples X1, X2, ......, Xn, i.e.

According to Central Limit Theorem, the the sampling distribution of the mean M is
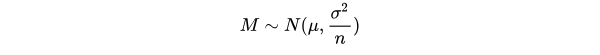
where μ and σ2 are the mean and variance of the population respectively. If repeated samples were taken and the 95% confidence interval computed for each sample, 95% of the intervals would contain the population mean. So the 95% confidence interval for M is the inverval that is symetric about the point estimate μ so that the area under normal distribution is 0.95.
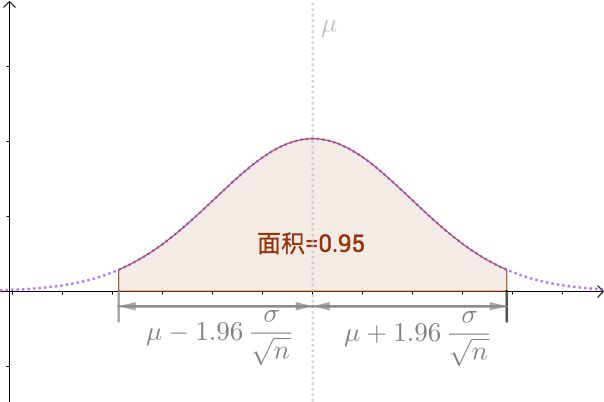
That is,
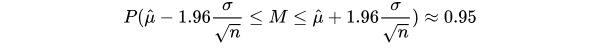
Since we don't know the mean of population, we could use the sample mean instead.
Population Variance is Unknown
Dregree of Freedom
The degrees of freedom (df) of an estimate is the number of independent pieces of information on which the estimate is based. In general, the degrees of freedom for an estimate is equal to the number of values minus the number of parameters estimated en route to the estimate in question.
If the variance in a sample is used to estimate the variance in a population, we couldn't calculate the sample variace as
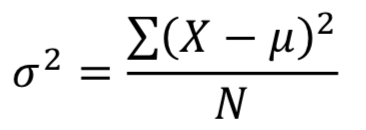
That's because we have two parameters to estimate (i.e., sample mean and sample variance). The degree of freedom should be N-1, so the previous formula underestimates the variance. Instead, we should use the following formula
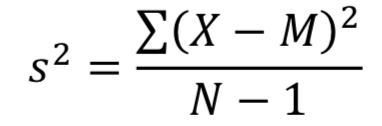
where s2 is the estimate of the variance and M is the sample mean. The denominator of this formula is the degree of freedom.
Student's t-Distribution
Suppose that X is a random variable of normal distribution, i.e., X ~ N(μ, σ2)
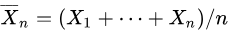
is sample mean and
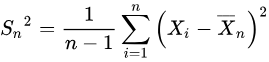
is sample deviation.
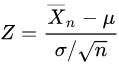
is a random variable of normal distribution.
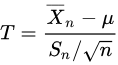
is a random variable of student's t distribution.
The probability density function of T is
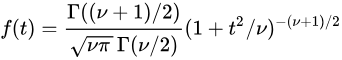
where 

The t distribution is very similar to the normal distribution when the estimate of variance is based on many degrees of freedom, but has relatively more scores in its tails when there are fewer degrees of freedom. Here are t distributions with 2, 4, and 10 degrees of freedom and the standard normal distribution. Notice that the normal distribution has relatively more scores in the center of the distribution and the t distribution has relatively more in the tails.
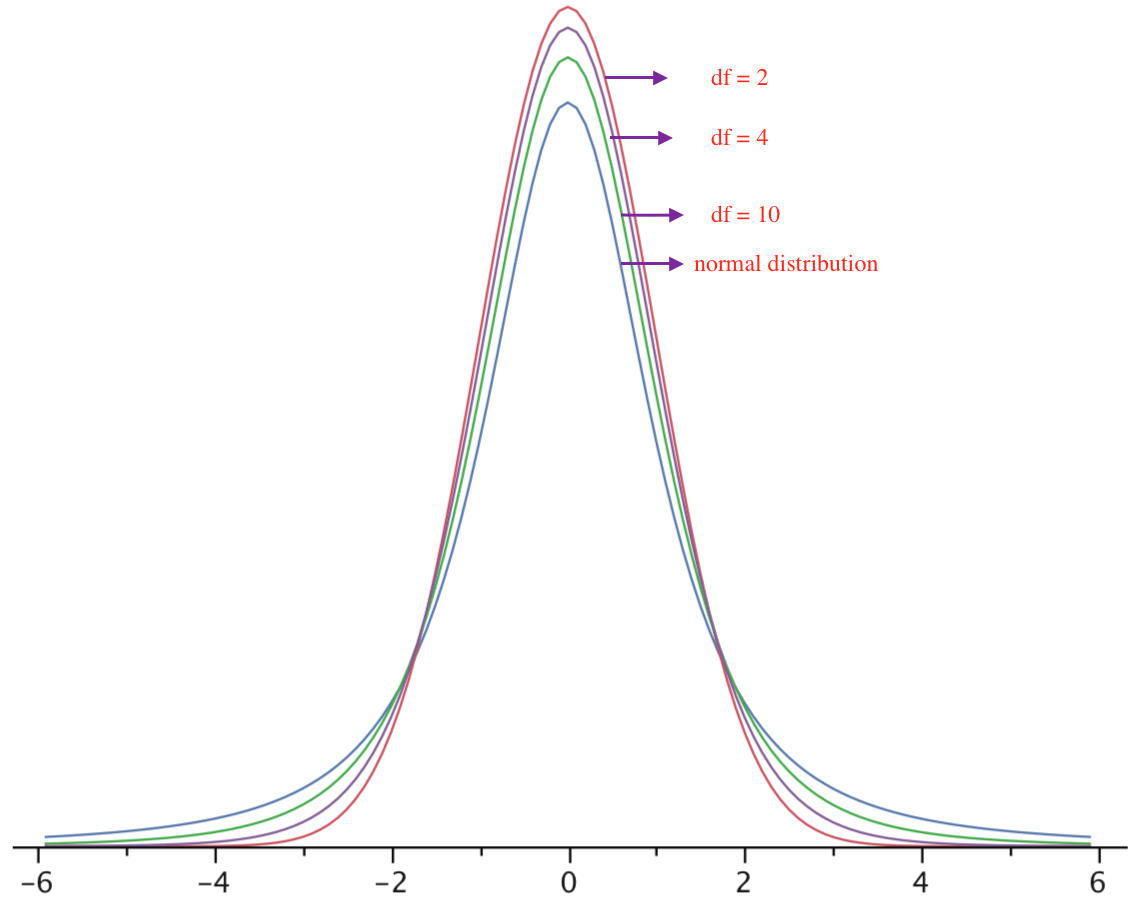
The t distribution is therefore leptokurtic. The t distribution approaches the normal distribution as the degrees of freedom increase.
Confidence Interval of t Distribution
Now consider the case in which you have a normal distribution but you do not know the standard deviation. You sample N values and compute the sample mean (M) and estimate the standard error of the mean (σM) with sM. What is the probability that M will be within 1.96 sM of the population mean (μ)? This is a difficult problem because there are two ways in which M could be more than 1.96 sM from μ: (1) M could, by chance, be either very high or very low and (2) sM could, by chance, be very low. Intuitively, it makes sense that the probability of being within 1.96 standard errors of the mean should be smaller than in the case when the standard deviation is known (and cannot be underestimated).
Luckily, however, we can prove that random variable T will be student's t distribution. So we can use t distribution to estimate the mean of a normal distribution population in situations where the sample size is small and population standard deviation is unknown. For 90% confidence interval, it can be calculated as
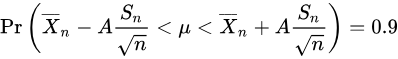
where A is value of T that contains 90% of the area of the t distribution for n-1 degree of freedom. We can calculate A through the t table.
[Math Review] Statistics Basic: Estimation的更多相关文章
- [Math Review] Statistics Basic: Sampling Distribution
Inferential Statistics Generalizing from a sample to a population that involves determining how far ...
- [Math Review] Statistics Basics: Main Concepts in Hypothesis Testing
Case Study The case study Physicians' Reactions sought to determine whether physicians spend less ti ...
- [Math Review] Linear Algebra for Singular Value Decomposition (SVD)
Matrix and Determinant Let C be an M × N matrix with real-valued entries, i.e. C={cij}mxn Determinan ...
- 统计处理包Statsmodels: statistics in python
http://blog.csdn.net/pipisorry/article/details/52227580 Statsmodels Statsmodels is a Python package ...
- FAQ: Automatic Statistics Collection (文档 ID 1233203.1)
In this Document Purpose Questions and Answers What kind of statistics do the Automated tasks ...
- Machine and Deep Learning with Python
Machine and Deep Learning with Python Education Tutorials and courses Supervised learning superstiti ...
- How do I learn machine learning?
https://www.quora.com/How-do-I-learn-machine-learning-1?redirected_qid=6578644 How Can I Learn X? ...
- 本人AI知识体系导航 - AI menu
Relevant Readable Links Name Interesting topic Comment Edwin Chen 非参贝叶斯 徐亦达老板 Dirichlet Process 学习 ...
- [book]awesome-machine-learning books
https://github.com/josephmisiti/awesome-machine-learning/blob/master/books.md Machine-Learning / Dat ...
随机推荐
- WPF调用摄像头
添加程序集:WPFMediaKit.dll 更关键代码如下: 界面设计代码如下: <Window x:Class="摄像头调用.MainWindow" xmlns=" ...
- ASP.NET Core ---异常处理
一.局部异常处理: 在Action里面catch 二.全局异常处理: 1.默认的异常处理配置: 默认配置在StartUp文件的Configure中注册错误处理,显示开发者错误页面: public vo ...
- (原、整)Unreal源码 CoreUbject- Uobject
(原.整) Unreal源码 CoreUbject- Uobject 类别 [随笔分类]Unreal源码搬山 @author:白袍小道 随缘那啥 这里还是属于UE ...
- (转)Unreal Shader模块(四): 着色器编译
本文为(转):Unreal 调试着色器编译过程 调试着色器编译过程 Rolando Caloca 在 April 19, 2016 | 学习编程 Share on Facebook Shar ...
- shit vue-cli & path bug & baseUrl bug
vue-cli path bug https://cli.vuejs.org/zh/guide/#cli baseUrl bug baseUrl: "././" , https:/ ...
- BZOJ2208 [Jsoi2010]连通数 【图的遍历】
题目 输入格式 输入数据第一行是图顶点的数量,一个正整数N. 接下来N行,每行N个字符.第i行第j列的1表示顶点i到j有边,0则表示无边. 输出格式 输出一行一个整数,表示该图的连通数. 输入样例 3 ...
- 洛谷 P4008 [NOI2003]文本编辑器 解题报告
P4008 [NOI2003]文本编辑器 题目描述 很久很久以前,\(DOS3.x\)的程序员们开始对 \(EDLIN\) 感到厌倦.于是,人们开始纷纷改用自己写的文本编辑器⋯⋯ 多年之后,出于偶然的 ...
- js常用数组去重
// ES6 function unique (arr){ const seen = new Map() return arr.filter((a) => !seen.has(a) && ...
- Vue组件中的单项数据流
当子组件中的input v-model 父组件的值时不能直接绑定props的值要使用计算属性,向下面的写法,因为props是单项数据流,子组件不能改变父组件的状态,直接绑定会报错. 还可以这样写:但是 ...
- linux后端跑redis
http://blog.csdn.net/ksdb0468473/article/details/52126009